
革命性地改变你的YouTube剧本编写:使用LangChain和Streamlit解锁人工智能的力量,创造引人入胜的内容。
介绍:
在当前数字化时代,YouTube 已经成为一个领先的平台,供内容制作者向全世界数百万观众传播他们的思想,娱乐和信息。剧本是制作引人注目的 YouTube 视频的关键组成部分。通过使用写作精良的剧本,您可以保持组织有序并提高内容的整体质量和影响力。在本文中,我们将探讨 LangChain 和 Streamlit 强大的配对如何可能彻底改变您撰写 YouTube 剧本的方式。
了解LangChain:
OpenAI创造了一种复杂的人工智能语言模型,名为LangChain。它基于GPT-3.5架构,使其能够理解和产生类似于人类的文本。当涉及到制作YouTube脚本时,LangChain可能完全改变游戏规则,因为它使得想法、建议甚至整个脚本的撰写变得简单。

代码片段
导入库和包
import os
import streamlit as st
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
from langchain.memory import ConversationBufferMemory
from langchain.utilities import WikipediaAPIWrapper
os.environ['OPENAI_API_KEY'] = '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'Streamlit 应用框架
st.title('?? YouTube Script Assistant')
st.image('./Youtube.png')
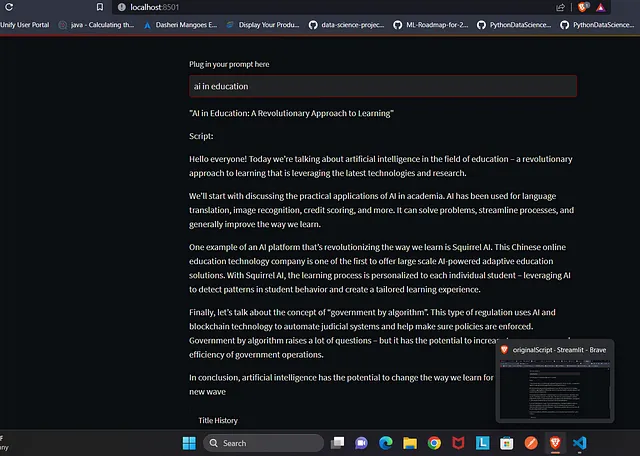
prompt = st.text_input('Plug in your prompt here')提示模板
title_template = PromptTemplate(
input_variables=['topic'],
template='write me a youtube video title about {topic}'
)
script_template = PromptTemplate(
input_variables=['title', 'wikipedia_research'],
template='write me a youtube video script based on this title TITLE: {title} while leveraging this wikipedia research: {wikipedia_research}'
)记忆
title_memory = ConversationBufferMemory(input_key='topic', memory_key='chat_history')
script_memory = ConversationBufferMemory(input_key='title', memory_key='chat_history')WikipediaAPIWrapper(维基百科API包装器)
wiki = WikipediaAPIWrapper()处理用户输入和生成输出
if prompt:
title = title_chain.run(prompt)
wiki_research = wiki.run(prompt)
script = script_chain.run(title=title, wikipedia_research=wiki_research)
st.write(title)
st.write(script)
with st.expander('Title History'):
st.info(title_memory.buffer)
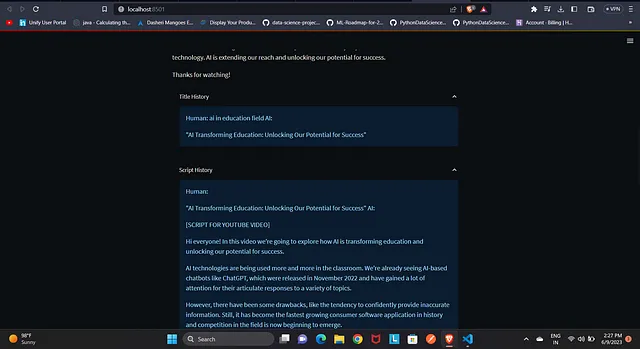
with st.expander('Script History'):
st.info(script_memory.buffer)
with st.expander('Wikipedia Research'):
st.info(wiki_research)以下是完整的代码,供您参考:—
# Import libraries & packages
import os
import streamlit as st
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
from langchain.memory import ConversationBufferMemory
from langchain.utilities import WikipediaAPIWrapper
os.environ['OPENAI_API_KEY'] = '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'
# Streamlet App framework
st.title('?? YouTube Script Assistant') # setting teh title
st.image('./Youtube.png') # set the featured image of the web application
prompt = st.text_input('Plug in your prompt here') # The box for the text prompt
# Prompt templates
title_template = PromptTemplate(
input_variables = ['topic'],
template='write me a youtube video title about {topic}'
)
script_template = PromptTemplate(
input_variables = ['title', 'wikipedia_research'],
template='write me a youtube video script based on this title TITLE: {title} while leveraging this wikipedia reserch:{wikipedia_research} '
)
# Memory
title_memory = ConversationBufferMemory(input_key='topic', memory_key='chat_history')
script_memory = ConversationBufferMemory(input_key='title', memory_key='chat_history')
# Llms
llm = OpenAI(temperature=0.9)
title_chain = LLMChain(llm=llm, prompt=title_template, verbose=True, output_key='title', memory=title_memory)
script_chain = LLMChain(llm=llm, prompt=script_template, verbose=True, output_key='script', memory=script_memory)
wiki = WikipediaAPIWrapper()
# Show stuff to the screen if there's a prompt
if prompt:
title = title_chain.run(prompt)
wiki_research = wiki.run(prompt)
script = script_chain.run(title=title, wikipedia_research=wiki_research)
st.write(title)
st.write(script)
with st.expander('Title History'):
st.info(title_memory.buffer)
with st.expander('Script History'):
st.info(script_memory.buffer)
with st.expander('Wikipedia Research'):
st.info(wiki_research)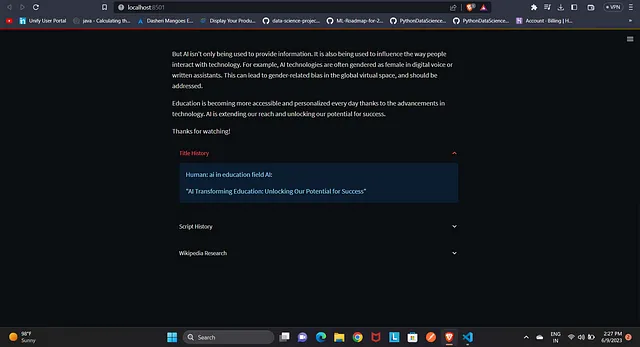
这只是基本模型,还可以进一步定制,我会把它留给你们玩弄。当你发布博客时,请在标签中@我。现在就开始玩!
就这样。
希望您能从本文中找到一些有用的东西,谢谢阅读!
升级编码
感谢您成为我们社区的一部分! 在您离开之前:
- ? 为故事鼓掌,关注作者 ?
- ?在《Level Up Coding》出版物中查看更多内容






