生成式人工智能和聊天GPT的自然语言处理起源

到现在为止,你可能已经听说过ChatGPT,以及围绕它的不同意见——有人喜欢它,有人讨厌它,也有人害怕它。它可以生成巧克力片饼干的食谱,写一首关于你孩子的百老汇风格的歌曲,还能创造可用的代码。
加入这场有趣的活动,我们使用ChatGPT帮助我们探索了过去50年人工智能的一些关键创新。
1966年:伊丽莎
在1966年,名为ELIZA的聊天机器人席卷了计算机科学界。ELIZA是由麻省理工学院人工智能实验室的约瑟夫·魏岑鲍姆(Joseph Weizenbaum)建造的,旨在模仿罗杰斯(Rogerian)心理治疗师。罗杰斯心理治疗师是无指导性但支持性的,因此他们经常反映患者所说的话。 ELIZA使用模式匹配--想想正则表达式和字符串替换-来实现这个目标。您可以通过点击下面的图片来尝试ELIZA。
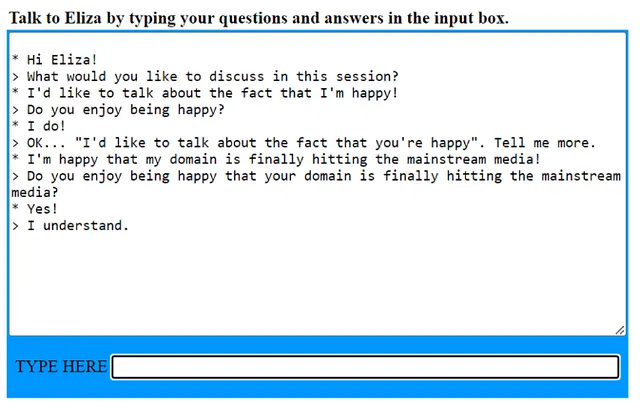
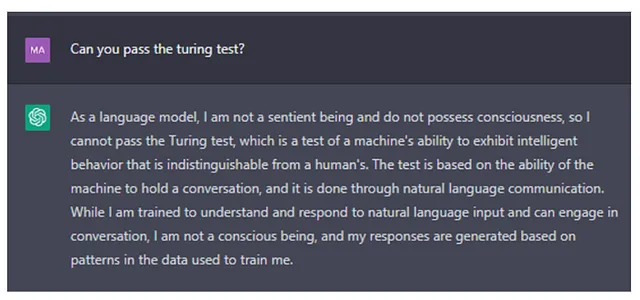
ELIZA是初级的,但感觉真实可信,对于聊天机器人来说是一个惊人的飞跃。因为它是最早设计的聊天机器人之一,也是最早能尝试图灵测试的程序之一。 图灵测试是一种模拟游戏,测试机器展示像人类一样的智能行为的能力。当询问ChatGPT它是否能通过图灵测试时,它会回复以下内容:
1970年代 - 1990年代
对于非结构化文本数据分析的提炼方法继续进化。70年代引入了喇叭裤、案例语法、语义网络和概念依赖理论。80年代出现了蓬松的发型、时尚、本体论和专家系统(如化学分析的DENDRAL)。90年代出现了垃圾摇滚、统计模型、循环神经网络和长短时记忆模型(LSTM)。
2000年至2015年
新千年带给我们低腰牛仔裤、卡车司机帽,以及语言建模、单词嵌入和 Google 翻译的更大的进展。然而,过去的 12 年是自然语言处理领域发生重大魔术的时期。Word2Vec,编码器-解码器模型,注意力和变压器模型,预训练模型以及迁移学习模型铺平了现在所看到的道路 - GPT和大型语言模型,可以处理数十亿个参数。
2015年以及以后 - Word2vec,GloVe和FASTTEXT
Word2vec,GloVe和FASTTEXT专注于词嵌入或词向量化。 词向量化是一种NLP方法,用于将词汇表中的单词或短语映射到相应的实数向量,以查找单词预测和单词相似性或语义。 词向量化背后的基本思想是具有相似含义的单词将具有类似的向量表示。
Word2vec是最常见的词向量化方法之一。它使用神经网络从大型文本语料库中学习单词的向量表示。向量的学习方式是使在类似语境中使用的单词具有相似的向量表示。例如,“cat”和“dog”的向量会不同,但是“cat”和“kitten”的向量会相似。
另一种用于创建单词向量的技术称为GloVe(全局单词向量表示)。GloVe使用与word2vec不同的方法,通过训练共现矩阵来学习单词向量。
一旦一组单词向量被学习后,它们可以用于各种自然语言处理(NLP)任务,如文本分类、语言翻译和问题回答。
2017 变形金刚模型
变压器模型是由谷歌研究人员在名为“注意力全在于你”的2017年论文中引入的,真正革命了我们使用机器学习分析非结构化数据的方式。
在变换器模型中,自我注意机制的使用是关键创新之一,它允许模型在进行预测时权衡输入的不同部分的重要性。这使得模型能够更好地处理输入中的长期依赖性,尤其是在语言翻译等任务中,一个单词的含义可能取决于在句子中出现很多个单词之前的单词。变换器模型的另一个重要特征是多头注意力的使用,它允许模型同时关注输入的不同部分,而不是依次进行。这使得模型更加高效,因为它可以并行处理输入,而不必一步步地处理它。
ELMo
ELMo简介
ELMo(语言模型嵌入)不是一个变换器模型 - 它是双向LSTM模型。双向LSTM是一种循环神经网络(RNN),可以在正向和反向方向处理输入序列,从序列中捕获过去和未来单词的上下文信息。在ELMo中,通过对大量文本数据训练双向LSTM网络,生成能够捕捉单词在上下文中丰富语义和句法信息的上下文敏感词嵌入。这有助于处理歧义,尤其是多义性。多义性是指一个单词在不同的上下文中可以有不同的意义。例如,“银行”就是多义词。“银行”可能指河岸或储蓄银行。ELMo可以帮助解码应该采用哪个意思,因为它能更好地管理上下文中的单词。正是这种在上下文中管理单词的能力,使得ELMo相比单纯考虑袋装单词的向量意思模型,如word2vect和GloVe,有了巨大的提升。
BERT
BERT使用基于Transformer的架构,它能够有效地处理更长的输入序列,并从词或标记的左右两侧捕捉上下文信息(BERT中的B代表双向)。另一方面,ELMo使用循环神经网络(RNN)架构,它在处理更长的输入序列方面不太有效。
BERT是在大量文本数据上进行预训练的,可以在特定任务(例如问答和情感分析)上进行微调。另一方面,ELMo仅在较少量的文本数据上进行预训练,并没有进行微调。
BERT也使用了遮蔽语言模型目标,随机遮蔽了输入中的一些标记,然后训练模型以预测遮蔽标记的原始值。这使BERT能够学习单词出现上下文的更深层次含义。另一方面,ELMo只使用了下一个单词预测目标。
-3是一种使用深度学习的人工智能模型,由OpenAI公司开发。它能够完成文本生成、问答、语言翻译等任务,并拥有非常强大的语言模型。 GPT-3 is an artificial intelligence model that uses deep learning, developed by OpenAI company. It can complete tasks such as text generation, question answering, language translation, and has a very powerful language model.
GPT或生成预训练模型与BERT一同进入市场,并为不同目的而设计。BERT的设计目的是理解句子的含义。GPT模型旨在生成文本。GPT模型是通用语言模型,已经在大量文本数据上进行了训练,以执行各种NLP任务,如文本生成、翻译、摘要等等。
GPT-1(2018)
这是第一个GPT模型,它是通过从互联网上收集的大量文本数据进行训练的。它拥有1.17亿个参数,能够生成与训练数据中风格和内容非常相似的文本。
GPT-2(2019)
这个模型比GPT-1还要大,拥有15亿个参数,并且是在更大的文本数据语料库上进行训练的。这个模型能够生成比它的前身更为连贯和接近人类的文本。
GPT-3(2020)
这是最新、最大的 GPT 通用模型,包括 1750 亿个参数。它在更大的文本数据语料库上进行了训练,可以以人类水平的表现执行各种自然语言处理任务,例如翻译、问答和摘要。
GPT-3.5 或 ChatGPT (2022)
ChatGPT 也被称为 GPT-3.5,是对 GPT 模型的稍有不同的改进。它是一种会话型人工智能模型,已经针对与会话人工智能有关的任务进行了优化,例如回答问题,虽然不总是真实的。ChatGPT 已经在更侧重于对话数据的较小数据集上进行了训练,这使得它能够生成与 GPT-3 相比更相关和上下文感知的响应。
谷歌巴德
Google在2023年2月6日宣布了他们的对话式搜索方法Bard,紧随其后,微软宣布他们将把ChatGPT纳入Bing。看起来未来将是对话式的,人们将寻求改善他们的答案引擎优化而不是传统的搜索引擎优化。随着OpenAI现在提供了带有GPT-4的ChatGPT Plus,这个领域在不断地发展。
我们正处在生成 AI 和自然语言处理领域的巨大进步之中,但您必须意识到并确保您正在消费的信息是准确的。每天都在探索新的技术和技巧。了解更多关于我们的分析和机器学习平台,并在今天免费尝试。
更多资源:
- 看看这本关于自然语言处理的电子书- 深入探索这本关于增强型商业智能的电子书
由玛丽·奥斯本和阿里·迪克森共同撰写