使用GPT-4引导标签化
一种经济实惠的数据标注方法
数据标注是机器学习项目中至关重要的组成部分。它建立在老话“垃圾进垃圾出”的基础上。标注涉及创建用于训练和评估的注释数据集。但这个过程可能会非常耗时和昂贵,特别是对于数据量巨大的项目而言。但是,如果我们可以利用LLM的进展来减少数据标注任务涉及的成本和工作量的话,那么会怎样呢?
GPT-4是由OpenAI开发的最先进的语言模型。它具有remarkable ability to understand and generate human-like text,已经成为了自然语言处理(NLP)社区及其它领域的游戏变革者。在本博客文章中,我们将探讨如何使用GPT-4来启动各种任务的标签。这可以显著降低标记过程的时间和成本。我们将重点介绍情感分类,以展示如何使用prompt engineering来使用GPT-4创建准确可靠的标签,并且如何将此技术用于更强大的事物上。
利用GPT-4的预测进行数据预标记
在写作中,修改常常比创作原文辛苦少了。这就是为什么使用预先标记的数据比使用空白板更有吸引力的原因。利用GPT-4作为预测引擎来预先标记数据,是因为它具有理解上下文和生成类似人类文本的能力。因此,利用GPT-4来减少数据标记所需的人工工作量是很好的选择。这可以节省成本,使标注过程变得不那么乏味。
那么我们该怎么做呢?如果您已经使用了 GPT 模型,您可能已经熟悉提示。提示为模型设置上下文,让它在开始生成输出之前进行调整和工程处理(即提示工程),以帮助模型提供高度特定的结果。这意味着我们可以创建提示,供 GPT-4 使用,生成看起来像模型预测的文本。对于我们的用例,我们将以一种引导模型产生所需输出格式的方式来制作我们的提示。
让我们以情感分析为例进行简单说明。如果我们正在尝试将一个给定的文本字符串的情感分类为积极的、消极的或中性的,我们可以提供以下提示:
"Classify the sentiment of the following text as 'positive', 'negative', or 'neutral': <input_text>"一旦我们有了良好结构的提示,我们可以使用OpenAI API 从GPT-4生成预测。以下是使用Python的示例:
import openai
import re
openai.api_key = "<your_api_key>"
def get_sentiment(input_text):
prompt = f"Respond in the json format: {{'response': sentiment_classification}}\nText: {input_text}\nSentiment (positive, neutral, negative):"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
],
max_tokens=40,
n=1,
stop=None,
temperature=0.5,
)
response_text = response.choices[0].message['content'].strip()
sentiment = re.search("negative|neutral|positive", response_text).group(0)
# Add input_text back in for the result
return {"text": input_text, "response": sentiment}我们可以使用单个示例来检查从API接收到的输出。
# Test single example
sample_text = "I had a terrible time at the party last night!"
sentiment = get_sentiment(sample_text)
print("Result\n",f"{sentiment}")Result:
{'text': 'I had a terrible time at the party last night!', 'response': 'negative'}一旦我们对提示和结果感到满意,就可以将其扩展到整个数据集。在这里,我们假设有一个文本文件,每行有一个示例。
import json
input_file_path = "input_texts.txt"
output_file_path = "output_responses.json"
with open(input_file_path, "r") as input_file, open(output_file_path, "w") as output_file:
examples = []
for line in input_file:
text = line.strip()
if text:
examples.append(convert_ls_format(get_sentiment(text)))
output_file.write(json.dumps(examples))我们可以将带有预标注预测数据导入到Label Studio中,让评审员验证或更正标签。这种方法可以显著减少数据标记所需的手动工作,因为人类评审员只需要验证或更正模型生成的标签,而不必从头注释整个数据集。在这里查看我们的完整示例笔记本。
请注意,在大多数情况下,OpenAI 可以使用发送到他们的 API 的任何信息来进一步训练他们的模型。因此,如果我们不想广泛暴露信息,重要的是不要将受保护或私人数据发送到这些 API 中进行标注。
在Label Studio中审查预标记数据
一旦我们准备好预先标记的数据,我们将把它导入到数据标记工具中,例如 Label Studio,进行审核。本节将指导您设置 Label Studio 项目、导入预先标记的数据并审核注释。
步骤1:安装并启动Label Studio。
首先,您需要在您的计算机上安装Label Studio。您可以使用pip进行安装:
pip install label-studio安装Label Studio之后,通过运行以下命令启动它:
label-studio这将在您的默认网络浏览器中打开Label Studio。
步骤2:创建一个新的项目
单击“创建项目”并输入项目名称,例如“审核引导标签”。接下来,您需要定义标签配置。对于情感分析,我们可以使用文本情感分析文本分类。
这些模板是可配置的,因此如果我们想更改其中的任何属性,那非常简单。默认标签配置如下所示。
<View>
<Header value="Choose text sentiment:"/>
<Text name="my_text" value="$reviewText"/>
<Choices name="sentiment" toName="my_text" choice="single" showInline="true">
<Choice value="Positive"/>
<Choice value="Negative"/>
<Choice value="Neutral"/>
</Choices>
</View>点击“创建”完成项目设置。
步骤三:导入预标记数据
为导入预先标记的数据,请单击“导入”按钮。选择json文件并选择先前生成的预标记数据文件(例如,“output_responses.json”)。数据将与预填充的预测一起导入。
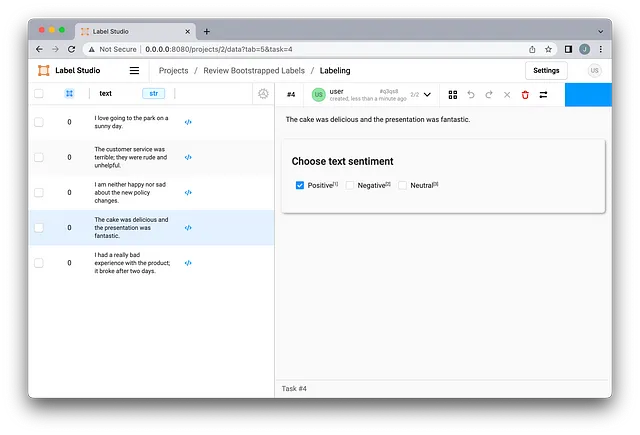
步骤四:审核和更新标签。
导入数据后,您可以查看模型生成的标签。注释界面将显示每个文本样本的预标记情感,并且评论者可以接受或更正建议的标签。
你可以让多个标注员查看每个例子,进一步提高质量。
通过利用GPT-4生成的标签作为起点,审核过程变得更加高效,审核者可以专注于验证或纠正标注,而不是从头创建它们。
步骤5:导出标注数据
一旦审核流程完成,您可以通过单击“数据管理器”选项卡中的“导出”按钮来导出标记数据。选择所需的输出格式(例如,JSON,CSV或TSV),并保存标记数据集以供在机器学习项目中进一步使用。