Sure, here's the translation:
```html
ChatGPT人气解读初学者指南:使用Python发现用户洞察
```
Sure, here's the text translated into simplified Chinese while keeping the HTML structure: ```html 解锁AI反馈的秘密 — 无需先前的数据科学经验! 深入Python世界,学会揭示用户对ChatGPT的真实想法。 ```
Sure, here is the translated text in simplified Chinese while keeping the HTML structure:
```html
简介
简介
```
Certainly! Here's the translated text in simplified Chinese: ```html 欢迎来到这个全面的教程,专为数据科学初学者设计,他们有兴趣利用Python从数据中获取洞见。我们将使用ChatGPT应用的评论作为我们的数据集,利用各种Python工具探索用户情感、评分和反馈趋势。这一步骤-by-步骤指南将涵盖从设置环境到应用基本自然语言处理(NLP)技术来理解评论中的文本内容的所有内容。 ``` This translation maintains the HTML structure and provides the simplified Chinese version of the given text.
先决条件
在我们开始之前,请确保你有:
- Sure, here's the translation in simplified Chinese:
```html
Python已安装 — 推荐使用Anaconda发行版,因为它带有大部分必要的软件包。
``` - Sure, here's the translation in simplified Chinese while keeping the HTML structure:
```html
熟悉基本的Python语法和概念。
```
在设置您的环境
- Sure, here's the translated text: ```html 安装Anaconda:访问Anaconda网站并下载适合您操作系统的安装程序。按照安装提示进行操作,确保将Anaconda添加到您的PATH环境变量中。 ```
- Sure, here's the translation in simplified Chinese: ```html 安装库:可以使用 conda install numpy pandas matplotlib nltk textblob 命令安装所有必需的库。 ```
- 在Jupyter Notebook中开始:打开Anaconda Navigator并启动Jupyter Notebook,或者在终端或命令提示符中输入jupyter notebook来使用命令行。
- Sure, here's the HTML structure with the translated text in simplified Chinese:
```html
创建新笔记本:在 Jupyter 界面中,从“新建”下拉菜单中创建一个新笔记本,然后选择“Python 3”。
```
理解数据集
Sure, here's the HTML structure with the translated text in simplified Chinese: ```html
我们的数据集(下载链接在此)包含了从Google Play商店收集的ChatGPT应用的用户评论。数据集中的每一条条目都包含丰富的信息,可以为我们提供有价值的用户体验和感知见解。以下是我们可以使用的数据字段的详细信息:
- Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html reviewId:每个评论的唯一标识符。这有助于区分和引用单个评论。 ```
- ```html
userName: 发表评论的用户的姓名。尽管我们保护用户隐私和道德考虑,但这些信息可以帮助识别用户群体的任何模式或独特见解。```
- Sure, here's the translated text in simplified Chinese: ```html 内容:评论文本。 这是我们数据集中最有价值的部分,因为它包含了用户对应用程序的直接反馈和情感。 ```
- Sure, here's the translation of the text you provided into simplified Chinese, while keeping the HTML structure:
```html
评分:用户给出的评级,范围从1到5。这 quantifies 用户满意度并对聚合情感分析至关重要。
``` - Sure, here's the translated text in simplified Chinese, while keeping the HTML structure: ```html 点赞数:指示有多少其他用户发现该评论有帮助。这可以作为评论的可信度和参与度的代理。 ```
- Sure, here's the translated text in simplified Chinese, maintaining the HTML structure:
```html
reviewCreatedVersion: 应用程序的被审查版本。这有助于跟踪用户满意度在应用程序不同版本之间的变化。
``` - 在:评论发布的日期和时间。这个时间信息可以让我们分析随时间变化的趋势。
- Sure, here's the translated text in simplified Chinese:
```html
```
appVersion:类似于reviewCreatedVersion,但通常用于与评论时的应用程序当前版本进行匹配。
关键特点和用途:
- Sure, here is the translation of the text into simplified Chinese while keeping the HTML structure:
```html
时间分析:通过使用时间戳(在字段中),我们可以看到用户意见随时间的变化,这对于理解应用程序更新或变化的影响尤其有用。
``` - 情感分析:可以对评论的文本内容进行挖掘和分析,以衡量整体情感,检测常见主题,并识别问题点或成功领域。
- Sure, here's the translated text in simplified Chinese while keeping the HTML structure:
```html
版本跟踪:审查特定版本的反馈可以向开发人员提供有关应用程序哪些方面工作良好、哪些方面需要改进的信息。
```
Sure, here's the translation: ```html
这个数据集不仅可以进行用户满意度的详细分析,还可以作为开发者的反馈循环,提供可操作的见解,指导未来的改进。理解我们数据集的结构和内容是释放其全部潜力的第一步。
```Sure, here's the translation:
```html
步骤1:加载和查看数据
步骤1:加载和查看数据
```
import pandas as pd
# Load data
data = pd.read_csv('chatgpt_reviews.csv')
# Display the first few rows of the dataframe
print(data.head())
# Handling missing data by removing rows with NaN values
data = data.dropna()
print(data.head())
Step 2: 初步数据分析
让我们从探索数据集中的基本统计和分布开始。
在 HTML 结构中保持不变,将“Visualizing Score Distribution”翻译成简体中文。
Sure, here's the translated text in simplified Chinese within the HTML structure: ```html
这将给我们一个关于应用程序的一般用户满意度的概念。
```import matplotlib.pyplot as plt
# Plotting the distribution of review scores
data['score'].value_counts().sort_index().plot(kind='bar', color='skyblue')
plt.title('Distribution of Review Scores')
plt.xlabel('Score')
plt.ylabel('Number of Reviews')
plt.show()
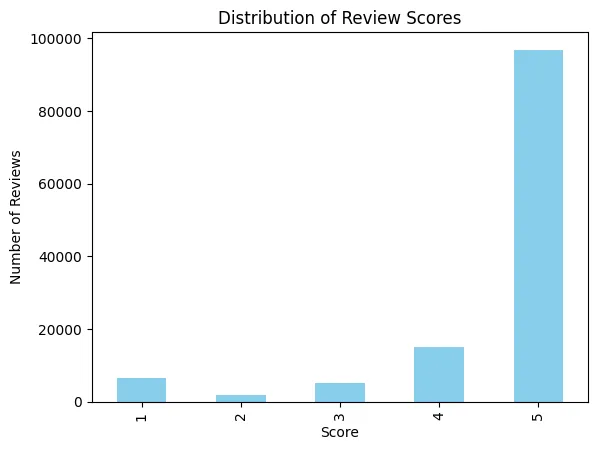
这个图表告诉我们,绝大部分用户给这个应用打了5星的评价!
Sure, here's the translation in simplified Chinese while keeping the HTML structure:
```html
随时间变化的评论量
```
理解评论数量随时间变化如何可以洞察更新或营销活动后用户参与度。
data['at'] = pd.to_datetime(data['at']) # converting 'at' column to datetime
data.set_index('at', inplace=True) # setting 'at' as the index for time series analysis
# Styling
plt.style.use('ggplot') # using 'ggplot' style for a better visual appeal
# Plotting
data.resample('M').size().plot(
figsize=(10, 5),
color='purple',
linewidth=2, # thicker line for better visibility
linestyle='-' # solid line style
)
# Adding grid
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
# Modifying tick parameters
plt.tick_params(axis='both', which='major', labelsize=10)
# Title and labels with increased font size and font adjustments
plt.title('Monthly Review Volume', fontsize=14, fontweight='bold', color='navy')
plt.xlabel('Month', fontsize=12, fontweight='bold', color='navy')
plt.ylabel('Number of Reviews', fontsize=12, fontweight='bold', color='navy')
# Show the plot
plt.show()
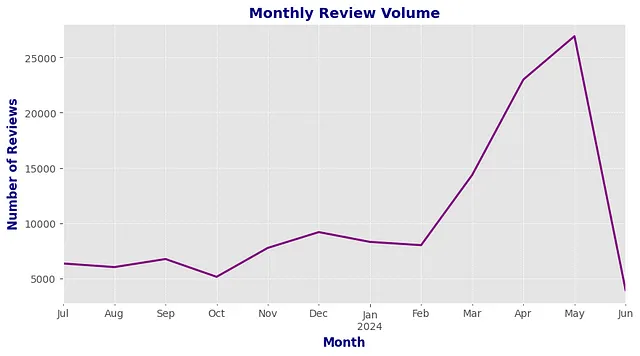
Sure, here's the translated text in simplified Chinese within an HTML structure: ```html
似乎,今年前几个月里ChatGPT应用的评论数量增长迅速!
```Step 3: 深入自然语言处理
Sure, here is the translated text: ```html 为了更深入地了解评论的文本内容,我们将进行简单的情感分析。 ```
Certainly! Here is the text "Preparing the Text Data" translated to simplified Chinese, while keeping the HTML structure: ```html 准备文本数据 ```
Sure, here's the text translated into simplified Chinese while keeping the HTML structure: ```html 我们首先需要对文本数据进行预处理。这包括将文本转换为小写并删除标点符号。 ```
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('punkt')
nltk.download('stopwords')
# Function to clean text data
def clean_text(text):
tokens = word_tokenize(text.lower())
tokens = [word for word in tokens if word.isalpha() and word not in stopwords.words('english')]
return " ".join(tokens)
data['clean_content'] = data['content'].apply(clean_text)
print(data['clean_content'].head())
情感分析使用TextBlob
Sure, here's the translation in simplified Chinese while keeping the HTML structure: ```html
我们将使用TextBlob来计算情感极性,该极性范围从-1(非常负面)到1(非常正面)。
```from textblob import TextBlob
# Function to get the sentiment
def get_sentiment(text):
return TextBlob(text).sentiment.polarity
data['sentiment'] = data['clean_content'].apply(get_sentiment)
data['sentiment'].hist(bins=50, color='orange')
plt.title('Sentiment Distribution of Reviews')
plt.xlabel('Sentiment Polarity')
plt.ylabel('Number of Reviews')
plt.show()
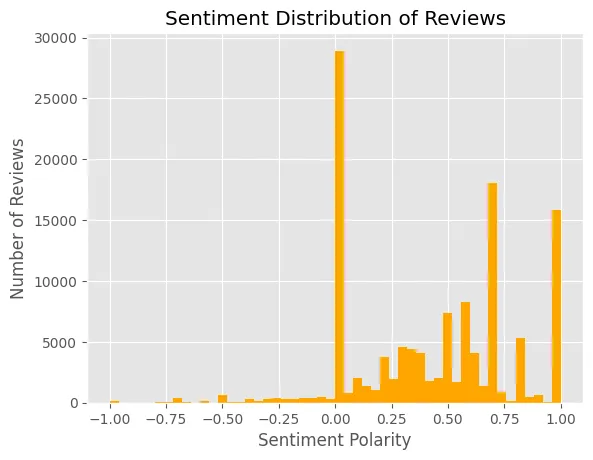
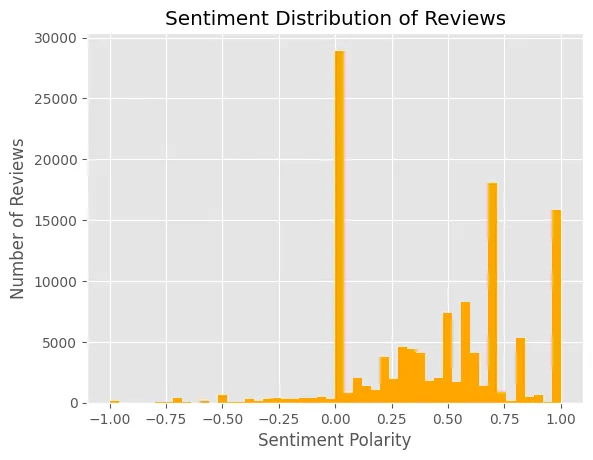
Sure, here's the translation: 这张图告诉我们什么?它告诉我们,虽然大多数评论都给了5星,但大多数人并不对这款应用感到非常高兴(积极极性1)。
Step 4: 高级可视化
Sure, here's the translated text in simplified Chinese: ```html 让我们创建一些高级可视化来进一步探索数据。 ```
情感随时间变化
这将帮助我们了解用户情感是如何演变的。
data.resample('M')['sentiment'].mean().plot(figsize=(12, 6), color='blue', linestyle='-', linewidth=2, marker='o', markersize=6, markerfacecolor='red', markeredgewidth=2, markeredgecolor='black')
plt.title('Average Monthly Sentiment', fontsize=16, fontweight='bold', color='darkblue')
plt.xlabel('Month', fontsize=14, fontweight='bold')
plt.ylabel('Average Sentiment', fontsize=14, fontweight='bold')
plt.grid(True, linestyle='--', alpha=0.6)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
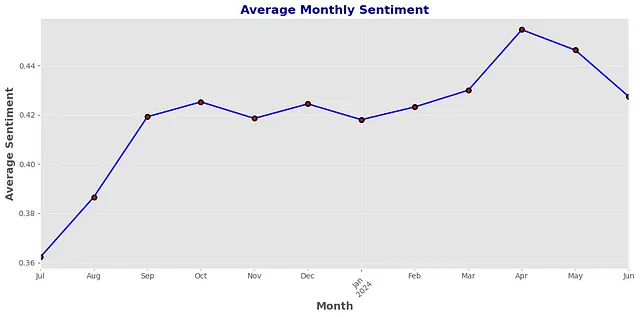
Sure, here's the translation of the provided text into simplified Chinese while maintaining the HTML structure: ```html
你能从上面的图表中推断出什么?在评论中告诉我!
```结论
Sure, here's the translated text in simplified Chinese: 在这个教程中,我们已经通过数据加载、清洗、基本分析,甚至触及了自然语言处理。这些技能构成了数据科学的基础,并打开了进一步探索和深入分析的大门。
下一步是什么?
考虑通过以下方式扩展此分析:
- 在HTML结构中保持完整性,将以下英文文本翻译为简体中文: 集成更复杂的NLP技术,如主题建模或命名实体识别。
- Sure, here's the translated text in simplified Chinese, while keeping the HTML structure: ```html 比较不同机器学习模型的情感分析结果。 ```
- 使用Dash开发交互式Web应用程序,动态显示您的研究结果。
Sure, here's the translated text in simplified Chinese: ```html 希望您觉得这个教程有趣且有启发。欢迎在网上分享您的分析和见解!编程愉快! ```