通过使用ChatGpt来理解银行的A/B测试场景
在本文中,我们将探讨应用程序开发和市场团队常用的统计A/B测试方法。借助我们亲密的盟友ChatGPT,将使用ChatGPT创建的虚构数据集,在Python中实际解释这些方法,保持HTML结构不变。
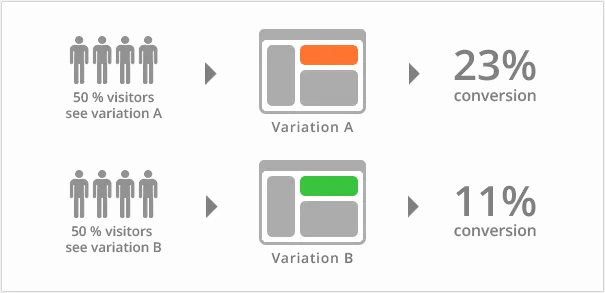
让我们从询问ChatGpt来开始吧。
在过去的两年里,ChatGPT在数据领域取得了显著的进展,为从事这个行业的个人带来了积极的变化。
通过提出正确的问题,我们可以找到许多复杂分析问题的答案。
第一个问题:请逐步描述给我A/B测试的伪代码。

第五个你观察到的项目代表了A/B测试的典型阶段。让我们更仔细地看看这些要点。
- 开始 :)
- 定义目标:明确A/B测试的目标(例如增加点击率,提高转化率)。
- 识别变化:列出要进行测试的不同变化(A和B)。 对于我们参与的每一个银行业务案例,我们将会在两个不同的客户群体中进行两种不同情景的实验。
- 随机分配:对于两种变体,我们将在银行A / B测试案例研究中使用,样本客户选择是独立且随机指定的。例如,为了确定两种变体之间的统计显著差异,需要每个组中的最少50个客户。在这100名个体的集合中,每个客户应该是独立且完全随机选择的,确保他们的决策在所有银行客户中不受彼此的影响。
- 收集数据:针对第2点设定的目标,在A/B测试场景中对两种不同的变体进行测试。例如,点击A银行应用屏幕上绿色的“发送资金”按钮的客户被标记为1,不点击的客户被标为0。同样地,点击B银行屏幕上红色的“电子资金转账”按钮的客户被标记为1,不点击该按钮的客户被标记为0。
样本大小的确定
在第六步中,需要确定两个不同客户群体的最小样本量,以便识别A和B变体之间的显著差异。
我们已经创建了以下Python代码来确定最小样本大小:
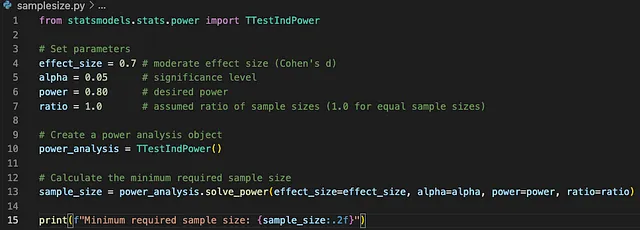
文献中最常用的效应大小(0.7)、显著性水平(0.05)和功效(0.80)参数的阈值已经提供。
比例变量可以完全基于相对基准进行调整。(在本文中,我们将比例设为1,因为我们的目标是在使用的A和B场景中拥有相等的样本大小。)
当代码使用我们设定的阈值运行时,对于情景A和B,每个样本所需的最小样本量为33人,总计66名顾客。

您可以从下方的视频中获得对功效分析的技术细节的访问,包括对effect_size、alpha和power参数的解释。Statquest万岁 :)
7. 选择合适的统计检验
到目前为止,文章中已确定了两个不同的变体:屏幕A上有一个红色背景的“发送资金”按钮,而屏幕B上则展示了一个绿色背景的“电子资金转账”按钮。
设定了一个目标(点击率,平均购买金额等)。
以随机且独立的方式收集了数据,以符合预定的样本大小(Variant A为33,Variant B为33)。
现在,我们需要选择统计检验方法来确定两个变种的样本数据之间是否存在显著差异。
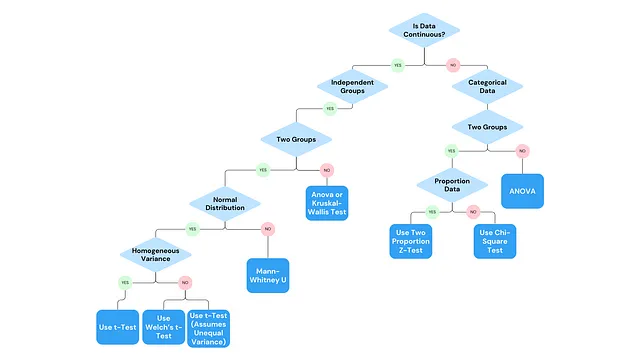
不同的数据类型和条件需要不同的测试。在向ChatGPT咨询关于对不同场景选择统计测试的建议后,通过以下流程图呈现了答案。
KPI 数据类型
连续数据 vs 分类数据
为了确定最适合进行A/B测试分析的统计检验方法,流程图中的第一个问题是:
目标/目标KPI的数据类型是分类还是连续的?
连续数据类型的例子:比较两个不同客户群体的平均交易量,每个群体分别使用不同设计的电子资金转移/电汇屏幕。
一个分类数据类型的例子:比较两个不同客户群体在两种不同的电子资金转账/电汇屏幕设计下执行的成功交易总数(成功:1,失败:0)。
- 连续数据集流程图
1.1 独立对比成对数据集
如果我们确定的目标KPI数据集包含一个连续的数据集,ChatGPT建议的第二个问题是:
客户数据集是完全随机选择的,并且彼此独立,还是属于配对数据集?配对数据集常常用于医疗领域,用于观察个体在治疗前后的状况。例如,给予一组100名患者药物X。然后,将患者的治疗前后血液数值进行比较,以观察药物是否对血液数值产生了显著差异。
在银行和游戏行业中,对设计变更前后的顾客行为进行比较会导致偏见观察。
因为即使我们比较了设计变更前后相同的顾客,并观察到了明显的差异,将其完全归因于设计改变可能不现实。各种外部因素如通货膨胀、汇率和利率可能会影响顾客行为。因此,我们将同时测试两种不同设计,使用完全独立且随机选择的顾客群体。
1.2 两组对比多组
A/B测试的情况不必局限于只有两个A和B的情景,正如其名称所暗示的。可以同时测试超过两个设计屏幕(屏幕A,B,C)。在这些情况下,应该应用ANOVA测试。为了保持本文的连贯性和避免不必要的细节,我们没有在Python中进行ANOVA示例。
1.3 正态分布 vs 非正态分布
在连续分支下的流程图中,该部分是测试数据集是否符合高斯分布的关键点。如果我们的KPI数据集符合正态分布,我们可以应用参数化测试,如T检验。使用Shapira-Wilk-W测试来确定是否适合正态分布,如下所示。

银行场景中的连续数据示例:使用取款金额KPI比较两种不同的ATM屏幕设计变体。
两个不同的ATM屏幕设计被呈现给两个不同的客户群体,每个群体包含34个人。下面的直方图比较了两个不同群体的客户的取款金额。我们可以看到,这两个群体都不符合正态分布。然而,我们仍然应用了Shapira-Wilk-W测试,并证明数据集不符合正态分布。
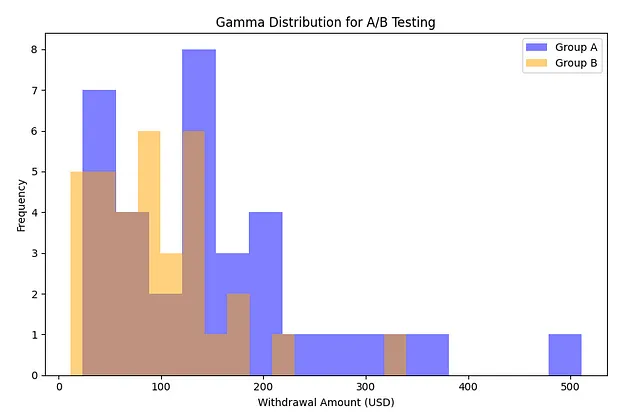
Shapiro-Wilk检验
H0:假设正态分布条件已提供。
H1: 无提供正态分布假设。

如果两组的p值都大于0.05,则符合正态分布。
然而,正如上面的例子所示,如果至少一个组的p值得分小于0.05,ChatGPT建议使用曼-惠特尼U检验,这是一种参数检验。
Mann-Whitney U检验
您可以通过以下链接访问我们在34个客户身上应用的Mann-Whitney U非参数检验的完整Python代码,每个客户观看了两个不同的ATM屏幕。

为了确定两个分布之间是否存在显著差异,需要考虑Mann-Whitney U检验的p值。如果p值一般小于文献中认可的0.05阈值,就可以得出结论认为两组之间存在显著差异。

为了证明这种差异不是随机的,并加强p值的结果,采用了蒙特卡洛模拟方法对p值进行了1000次模拟,并将结果与α值为0.05进行了比较。(也可以选择其他模拟技术,如自助法)。
1.4等方差与非等方差
在使用T检验之前,确保正态分布的条件之后,最后一步是检查两组是否具有相等的方差。为此,我们使用Levene's检验。

Levene的检验
H0:方差齐同。
H1:方差不是齐次的。
让我们重新审视一下我们的 ATM 场景。假设有 34 位客户通过 A-设计的 ATM 屏幕使用 QR 码取款,而另外有 34 位客户通过 B-设计的 ATM 屏幕使用借记卡取款。我们可以使用 Levene 的检验来比较这两组的总取款金额。如果测试得到的 p 值大于 0.05,表示这两组的方差值是相等的(齐方差)。如果 p 值小于 0.05,则说明这两组具有不同的方差值。
T-检验
当方差相等时,使用 T 检验。您可以在下面的链接中查看应用于 ATM 示例的 Python 代码。

威尔奇(Welch's) T检验
在方差不同的情况下,可以使用韦尔奇t检验或假设方差不相等的t检验。您可以查看以下ATM示例的Python代码运行韦尔奇t检验。

2. 分类数据集流程图
目标关键绩效指标(KPI)可能由离散值组成,与连续值的典型构成方式不同。分类数据表示类别或标签,用于将观察结果分组为离散类别。
如果我们将其与示例进行比较,我们以前在ATM示例中比较了两个不同ATM屏幕上客户取款的金额。在这种情况下,每个客户取款的金额在理论上可以有无限的可能性(如100TL,100,000.2TL等)。
在分类数据中,选项被定义。例如,如果客户成功完成了一笔EFT交易,他们取值为1,如果他们有一笔失败的EFT交易,他们取值为0。类似于这个例子中具有两个选项的分类变量被称为二进制数据类型。
当存在多个分类选项时,例如将100个银行客户分为两组,并在两个屏幕上显示绿色、蓝色、红色和黄色按钮的不同设计。我们记录客户点击按钮的信息的列被称为KPI列中的多值分类数据类型。
2.1 两个组
ChatGPT的第一个问题是针对分类流程图的:KPI是否涉及两种不同的情景或多种情景?
如果涉及两个以上的场景,就会使用方差分析(ANOVA)测试。例如,可以给出3个新屏幕设计的比较作为一个例子。
2.2 数据比例
比例数据是通过比较两个不同关键绩效指标的比率而获得的一种数据类型。如果两个关键绩效指标的数据类型都是分类的,可以通过比较两列的汇总数据(如平均值或总计)的比率来应用双比例Z检验。
银行情景分类数据示例:让我们考虑两种不同的移动应用主菜单界面设计。想象一下,在这两个设计中,聊天机器人应用图标的放置位置不同,如下所示。

印象:如果A组或B组中有33个客户中的一个通过放大查看聊天机器人图标,该值为1;否则,如果没有查看,该值为0。
点击:如果在A组或B组的33个客户中,有一个客户在放大聊天机器人图标后向聊天机器人提问,则取值为1;否则,如果没有提问,则取值为0。
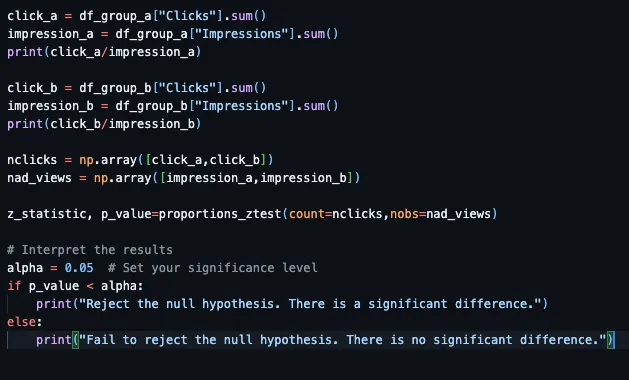
将A组和B组的点击和展示值分别计算,如上面的代码所示。然后将这些值合并到名为'nclicks'和'nad_views'的数组中。对这两个数组进行双比例Z检验。如果从检验中得到的p值小于指定的alpha值0.05,则我们得出结论:在两种屏幕设计之间,33个顾客的行为存在显著差异。
2.2 非比例KPI(单一KPI)
如果我们要比较两个组的仅有一个分类数据类型的目标KPI,那么应用卡方检验。
在银行场景中进行A/B测试的卡方检验:
让我们将信用申请表格的URL从浏览器屏幕发送给34名银行客户。
www.fictivebank.com/LoanApplication → 看到了34位客户
将不同的34家银行客户重定向到一个只有银行移动应用程序的二维码链接,链接的URL不同。在下载移动应用程序后,请他们在移动屏幕上完成信用申请。
www.fictivebank.com/#QR-Code-Screen → 见到了34位客户
在这两种情况下,如果客户成功完成信用申请,取值为1;如果他们无法完成申请,取值为0。

结论
我们使用ChatGPT在Python上生成的虚构数据,通过统计测试分析了银行业中用于开发以客户为中心的移动应用程序的常见A/B测试场景。我们还使用ChatGPT创建了一个流程图,根据所定义的关键绩效指标(KPI)目标的数据类型确定适当的统计测试方法。
旨在创建一本全面的手册,特别是对银行营销分析团队有益的,关于A/B测试。如有任何问题,请随时通过LinkedIn或电子邮件与我们联系。项目目录已添加到GitHub上,你可以在那里找到相关文件。
项目存储库
https://github.com/alialtintass/A-B-Testing-with-ChatGpt/tree/main







