通过ChatGPT引导“OG”文本分类器:求职者筛选
介绍
我们已经消除了数字鸿沟。每个人都是程序员。现在,你只需要对计算机说话。这台计算机不在乎你如何编程它,它会尽力理解你的意思,因为它具有令人难以置信的大型语言模型能力。因此,编程障碍非常低。
— Nvidia首席执行官黄仁勋,2023年5月29日
大型语言模型(LLMs)无疑是自然语言处理领域的一次革命性变革。历史上,开发成功的语言系统的主要障碍之一就是从野外收集足够的特定领域的训练样本(POS、NER、文本分类、蕴含、问答等)来完成一个任务。对于处理敏感、小众或专有数据的商业项目来说,这一点尤其重要,这些数据不易于进行大规模的互联网爬取。
LLMs可以利用prompt中的few-shot learning在最少的训练数据下取得惊人的结果。然而,部署低延迟、高吞吐量、定制调整模型会给中小型企业带来许多DevOps/MLOps挑战。从业人员必须了解各种先进技术,包括模型架构选择、多GPU训练以及用于快速服务的模型压缩。在这些领域做出不良决策可能导致过高的云成本、高延迟或模型性能不佳。
幸运的是,我们可以利用LLMs的强大功能来启动轻量级的“传统”NLP模型,这些模型的训练和生产化相对较便宜,并且具有更高的模型可解释性。
在接下来的章节中,我们将创建ChatGPT生成的合成训练示例,构建一个混合系统,其中一个小型文本嵌入编码器提供轻量级支持向量机(SVM)分类器,以预测求职者的简历类别。
说明性例子:简历分类
假设你是一家知名初创企业的人力资源部门。这是你第一次在获得资金后聘请高级DevOps工程师。你刚刚收到成千上万份该职位的简历,想要利用人工智能进行第一轮快速筛选,排除非DevOps候选人。
你应该怎么做?(记住你现有的标记训练数据很少)。
启动分类器的假设方法:
角色. 使用ChatGPT REST API,为高级DevOps角色和非DevOps角色创建10,000个平衡的合成简历训练示例,使用真实案例作为种子。每个简历将带有DevOps / non-DevOps标签[0,1]。
II. 将原始的训练样例通过一个小型文本嵌入模型 (例如 Hugging Face 的句子转换器) 进行转换,以获取捕获文本中抽象意义的嵌入特征向量。接着将这些嵌入向量提供给下游的经典二元分类器,例如 SVM 或逻辑回归模型进行训练。
一、创建合成训练样本:
以下是一些起始脚手架代码和提示,您可以通过ChatGPT生成人造培训数据简历。请注意,这些提示和代码都未经过优化,仅用于说明目的。在构建培训数据生成脚本时,请考虑以下一些高级细节:
- 进行有效的工程试验,确保您生成现实的训练示例(请参阅此优秀指南)。
- 使用多线程方法进行并发请求OpenAI,同时遵守速率限制和令牌配额,以便及时返回足够的训练样例。
- 为避免由于事故而丢失进程,将中间结果附加到输出JSONL中并通过进程锁定避免竞态条件是很有帮助的。
- 定期对结果进行随机抽样和探索性数据分析,以检查简历的分布和质量。如果不满意,可以尝试不同的提示或应用后处理遮罩清理训练数据。
简历生成器初始代码
import openai
from datetime import datetime
import fcntl
import json
import time
from multiprocessing import Pool
openai.api_key = "YOUR_API_KEY"
DEVOPS_PROMPT= """
Please generate a Senior DevOps Resume while respecting the following criteria:
- make it as realistic as possible
- make sure to include relevant DevOps and Software Development Skills
- make sure they have at least 3 years of work experience
Return a JSON where the key is 0 \n
and the value is the raw resume text
"""
NON_DEVOPS_PROMPT= """
Please generate a resume in any field exepct DevOps while respecting the following criteria:
- make it is as realistic as possible
- make sure it contains nothing in the way of DevOps and \n
Software Development Skills
Return a JSON where the key for the is 1 \n
and the value is the raw resume
"""
def _write_to_jsonl(examples: str, output_file: str):
"""
Append intermediate request results to a JSONL
lock the file to avoid race conditions
"""
with open(output_file, "a") as f:
# Acquire an exclusive lock on the file
fcntl.flock(f, fcntl.LOCK_EX)
for example in examples:
json_string = json.dumps(example)
f.write(json_string + "\n")
fcntl.flock(f, fcntl.LOCK_UN)
def _open_ai_request(prompt: str, max_tokens: str, output_path: str):
"""
Make an OPENAI ChatGPT request
"""
print("Starting Open AI Request")
try:
res = openai.ChatCompletion.create(
max_tokens=max_tokens,
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt},
],
)
if raw_str := res["choices"][0]["message"]["content"]:
examples = [{0: raw_str}]
print(examples)
print("\n")
_write_to_jsonl(examples, output_path)
except Exception as e:
print(e)
return None
def open_ai_requests_min(prompt: str,
max_tokens: int,
threads: int,
output_path: str):
"""
Batch of requests made in a minute.
"""
start_time = time.time()
with Pool(processes=threads) as pool:
pool.starmap(_open_ai_request, [(prompt, max_tokens, output_path)] * threads)
while time.time() - start_time < 60:
time.sleep(1)
print("sleeping...")
if __name__ == "__main__":
TPM = 90_000
RPM = 3_500
MAX_TOKENS = 1_000
THREADS_MIN = 100
MINUTES = 120
# Generate DevOps Resumes
for i in range(MINUTES):
OUTPUT_PATH = "./training/devops_resumes.jsonl"
print(f"Starting Batch for Minute {i}")
open_ai_requests_min(DEVOPS_PROMPT, MAX_TOKENS, THREADS_MIN, OUTPUT_PATH)
# Non DevOps Resumes
for i in range(MINUTES):
OUTPUT_PATH = "./training/non_devops_resumes.jsonl"
print(f"Starting Batch for Minute {i}")
open_ai_requests_min(NON_DEVOPS_PROMPT, MAX_TOKENS, THREADS_MIN, OUTPUT_PATH)II. 嵌入和训练:
接下来,我们将利用Hugging Face提供的轻量级文本嵌入变换器。在这种情况下,我们选择了全迷你LM-L6-v2,它有以下优点:
- 速度:在V100 GPU上,每秒可处理14,200个句子。
- 小尺寸:仅80mb!
- 多功能性:经过10亿多个文本对的训练。
- 令牌窗口:256个词片段(大约相当于2/3页的文本)
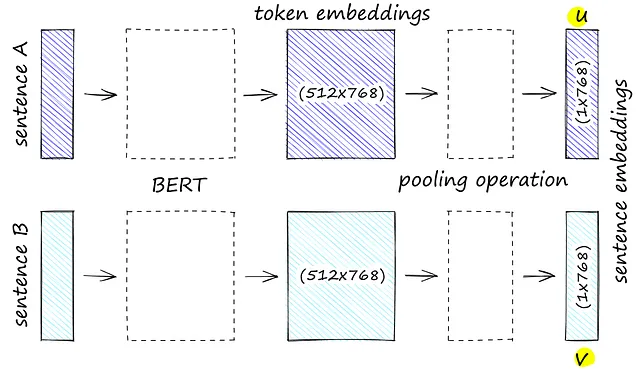
在嵌入我们的训练数据后,我们已经准备好为我们的二分类任务训练SVM。这超出了本文的范围,但SVM非常适合高维空间,因为它们可以通过最大化类之间的间隔来有效地找到决策边界,即使在复杂和非线性特征空间中也是如此。我们的嵌入向量长度约为700个浮点数,因此选择这种分类器是一个很好的基准。
如果在约20,000个训练示例上训练,像下面这样的SVM通常会序列化为约100mb的模型,比多GB的LLM体积更小且更适合生产!
快乐建造!
嵌入/训练入门代码
import pandas as pd
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.utils import resample
from sentence_transformers import SentenceTransformer, util
import pickle
def _get_embeddings(embed=True) -> pd.DataFrame:
"""
Get and serialize our embeddings, preload previous embeddings
if embed set to False
"""
print("Getting Embeddings")
toc_path = "./training/devops_embeddings.pkl"
bt_path = "./training/non_devops_embeddings.pkl"
if embed:
model = SentenceTransformer("all-MiniLM-L6-v2")
devops_df = pd.read_json("./training/devops_embeddings.jsonl", lines=True).assign(label=0)
non_devops_df = pd.read_json("./training/non_devops_embedding.jsonl", lines=True).assign(label=1)
df = pd.concat([devops_df, non_devops]).drop_duplicates()
df.columns = ["text", "label"]
df["features"] = df.text.apply(lambda x: model.encode(x))
min_class = df[df.label == 0]
max_class = df[df.label == 1]
min_class.to_pickle(toc_path, protocol=pickle.HIGHEST_PROTOCOL)
max_class.to_pickle(bt_path, protocol=pickle.HIGHEST_PROTOCOL)
# if you're tinkering with model architectures load previously saved embeddings
else:
min_class = pd.read_pickle(toc_path)
max_class = pd.read_pickle(bt_path)
# Match the number of minority class samples
max_down = resample(
max_class,
replace=False,
n_samples=len(min_class),
random_state=42,
)
balanced_df = pd.concat([min_class, max_down])
# Shuffle the DataFrame
balanced_df = balanced_df.sample(frac=1).reset_index(drop=True)
return balanced_df
def _train_model(df: pd.DataFrame) -> dict:
"""
Train the SVM on our embeddings
"""
print("training SVM")
X_train, X_test, y_train, y_test = train_test_split(
df["features"].tolist(), df["label"].tolist(), test_size=0.33, random_state=42
)
clf = SVC(gamma="auto")
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
# dumping model
with open("./models/resume_clf.pkl", "wb") as f:
pickle.dump(clf, f)
def main():
df = _get_embeddings(embed=True)
_train_model(df)
if __name__ == "__main__":
main()