文本到SQL的架构模式:利用LLMs增强BigQuery交互
简短摘要:本文探讨了文本到SQL领域,展示了对于这一复杂任务越来越依赖大型语言模型(LLM)的情况。它强调了LLMs和Google的BigQuery之间的协同关系,展示了这一合作如何改善各种应用程序中的SQL查询生成。本文解释了LLMs如何作为认知处理引擎准确解释用户请求,并与BigQuery进行接口交互以生成精确的SQL命令。这种组合简化了用户对数据的获取,并呈现出一种可在不同领域采用的可扩展数据库交互框架。文章通过探讨旅游和休闲行业的案例研究来展示了这项技术在旅行预订管理中的整合。文章还研究了五种不同的文本到SQL的架构模式,讨论它们的优势和劣势,并概述了它们的最佳使用场景。文章还提供了使用笔记本的实际演示,包含数据集和可执行代码,以展示每种模式。
介绍
文本到SQL是自然语言处理(NLP)中的一个任务,目标是从自然语言文本中自动生成结构化查询语言(SQL)查询。这个任务涉及将文本输入转换为结构化表示,并使用它来生成一个在数据库上可以执行的语义正确的SQL查询。这个任务面临着许多挑战。核心困难在于人类语言与SQL之间固有的差异,人类语言具有流动性、模糊性和上下文依赖性,而SQL是一种精确和结构化的语言。
在历史上,这个问题一直被视为一个查询重构任务,采用序列到序列模型和深度神经网络架构。这些模型是经过战略性训练的,利用两者之间复杂的映射关系将自然语言转化为相应的SQL表达式。
尽管如此,这些架构也引入了一系列的挑战。首先,需要生成和整理数据集,包括人类语言提问和相应的SQL语句,以供预训练或微调使用。此外,无论是输入(自然语言查询)还是输出(SQL查询),都需要进行标准化处理。这就需要进行预处理和后处理的阶段,增加了过程的复杂性。同时,这也意味着大量的训练数据是不可或缺的。还有就是定制化领域知识的融入,比如表名、架构和列描述,也提出了一个难以克服的挑战。
在引入LLMs(文本到SQL的学习模型)之前,用户查询必须经过预处理以匹配特定模板。然后使用该模板重述用户查询。然而,这些模板通常是特定用例的,使得将其扩展到其他领域变得困难。因此,需要大量的数据准备和手动工作来实现所需的格式和模板。
随着LLMs的出现,文本到SQL的领域经历了重大的转变。LLMs表现出色,能够从自然语言描述中生成准确的SQL查询,这得益于它们庞大的知识库和对语境的理解能力。它们复杂的架构,与用于预训练的全面数据相结合,使其能够解析单词之间的复杂关系,从而克服了以前方法中存在的许多挑战。随着LLMs的进化,预计它们在这个领域的熟练程度将进一步提高,为自然语言界面到数据库打开了一个新时代。LLMs的一个关键优势是消除了从自然语言到查询训练数据集的策划和精炼的需求。
在我们即将进行的演示中,我们将利用谷歌的PaLM 2模型的功能,这是LLM系列的一项最新技术,重点是Text-to-SQL。我们的焦点将是一个航班预订系统,这是一个复杂的领域,涉及到复杂的关系和数据结构。在这个系统中,我们将研究涵盖航班详情、乘客信息、预订历史等各种表格,这些数据都存储在BigQuery数据集中。通过利用PaLM 2的LLM驱动架构模式,我们旨在展示将自然语言查询无缝转化为精确SQL查询的能力。这不仅凸显了该模型在理解和处理人类语言方面的高效性,还展示了其在导航关系数据库和生成准确可行的SQL输出方面的能力。通过这些示例,我们将亲身体验Text-to-SQL功能的演变以及LLM在实际应用中的潜力。
BigQuery是Google的全面管理数据仓库服务,它为大规模数据分析提供了强大的平台。它支持快速SQL查询,并因其性能、可扩展性和数据集成的易用性而受到高度赞赏,使其成为数据驱动型企业不可或缺的工具。
在航班预订系统内进行查询面临诸多挑战,主要是由于涉及的数据具有多方面的性质。航班系统涵盖着大量相互关联的表格和数据集,涉及客户细节、机票信息、航班时间表和价格指标等。利用BigQuery进行分析进一步增加了复杂性,分析师希望利用其强大功能进行深入数据挖掘、趋势预测和实时洞察。一个特别关注的问题是数据工程师、科学家和其他专家在制定必要的SQL查询时所需的大量时间和精力。
这些查询的创建并不是一项简单、线性的任务。相反,它通常涉及一系列级联的SQL命令,每个命令都建立在其他命令的基础上,以各种方式聚合、分组、过滤和分析数据,以提取有意义的见解。数据的切分和切块,尤其在像航班预订这样复杂的系统中,要求对细节进行细心的关注,对数据结构和业务需求有深入的了解。因此,专业人士常常发现自己花费数小时甚至数天来完善他们的查询,并建立高效的数据管道,以确保信息的流动和处理顺畅。
潜入一个实际例子,让我们考虑查询的复杂性在一个包含四个表(预订、顾客、交易和航班)的系统中,为了简单起见。每个表,在其自身上都有价值,但在与其他表相互连接时才变得重要。例如,一个旨在确定最经常乘机者的查询可能需要将顾客表与预订和航班表连接起来,将乘客详细信息与航班预订交叉参考。进一步复杂性出现在试图确定这些最经常乘机者在上个季度中进行了最多交易的情况下,需要与交易表合并。
每个上述的查询场景都涉及多个连接、聚合、过滤和可能的子查询。构建这些查询不仅需要SQL专业知识,还需要对底层数据关系和业务目标有深刻的理解。从这四个表中可以得出的潜在组合和洞察力是广泛的,每个查询都可能成为一个复杂的任务,突显了此类系统所固有的挑战。
文本到SQL:建筑的要求
将自然语言翻译成SQL对于高效的数据管理和检索至关重要。良好结构化的架构提高了这些翻译的准确性和速度,增强了LLMs在处理复杂用户查询方面的能力。
在这种架构中,了解特定模式的优点和缺点非常重要。它们的有效性取决于具体情境,并且知道在何处应用它们可以优化文本到SQL的转换。根据独特的场景调整这些模式可以带来更好的SQL生成。
谷歌云平台(GCP)- 通用人工智能词汇表
Vertex AI是Google Cloud的套件,旨在为团队简化和集成ML工作流程,旨在加速AI模型的开发和部署。它以其在安全和可扩展基础设施上自动化和优化ML任务的能力而脱颖而出。
PaLM 2 是由 Google 开发的最先进的语言模型,拥有改进的多语言、推理和编码能力。它经过训练,涵盖了100多种语言的多语言文本,显著提高了其理解、生成和翻译不同语言中微妙文本的能力。
本文中我们将使用的基础模型是Google的生成式AI工具套件的一部分。这些模型经过优化,适用于各种任务,并基于PaLM 2。每个模型都是AI生态系统中的一个战略性构建模块,旨在提高生产力并在各种应用中推动创新。
本文介绍的是Text Bison:一种经过微调的模型,可用于遵循自然语言指令,并适用于各种语言任务。
Chat Bison:为多轮对话场景精心调优的模型。它旨在以类似聊天的形式提供整合、建议和帮助解决问题的功能。
代码拜森:一种根据所需代码的自然语言描述进行调整的模型,用于生成代码。
代码聊天巴伊森:一个针对聊天机器人对于代码相关问题进行细调的模型。它是一个支持针对代码进行特化的多回合对话的基础模型。
代码Bison和代码Chat Bison之间的主要区别在于它们的预期用途。代码Bison专为需要单个交互的代码生成任务设计,而代码Chat Bison则针对连续会话格式中的来回交互进行了优化。代码Chat Bison更适用于需要多次交互完成的代码任务,例如代码调试或问题解决。
除了作为API可用的基于PaLM 2的基础模型之外,Vertex AI还提供了一系列生成式人工智能工具。其中包括Vertex AI搜索与对话、生成式AI工作室和模型花园。每个工具都具有其独特的特点:
- Vertex AI 搜索与会话: 此工具使开发人员能够构建基于生成式人工智能的搜索和聊天体验。它提供了快速构建和部署聊天机器人和搜索应用程序所需的现成功能。开发人员还可以通过API集成或控制台将多个功能整合到他们的工作流程中。
- 生成AI工作室:这个Google Cloud控制台允许快速原型设计和测试生成AI模型。开发者可以使用它来使用提示样本测试模型,设计和保存提示,调整基础模型,并通过丰富的用户界面在语音和文本之间进行转换。
- 模型花园:模型花园拥有100多种尖端LLM和特定任务模型。其中包括上文讨论的谷歌自家的模型以及开源模型,如Llama 2、TII的Falcon、稳定扩散、Mistral等。它通过API和控制台为开发者简化了寻找、部署和维护基础模型的过程。
在本文中,我们将重点介绍来自Google Cloud的第一方基础模型——Code Bison和Code Chat Bison。
建筑模式
LLM(基于语言模型的深度学习模型)在数据库管理和查询构造领域的应用的演进为数据交互开辟了新的途径。通过将LLMs整合到从自然语言生成SQL查询的过程中,我们可以简化和增强数据检索过程。在这里,我们概述了五种在SQL查询生成中实现LLMs的独特模式。
模式I:使用文本到SQL进行意图检测和实体识别
在传统的自然语言理解(Natural Language Understanding,NLU)系统中,将文本转化为SQL查询的过程始于意图检测。这个步骤非常关键,因为它能从用户的查询或话语中识别出用户的目的,这在聊天机器人等应用中尤为重要。意图检测通常被视为一个多类分类问题,需要一个在涵盖所有可能意图的数据集上进行训练的监督学习模型。
然而,引入了LLMs后,情况发生了变化。这些模型可以以零样本或少样本的方式执行意图检测等任务,消除了对大量训练数据的需求。
传统的文本到SQL系统的另一个关键组成部分是命名实体识别(NER),它涉及从用户输入中识别和提取实体。识别这些实体是必要的,因为它们通常对应于数据库元素,如表名或列值,这对于构建SQL查询是至关重要的。
LLMs擅长命名实体识别和上下文理解,能够有效地识别文本中的实体。这种能力使得这些实体能够无缝地集成到SQL查询模板中。
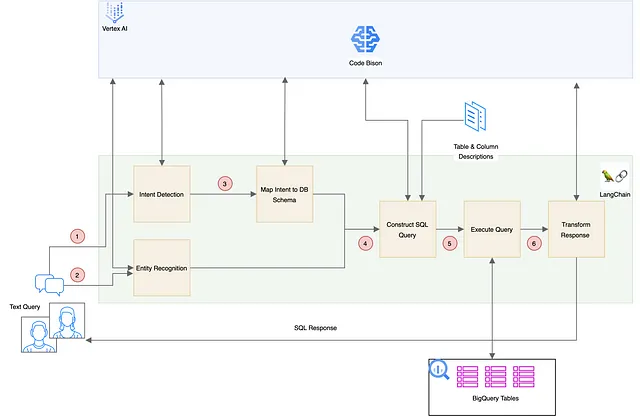
现在,让我们探索这个第一个模式,并看看它是如何工作的,如上所示。这个模式基于通常涉及意图和NER组件的传统系统,但在这里,它使用了LLM。
- 意图检测:用户的查询或话语被输入到LLM中,以确定用户的意图。例如,在预订航班预订的背景下,查询的意图。用于LLM意图分类的少样本提示完成对如下所示。传统上,这将由受监督的精细调整分类器或规则引擎执行。
Need all the bookings from 10th to 15th October 2023.,RETRIEVE_RESERVATIONS
Who made a reservation last Wednesday?,IDENTIFY_RECENT_CUSTOMERS
What was our earning from confirmed bookings in October 2023?,CALCULATE_REVENUE
"In 2023, which month witnessed the highest number of departures?",FIND_PEAK_DEPARTURE_MONTHS
How many customers fall into five distinct age categories?,GROUP_AND_COUNT_CUSTOMERS_BY_AGE
2. 实体识别:使用LLM对相同的用户输入进行分析,可以同时或者依次执行命名实体识别(NER),即从文本中提取相关实体。下面是用于提示的示例对。
"Can you show me all the reservations from October 10th to October 15th, 2023?","Start Date:October 10th, 2023|End Date:October 15th, 2023"
"What bookings do we have from 10/10/2023 to 10/15/2023?","Start Date:10/10/2023|End Date:10/15/2023"
"Show the reservations occurring between the second week of October 2023.","Start Date:October 8th, 2023|End Date:October 15th, 2023"
"List all bookings that are happening from October 10 to 15, 2023.","Start Date:October 10, 2023|End Date:October 15, 2023"
"Fetch the reservations from the second week of October 2023.","Start Date:October 8th, 2023|End Date:October 15th, 2023"
3. 映射意图到数据库表:检测到的意图被用于确定要查询的数据库表。虽然LLMs可以协助这一步骤,但也可以以编程方式作为键值映射检索。下面是一个示例映射。
RETRIEVE_RESERVATIONS,reservations|flights
IDENTIFY_RECENT_CUSTOMERS,reservations|customers
CALCULATE_REVENUE,reservations|transactions
FIND_PEAK_DEPARTURE_MONTHS,flights
GROUP_AND_COUNT_CUSTOMERS_BY_AGE,customers
4. 架构过滤:在确定了文章的标识后,获取相关表的架构,为生成SQL语句做准备。
5. SQL语句构建:收集到的信息包括用户查询、检测到的意图和提取的实体,这些信息与映射的表和筛选的模式信息(如表和列描述)进行整合。这些全面的数据信息被编译成一个结构化的提示,用于LLM生成对用户查询的准确SQL语句的回应。
Please construct a SQL query using the information provided below:
Input Parameters:
-----------------
INTENT: {intent}
EXTRACTED_ENTITIES: {entities}
MAPPED_TABLES: {tables}
User Query:
-----------
{user_query}
Table Schemas:
--------------
{filtered_table_schemas_text}
Note:
- Please prefix the table names with `flight_reservations`.
下面是一个用户查询的示例以及由LLM生成的相应SQL语句的例子。
Provide a list of all flight reservations from October 10th to October 15th, 2023
SELECT *
FROM flight_reservations.reservations
WHERE reservation_datetime BETWEEN '2023-10-10' AND '2023-10-15'
6. SQL 执行:生成的 SQL 语句将被执行并完成文本到 SQL 的转换过程。
7. 人性化的输出:可选地,可以将SQL查询的输出返回给LLM,以便将其重新格式化为更易读的格式,从而提高用户体验。如果您希望在聊天应用程序或任何对话界面中提供响应,这将特别有用。
这一步的示例查询如下:
User's Question:
----------------
{user_query}
BigQuery Result:
----------------
{bq_response}
Task:
-----
Please convert the above query result into a human-readable format.
IMPORTANT Notes:
----------------
- The response should be courteous and human-friendly.
- If the answer doesn't require a tabular structure, avoid using it.
简而言之,Pattern I简化了通常在文本到SQL系统中遇到的复杂性。这样可以得到一个既更高效又更容易设计的解决方案。如果想要在实践中看到应用了这个模式的例子,可以参考一个带有相关代码的示例笔记本。可以在GitHub上的以下位置访问到它。该仓库还包含了所有必要的支持文件,例如few-shot提示的提示完成对、模板和其他资源,位于数据目录中。
请注意,在执行Pattern I笔记本之前,设置所需的BigQuery数据集和表非常重要。可以通过运行位于'00-Setup'目录中的设置笔记本来完成此操作,具体是00-create-tables.ipynb。这个准备步骤对于成功实施本文中涵盖的所有模式非常重要。
优点:
- 适用于表和列数量有限的小型BigQuery数据集。
- 适用于使用基于LLM的解决方案替换现有的意图检测和命名实体识别系统。
- 通过消除多个模型训练和重新训练管道的需要,简化了流程。
- 适用于面向客户应用程序或仅涉及有限场景的系统。
- 旨在实现高准确性的SQL查询生成,并提供可解释性。
- 便于对单个模块或组件进行调试和检查。
限制条件:
- 扩展以涵盖新场景需要对用于少样本提示的数据进行手动更新。
- 缺乏灵活性,无法自动处理新的查询情景,需要手动干预。
模式 II:使用检索增强生成(RAG)的 LLM 流程
如果我们在BigQuery中处理数百甚至数千个表,或者处理具有数千列的宽表格,前面的模式将无法保持。将检测到的意图映射到对应的表格几乎是不可能的。当我们面对新的情景或查询类型时,同样的问题也会出现,第一个模式不能可靠地将意图映射到正确的表格,或者在处理大规模数据时过滤模式描述和列。因此,我们需要一种更高效的方法,这就是模式II的作用。
从语义分析角度看,模式 II 利用 RAG。我们将表的描述和模式描述(列)转化为嵌入向量,然后对这些嵌入向量进行索引以进行搜索。使用语义搜索,我们将用户的查询编码为嵌入向量,并将其与索引的嵌入向量进行比较以找到匹配的表和列。这种策略可以削减搜索空间,使我们能够选择前 K 个结果。其结果就是一个可以在规模上运行的系统,自动逼近我们 SQL 生成所需的候选对象。让我们逐步分解这个过程。

- 嵌入和索引描述:首先,使用文本嵌入模型将表和列的描述编码成嵌入向量。例如,您可以使用Vertex AI的文本嵌入模型textembedding-gecko。一旦描述被编码,创建两个索引,一个用于表描述,另一个用于列描述。考虑到这只是一个演示,可以使用一个独立的向量索引库(如FAISS)。
独立的向量索引极大地增强了向量嵌入的搜索和检索功能,但它们缺少一些在向量引擎或数据库中发现的功能。向量引擎是用于高效相似性搜索和密集向量聚类的工具。它们被设计用于搜索任意大小的向量集,甚至包括无法放入内存的向量集,因此适用于拥有数十亿向量的大规模应用。这些引擎围绕着向量嵌入的概念展开,这些向量数据表示携带着重要的语义信息,以帮助人工智能理解和维护长期记忆并执行复杂任务。
Google Cloud 提供 Vertex AI Vector Search(前身为 Vertex AI Matching Engine),它是一个高规模、低延迟的向量数据库。它专为处理大量数据和低延迟而设计,适用于需要高效向量相似匹配或近似最近邻(ANN)服务的应用。Vertex AI Vector Search 可用于实施推荐引擎、搜索引擎、聊天机器人和文本分类等多种用途。它支持从数十亿个有语义相似或相关的项目中进行搜索,且嵌入不仅限于单词或文本,还可应用于图像、音频、视频和用户偏好等。
2. 查询向量化和表格匹配:在流程的第二阶段中,用户的查询被转换为向量表示,使用指定的编码模型。然后,将这个编码后的查询与事先索引的表格描述库进行比较,以确定与用户意图相符的相关表格。结果匹配项按相关性排序,重点关注前五个匹配项,由将参数K设为5来确定。
3. 列发现和元数据集成:进行第三步时,运用类似的过程,但这次将查询向量与列描述的索引进行匹配。这个匹配过程产生一组相关的列,每个列都附带有元数据和对应的表信息。在这个阶段,参数K设定为20,以扩大搜索范围并提供更广泛的潜在匹配选择。
通过整合第二步和第三步的成果,特别是涉及多个BigQuery数据集的情况下,采用了多层次搜索策略作为这种架构模式的一部分。这种三层式的方法——包括对数据集、表格和列的单独搜索——可以进行全面和精细的匹配过程,精确定位查询构建的最合适候选项。
4. SQL查询合成:在下一步中,着重于SQL生成,系统将所有识别出的组件合成为一个连贯的SQL查询。这个查询的制定是由LLM引导的,它将用户的初始请求转化为准确的SQL语句。下面提供了一个示例模板,演示了系统化查询组装的过程。
Given the following inputs:
USER_QUERY:
--
{query}
--
MATCHED_SCHEMA:
--
{matched_schema}
--
Please construct a SQL query using the MATCHED_SCHEMA and the USER_QUERY provided above.
The goal is to determine the availability of hotels based on the provided info.
IMPORTANT: Use ONLY the column names (column_name) mentioned in MATCHED_SCHEMA. DO NOT USE any other column names outside of this.
IMPORTANT: Associate column_name mentioned in MATCHED_SCHEMA only to the table_name specified under MATCHED_SCHEMA.
NOTE: Use SQL 'AS' statement to assign a new name temporarily to a table column or even a table wherever needed.
5. SQL 执行:生成的 SQL 语句被执行于数据库中,完成文本到 SQL 的转换过程。
6. 人性化输出:可选地,SQL查询的输出可以传回LLM,以重新整理成更易于阅读的格式,提升用户体验。
优点:
- 适用于在BigQuery中处理大数据集和宽表格。
- 通过将意图检测、命名实体识别和手动映射合并为语义搜索,简化了工作流程。
- 由于更短、更高效的提示,降低了推断成本。
- 删除不必要的数据,专注于相关的表和列描述。
- 增强数据处理任务的可扩展性。
限制:
- 通过需要语义搜索,增加管道的复杂性。
- 需要仔细考虑嵌入策略和参数,以实现有效的搜索。
- 一个问题是该工具经常检索到无关的表和列。这导致复杂的查询和不必要的连接,增加了计算时间,并导致冗长且不必要的响应。
- 鉴于这种方法的初始阶段本质上是一种搜索,它会遇到普遍的信息检索问题,比如召回率和准确率较低。它可能需要采取缓解策略,如重新排序以突出最相关的结果。
你可以在这里找到一个演示Text2SQL中RAG模式的示例笔记本。
模式III:使用SQL代理
代理是先进的人工智能系统,扩展了LLM的能力,使其能够执行广泛的任务,超越基本的文本生成。在其核心,这些代理被设计用于交互式通信、推理和任务执行。它们通过详细的提示进行操作,这些提示定义了角色、提供指示、授予权限和提供上下文。这些提示塑造了代理的回应并引导其行动。
在其核心,代理商利用LLMs的复杂语言能力,以自主或半自主的方式响应人类提示。它们配备了一系列工具,包括计算器、代码解释器、API和搜索引擎,使它们能够获取信息并执行操作以完成指定的任务,从而使它们比简单的语言处理器更具动态性。LLM驱动的自主代理系统的关键组成部分包括:1. 计划能力,2. 将任务分解为子目标,3. 选择适当的API进行调用,以及4. 根据这些API提供的结果来制定响应。
此外,这些代理商能够通过将自然语言查询转换为SQL命令来分析SQL数据库。LangChain SQL代理商用于BigQuery是这种能力的一个典型例子,使用户能够使用自然语言与BigQuery数据库进行交互。LangChain本身是一个开源框架,利用LLM来处理自然语言并执行各种任务,展示了这些智能系统的多方面实用性。
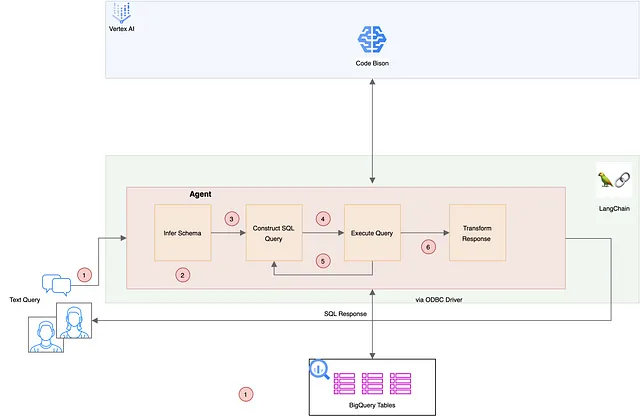
以下是使用LLM代理与SQL数据进行交互的逐步指南,如上图所示:
- 建立数据库连接: 首先,使用Simba Google BigQuery连接器建立ODBC连接。确保您拥有适当的凭据和权限,这可能因语言模型代理和相关数据库而异。在满足这些要求后,您可以直接将用户的问题或话语传递给代理进行处理。
- 架构推断和配置: 配置关键参数,如目录和数据集名称,并使用驱动程序和服务帐户密钥凭据进行OAuth身份验证。此配置对于LLM代理了解数据库架构至关重要。
- 自然语言查询处理:一旦代理程序启动,用户可以输入自然语言查询。代理程序解释这些查询以生成相应的SQL命令。
- 查询执行:LLM代理程序自主执行SQL命令,访问表格和列以构建和检索查询结果。
- 追溯和自我纠正:在LLM生成的查询在语法上不正确的情况下,会发生追溯。代理人具备利用此反馈进行自我纠正的能力,确保查询执行过程顺利高效。
- 友好的输出格式:为了增强用户体验,SQL查询的输出经过LLM代理重新格式化为更易读的格式,提供清晰简洁的数据展示。
这里是一个示例输出,展示了中间状态——提供了对代理人思考过程和行动的一瞥。该场景涉及在特定日期范围内查找并列出所有航班预订。
Provide a list of all flight reservations from October 10th to October 15th, 2023
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input:
Observation: customers, flights, reservations, transactions
Thought: Action: sql_db_schema
Action Input: flights
Observation:
CREATE TABLE `flights` (
`flight_id` INT64 NOT NULL,
`origin` STRING NOT NULL,
`destination` STRING NOT NULL,
`departure_datetime` DATETIME NOT NULL,
`arrival_datetime` DATETIME NOT NULL,
`carrier` STRING NOT NULL,
`price` FLOAT64 NOT NULL
)
/*
3 rows from flights table:
flight_id origin destination departure_datetime arrival_datetime carrier price
1 JFK LAX 2023-11-05 09:00:00 2023-11-05 12:30:00 Delta 450.0
2 LAX JFK 2023-11-10 15:00:00 2023-11-10 23:30:00 Delta 450.0
3 JFK ATL 2023-11-15 07:00:00 2023-11-15 09:30:00 Southwest 300.0
*/
Thought: Action: sql_db_schema
Action Input: reservations
Observation:
CREATE TABLE `reservations` (
`reservation_id` INT64 NOT NULL,
`customer_id` INT64 NOT NULL,
`flight_id` INT64 NOT NULL,
`reservation_datetime` DATETIME NOT NULL,
`status` STRING NOT NULL
)
/*
3 rows from reservations table:
reservation_id customer_id flight_id reservation_datetime status
1 1 1 2023-10-01 10:30:00 Confirmed
2 2 2 2023-10-02 11:00:00 Confirmed
3 3 3 2023-10-03 12:15:00 Confirmed
*/
Thought: Action: sql_db_query
Action Input: SELECT * FROM reservations WHERE reservation_datetime BETWEEN '2023-10-10' AND '2023-10-15'
Observation: [(6, 6, 6, datetime.datetime(2023, 10, 10, 10, 0), 'Confirmed'), (7, 6, 7, datetime.datetime(2023, 10, 12, 11, 30), 'Confirmed')]
Thought: Final Answer: 2 flight reservations were made between October 10th and October 15th, 2023.
> Finished chain.
下面是一个代理人设计行动方案的场景。最开始,代理人生成了一个SQL查询。然而,执行失败了。接着,代理人使用回溯自我修正。
Identify all customers who have made flight reservations within the last 7 days.
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input:
Observation: customers, flights, reservations, transactions
Thought: Action: sql_db_schema
Action Input: customers
Observation:
CREATE TABLE `customers` (
`customer_id` INT64 NOT NULL,
`first_name` STRING NOT NULL,
`last_name` STRING NOT NULL,
`email` STRING NOT NULL,
`date_of_birth` DATE NOT NULL,
`created_at` DATETIME NOT NULL
)
/*
3 rows from customers table:
customer_id first_name last_name email date_of_birth created_at
1 John Doe john.doe@example.com 1985-02-15 2021-01-01 08:30:00
2 Jane Doe jane.doe@example.com 1987-05-23 2021-01-15 12:45:00
3 Alice Johnson alice.j@example.com 1990-08-10 2021-03-20 09:00:00
*/
Thought: Action: sql_db_schema
Action Input: flights
Observation:
CREATE TABLE `flights` (
`flight_id` INT64 NOT NULL,
`origin` STRING NOT NULL,
`destination` STRING NOT NULL,
`departure_datetime` DATETIME NOT NULL,
`arrival_datetime` DATETIME NOT NULL,
`carrier` STRING NOT NULL,
`price` FLOAT64 NOT NULL
)
/*
3 rows from flights table:
flight_id origin destination departure_datetime arrival_datetime carrier price
1 JFK LAX 2023-11-05 09:00:00 2023-11-05 12:30:00 Delta 450.0
2 LAX JFK 2023-11-10 15:00:00 2023-11-10 23:30:00 Delta 450.0
3 JFK ATL 2023-11-15 07:00:00 2023-11-15 09:30:00 Southwest 300.0
*/
Thought: Action: sql_db_schema
Action Input: reservations
Observation:
CREATE TABLE `reservations` (
`reservation_id` INT64 NOT NULL,
`customer_id` INT64 NOT NULL,
`flight_id` INT64 NOT NULL,
`reservation_datetime` DATETIME NOT NULL,
`status` STRING NOT NULL
)
/*
3 rows from reservations table:
reservation_id customer_id flight_id reservation_datetime status
1 1 1 2023-10-01 10:30:00 Confirmed
2 2 2 2023-10-02 11:00:00 Confirmed
3 3 3 2023-10-03 12:15:00 Confirmed
*/
Thought: Action: sql_db_query
Action Input: SELECT customer_id, first_name, last_name, email, reservation_datetime
FROM customers c
JOIN reservations r ON c.customer_id = r.customer_id
WHERE r.reservation_datetime >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
ORDER BY r.reservation_datetime DESC
LIMIT 1000;
Observation: Error: (google.cloud.bigquery.dbapi.exceptions.DatabaseError) 400 Column name customer_id is ambiguous at [1:8]
Location: US
Job ID: adb6b286-65d2-47cc-934e-941f3ddc229d
[SQL: SELECT customer_id, first_name, last_name, email, reservation_datetime
FROM customers c
JOIN reservations r ON c.customer_id = r.customer_id
WHERE r.reservation_datetime >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
ORDER BY r.reservation_datetime DESC
LIMIT 1000;]
(Background on this error at: https://sqlalche.me/e/14/4xp6)
Thought: Action: sql_db_query_checker
Action Input: SELECT customer_id, first_name, last_name, email, reservation_datetime
FROM customers c
JOIN reservations r ON c.customer_id = r.customer_id
WHERE r.reservation_datetime >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
ORDER BY r.reservation_datetime DESC
LIMIT 1000;
Observation: ```sql
SELECT customer_id, first_name, last_name, email, reservation_datetime
FROM customers c
JOIN reservations r ON c.customer_id = r.customer_id
WHERE r.reservation_datetime >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
ORDER BY r.reservation_datetime DESC
LIMIT 1000;
```
Thought: Action: sql_db_query
Action Input: SELECT c.customer_id, c.first_name, c.last_name, c.email, r.reservation_datetime
FROM customers c
JOIN reservations r ON c.customer_id = r.customer_id
WHERE r.reservation_datetime >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
ORDER BY r.reservation_datetime DESC
LIMIT 1000;
Observation: [(20, 'Ryan', 'Reynolds', 'ryan.r@example.com', datetime.datetime(2023, 11, 22, 9, 10)), (19, 'Queen', 'Elizabeth', 'queen.e@example.com', datetime.datetime(2023, 11, 20, 16, 30)), (18, 'Peter', 'Parker', 'peter.p@example.com', datetime.datetime(2023, 11, 15, 12, 50)), (17, 'Olivia', 'Newton', 'olivia.n@example.com', datetime.datetime(2023, 11, 11, 10, 15)), (16, 'Nick', 'Fury', 'nick.f@example.com', datetime.datetime(2023, 11, 8, 15, 30)), (15, 'Mary', 'Jane', 'mary.j@example.com', datetime.datetime(2023, 11, 4, 10, 45)), (13, 'Kate', 'Winslet', 'kate.w@example.com', datetime.datetime(2023, 11, 2, 8, 20)), (13, 'Kate', 'Winslet', 'kate.w@example.com', datetime.datetime(2023, 10, 30, 14, 50)), (11, 'Ian', 'Somerhalder', 'ian.s@example.com', datetime.datetime(2023, 10, 28, 17, 10))]
Thought: Final Answer: Here are the customers who have made flight reservations within the last 7 days:
| customer_id | first_name | last_name | email | reservation_datetime |
| ----------- | ---------- | -------- | ----- | ---------------------- |
| 20 | Ryan | Reynolds | ryan.r@example.com | 2023-11-22 09:10:00 |
| 19 | Queen | Elizabeth | queen.e@example.com | 2023-11-20 16:30:00 |
| 18 | Peter | Parker | peter.p@example.com | 2023-11-15 12:50:00 |
| 17 | Olivia | Newton | olivia.n@example.com | 2023-11-11 10:15:00 |
| 16 | Nick | Fury | nick.f@example.com | 2023-11-08 15:30:00 |
对于上述场景,在初始的查询尝试中,列名 customer_id 存在歧义,因为它同时存在于 customers 和 reservations 表中,并且查询没有指定使用它的表。这导致了一个错误消息,指示由于列引用的歧义,无法处理SQL查询。
一旦发现错误,查询被修改以完整限定带有适当表别名的列名(c代表客户,r代表预订)。这是在SQL中处理具有相同名称列的多个表时常见的做法,以避免歧义。修正后的查询指定了customer_id应该来自customers表,解决了问题,并成功执行查询,检索最近预订飞行的客户列表。
优点:
- 极大地简化用户任务。
- 可以迅速实施以应对各种情况。
- 系统会从挫折中学习并提升自己的表现。
- 特别适用于具有统一模式和已识别查询操作的数据库。
限制条件:
- 对于一个标准代理来说,要理解数据库架构的复杂性可能有些困难。
- 该系统不太灵活,定制性可能更好。
- LLMs有一个上下文窗口,限制可以处理的文本量。这对于庞大的数据库可能会产生问题。
- 费心调整LLM代理的提示和参数以满足您特定的数据库和查询需求可能是必要的,这可能增加其不透明性和有限的适应性。
- 代理经常在处理SQL数据库时遇到一些问题,比如在数据库中创建不存在的表格和字段。
这个示例Jupyter笔记本展示了如何设置BigQuery SQL代理并测试其在六个不同的航班预订场景中的文本到SQL的能力。
模式IV:直接模式推理与自我修正
受我们之前的模式启发,该模式是一个代理程序自主地推断数据库模式、纠正错误并最终制定有效的SQL策略。Pattern IV重新审视了该方法的核心机制,同时增加了可定制性和可解释性。
这种方法从直接推理模式开始,利用“种子提示”来指导LLM构建与用户询问对应的SQL查询。这个初始提示的执行是迭代进行的,直到成功为止。失败被视为LLM的关键学习机会,允许它审查回溯并利用错误消息来改进和完善种子提示,进而得到改进的查询迭代。然后对这个自我校正的查询进行测试;如果成功,则过程完成;如果不成功,则持续进行改进和测试的迭代循环,直到获得成功的结果。
这种模式的独特之处在于它提供了对初始种子提示模板、自我纠正的提示演化机制和关键的过程参数(如可允许的重试次数)的细粒度控制,所有这些都可以进行微调以提高效率。

让我们根据上面的架构图分解步骤:
我们从用户提问(问题)和种子模板开始,如下所示:
Please craft a SQL query for BigQuery that addresses the following QUESTION provided below.
Ensure you reference the appropriate BigQuery tables and column names provided in the SCHEMA below.
When joining tables, employ type coercion to guarantee data type consistency for the join columns.
Additionally, the output column names should specify units where applicable.\n
QUESTION:
{}\n
SCHEMA:
{}\n
IMPORTANT:
Use ONLY DATETIME and DO NOT use TIMESTAMP.
--
Ensure your SQL query accurately defines both the start and end of the DATETIME range.
2.模式推断:LLM接收用户输入的表名,并推断数据库模式。这一步骤对于理解数据的关系和结构至关重要。与自动化了这一步骤的SQL代理模式不同,这里涉及到用户手动选择要关注的表的方面。利用BigQuery客户端直接从所选表中推断出模式。
3. 查询生成:根据推断出的模式,LLM生成初始的SQL查询语句。它涉及使用必要的元素填充种子模板中的空白。此过程在幕后进行,LLM根据提供的模板构建SQL语句。
4. 错误处理和自我校正:如果初始查询执行失败,LLM会捕获错误信息并使用它们来修改查询。错误反馈和错误的SQL语句会指导LLM进化查询。LLM会不断迭代种子提示,逐步完善,直到查询成功执行。
5. 执行和退出:当演化查询成功执行且没有错误时,进程顺利结束。此时,系统停止进一步迭代并退出查询生成循环。
这是一个演化提示的例子,它通过每一次迭代来扩展原始的种子提示。
{prompt}
Encountered an error: {msg}.
To address this, please generate an alternative SQL query response that avoids this specific error.
Follow the instructions mentioned above to remediate the error.
Modify the below SQL query to resolve the issue:
{generated_sql_query}
Ensure the revised SQL query aligns precisely with the requirements outlined in the initial question.
优点:
- 实现非常简单,因为它依靠直接的模式推断,使得系统易于设置。
- 可选的表格和列的描述意味着系统可以使用最少的元数据进行功能运行,提供灵活性。
- 高可解释性是一个关键的优点;可以追踪LSM的响应的快速演变和错误代码以了解其回答并解决问题。
- 定制性在之前的模型基础上得到了增强,可以根据特定需求进行提示、进化条件和重试次数的调整。
限制:
- 该过程可能涉及多次迭代,这可能会引入执行开销,影响性能。
- 手动选择表格进行模式推断可能是耗时且效率较低,尤其是在尝试处理新的和未知情况时。
- 使用种子提示涉及到整合完整的模式,这个过程可能会消耗大量资源,因为语言模型的上下文窗口限制。当添加表格和列的描述以及示例数据时,这个问题会更加显著 — 特别是对于分类和字符串数据类型。此外,随着提示通过添加错误信息和之前错误的尝试而不断演化,超过上下文窗口容量的风险也增加了,从而给模型有效管理和处理越来越大的输入提出了潜在的挑战,每次重试操作的变化。
这是一个示例笔记本,说明了模式IV。它演示了我们之前通过代理人(模式III)测试的六种场景中的自我纠正。该示例使用Code Bison作为此设置的认知功能。
模式推理的变形可能性:
当前模式的缺点是随着每次迭代,种子提示的扩展,并融合错误信息和先前生成的不正确的SQL查询语句。这种扩展可能导致后续对LLM的调用成本增加,原因在于输入尺寸的增长。
为了缓解这个问题,一种战略性的适应方式是用会话式代码模型(例如 Code Chat Bison)替代标准的代码生成模型(Code Bison)。这种方法将迭代过程重新框架为对话,其中错误消息和不正确的SQL语句与简单指令一起传递给代码模型。这有效地回避了扩大提示的问题,从而保留了上下文窗口的能力,并减少了在评估过程中上下文耗尽的风险,这在需要多次重试的场景中特别有益。
在下面的演化提示中,我们不用前缀原始提示与前一个状态。与之前扩展种子提示的做法不同,我们只将错误信息和生成的SQL查询作为对话会话的一部分传递。
prompt = f"""Encountered an error: {msg}.
To address this, please generate an alternative SQL query response that avoids this specific error.
Follow the instructions mentioned above to remediate the error.
Modify the below SQL query to resolve the issue:
{generated_sql_query}
Ensure the revised SQL query aligns precisely with the requirements outlined in the initial question."""
优化后的演变提示,保持了 LLM 的简洁和聚焦的输入流。在我们的共享 GitHub 存储库中提供了一个示例笔记本,展示了利用 Code Chat Bison 进行自校正机制的有效性。
自我纠正的考察
让我们深入研究一个具体的例子,在共享笔记本中的场景6,以说明这种方法如何熟练地自我纠正,最终生成符合所提问题的准确的BigQuery SQL。
Identify and rank all customers aged 18+ who have `Confirmed` reservations for the current month, ordered by their age. Make sure to display their ages in the result.
ATTEMPT: 1
--------------------------------------------------
WITH current_month AS (
SELECT DATE_TRUNC(CURRENT_DATE(), MONTH) AS start_of_month,
DATE_ADD(DATE_TRUNC(CURRENT_DATE(), MONTH), INTERVAL 1 MONTH) AS end_of_month
)
SELECT c.customer_id,
c.first_name,
c.last_name,
DATEDIFF(current_month.end_of_month, c.date_of_birth) / 365 AS age,
r.reservation_id,
r.status
FROM current_month
CROSS JOIN flight_reservations.customers c
JOIN flight_reservations.reservations r
ON c.customer_id = r.customer_id
WHERE r.status = 'Confirmed'
AND r.reservation_datetime BETWEEN current_month.start_of_month AND current_month.end_of_month
AND DATEDIFF(current_month.end_of_month, c.date_of_birth) / 365 >= 18
ORDER BY age
--------------------------------------------------
FAILED
====================================================================================================
ATTEMPT: 2
--------------------------------------------------
SELECT DATE_TRUNC(CURRENT_DATE(), MONTH) AS start_of_month,
DATE_ADD(DATE_TRUNC(CURRENT_DATE(), MONTH), INTERVAL 1 MONTH) AS end_of_month
)
SELECT c.customer_id,
c.first_name,
c.last_name,
DATE_DIFF(current_month.end_of_month, c.date_of_birth, YEAR) AS age,
r.reservation_id,
r.status
FROM current_month
CROSS JOIN flight_reservations.customers c
JOIN flight_reservations.reservations r
ON c.customer_id = r.customer_id
WHERE r.status = 'Confirmed'
AND r.reservation_datetime BETWEEN current_month.start_of_month AND current_month.end_of_month
AND DATE_DIFF(current_month.end_of_month, c.date_of_birth, YEAR) >= 18
--------------------------------------------------
FAILED
====================================================================================================
ATTEMPT: 3
--------------------------------------------------
WITH current_month AS (
SELECT DATE_TRUNC(CURRENT_DATE(), MONTH) AS start_of_month,
DATE_ADD(DATE_TRUNC(CURRENT_DATE(), MONTH), INTERVAL 1 MONTH) AS end_of_month
)
SELECT c.customer_id,
c.first_name,
c.last_name,
DATE_DIFF(current_month.end_of_month, c.date_of_birth, YEAR) AS age,
r.reservation_id,
r.status
FROM current_month
CROSS JOIN flight_reservations.customers c
JOIN flight_reservations.reservations r
ON c.customer_id = r.customer_id
WHERE r.status = 'Confirmed'
AND r.reservation_datetime BETWEEN current_month.start_of_month AND current_month.end_of_month
AND DATE_DIFF(current_month.end_of_month, c.date_of_birth, YEAR) >= 18
ORDER BY age;
--------------------------------------------------
SUCCEEDED
CPU times: user 86.8 ms, sys: 21.3 ms, total: 108 ms
Wall time: 16 s
让我们分解一下了解系统如何在自动纠错其SQL查询方面的尝试。
尝试1
目标:
查询目的是选择当月至少18岁的已确认航班预订的顾客。
问题:
- 年龄计算是不正确的。它使用DATEDIFF来计算客户的出生日期和本月底之间的天数差,然后除以365天来计算。这种方法对于计算年龄并不准确。
- 定义当前月份的公共表达式(CTE)的语法是正确的,但查询失败了,很可能是由于年龄计算方法的问题。
尝试 2
调整:
- 年龄计算: 用 DATE_DIFF(current_month.end_of_month, c.date_of_birth, YEAR) 替换了年龄计算方法。这个方法直接计算出以年为单位的年龄,更加准确。
问题:
- 查询以SELECT语句开头,在CTE之外不带WITH关键字,导致语法错误。
尝试 3
最终修正:
- 语法修正:通过在查询开头添加WITH关键字来正确定义current_month CTE, 对语法进行修正。
- 成功执行:此查询成功检索到所需数据:当前月份中具有确认预订且年龄至少为18岁的客户,按年龄排序。
因此,可以观察到系统通过初始增强年龄计算方法,随后纠正语法错误来实现自我纠正。在最终成功的尝试中,它有效地将准确的年龄计算与正确的SQL结构相结合,从而达到了预期的查询结果。
模式V:直接模式推断、自我纠正和优化
让我们来研究我们想要覆盖的最终模式。这个模式在之前的模式基础上进行了一项关键的变化:不再在成功执行后停止,而是持续改进过程。我们要求系统根据延迟优化查询,并仅在达到设定的迭代次数后停止。实质上,这个模式涉及不断的自我纠正和优化。
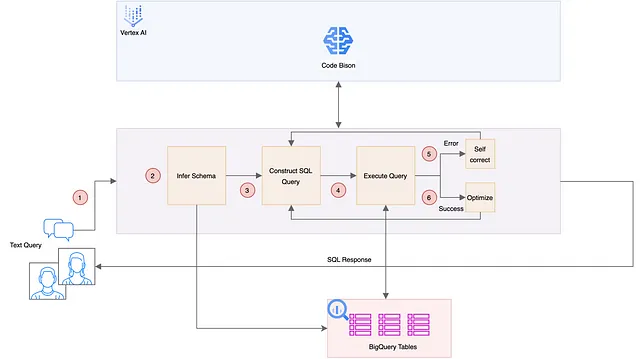
步骤与模式4类似,并增加了优化措施。这包括一次查询优化循环,即使在成功执行后,也持续细化查询以提高性能。还着重通过减少查询执行时间来改善延迟。
注意:在我们这里的改进方法中,我们与之前的模式有了明显的差异。我们将温度参数从0调整为1,这个改变对模型的运行产生了重大影响。在过去(Pattern IV)中,温度被设置为0,这导致确定性的模型输出,即相同的输入始终导致相同的输出,几乎没有变化或创造力的余地。我们通过动态演化提示文本,包括错误代码和生成的查询,增强了这一点。现在温度设置为1,模型的行为明显改变。它现在允许更具创造性和即兴表达的回应。模型不再严格限制在最有可能的回应上,而是探索更广泛的可能性。这为模型的行为增加了不可预测性或“随机性”,这在生成更多样化和创新性回应方面是有利的。这种方法旨在优化反馈循环,无需添加错误代码后缀。
优点:
- 增强查询效率和速度,优化动态改进。
- 适用于查询执行时间优先的高性能设置。
限制:
- 由于涉及多次对LLM的调用,每次调用导致的费用增加,从而产生更高的费用。
- 较慢的过程,因为它需要等待所有候选人的执行和排名,这是由于先前状态信息的必要性而无法并行化。
- 没有保证最快的查询会产生准确的结果,需要对结果进行评估。
可以在此文章附带的共享存储库中找到一个涵盖了这个模式的演示笔记本。
自我纠错和优化模式的变化:
与我们在模式 IV 中观察到的情况类似,我们可以用 Code Chat Bison 替换 Code Bison 来改变提示展开策略为对话式策略。这里可以找到一个使用 Code Chat Bison 的模式 V 的示例笔记本。
自我纠正和自我优化的研究
让我们深入探讨一个情景(从上面共享的笔记本中的Scenario 1),涉及使用LLM进行自我纠正和查询优化的航班预订。LLM经历了多个SQL查询迭代,每一次都旨在提高性能并纠正错误。这个过程以一系列试验为特点,每次尝试都基于前一次的结果来改进查询。以下是对每次尝试进行详细分析,以便理解这个逐步进行的过程。
Provide a list of all flight reservations from October 10th to October 15th, 2023
TRIAL: 1
--------------------------------------------------
SELECT
r.reservation_id,
r.customer_id,
r.flight_id,
r.reservation_datetime,
r.status,
f.origin,
f.destination,
f.departure_datetime,
f.arrival_datetime,
f.carrier,
f.price
FROM arun-genai-bb.flight_reservations.reservations r
JOIN arun-genai-bb.flight_reservations.flights f
ON CAST(r.flight_id AS STRING) = CAST(f.flight_id AS STRING)
WHERE r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59'
--------------------------------------------------
SUCCEEDED
====================================================================================================
TRIAL: 2
--------------------------------------------------
SELECT
r.reservation_id,
r.customer_id,
r.flight_id,
r.reservation_datetime,
r.status,
f.origin,
f.destination,
f.departure_datetime,
f.arrival_datetime,
f.carrier,
f.price
FROM
arun-genai-bb.flight_reservations.reservations AS r
JOIN
arun-genai-bb.flight_reservations.flights AS f
ON
r.flight_id = f.flight_id
WHERE
r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59'
ORDER BY
r.reservation_datetime;
--------------------------------------------------
SUCCEEDED
====================================================================================================
TRIAL: 3
--------------------------------------------------
SELECT
r.reservation_id,
r.customer_id,
r.flight_id,
r.reservation_datetime,
r.status,
f.origin,
f.destination,
f.departure_datetime,
f.arrival_datetime,
f.carrier,
f.price
FROM
arun-genai-bb.flight_reservations.reservations AS r
JOIN
arun-genai-bb.flight_reservations.flights AS f
ON
r.flight_id = f.flight_id
WHERE
r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59'
ORDER BY
r.reservation_datetime
LIMIT 100;
--------------------------------------------------
SUCCEEDED
====================================================================================================
TRIAL: 4
--------------------------------------------------
SELECT
r.reservation_id,
r.customer_id,
r.flight_id,
r.reservation_datetime,
r.status,
f.origin,
f.destination,
f.departure_datetime,
f.arrival_datetime,
f.carrier,
f.price
FROM
arun-genai-bb.flight_reservations.reservations AS r
JOIN
arun-genai-bb.flight_reservations.flights AS f
ON
r.flight_id = f.flight_id
WHERE
r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59'
ORDER BY
r.reservation_datetime
LIMIT 100
USE INDEX (reservation_datetime);
--------------------------------------------------
FAILED
====================================================================================================
TRIAL: 5
--------------------------------------------------
SELECT /*+ USE_NL(r) USE_NL(f) */
r.reservation_id,
r.customer_id,
r.flight_id,
r.reservation_datetime,
r.status,
f.origin,
f.destination,
f.departure_datetime,
f.arrival_datetime,
f.carrier,
f.price
FROM
arun-genai-bb.flight_reservations.reservations AS r
JOIN
arun-genai-bb.flight_reservations.flights AS f
ON
r.flight_id = f.flight_id
WHERE
r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59'
ORDER BY
r.reservation_datetime
LIMIT 100;
--------------------------------------------------
SUCCEEDED
====================================================================================================
CPU times: user 332 ms, sys: 65 ms, total: 397 ms
Wall time: 45.5 s
试用1
- 方法:基本的连接(JOIN)和条件(WHERE)子句。
- 结果:成功。
- 分析:LLM从一个简单的查询开始,使用WHERE子句连接两个表格。成功的结果表明基本的查询结构是正确的。
试验2
- 改进:添加表别名和ORDER BY子句。
- 结果:成功。
- 分析:在成功的基本查询基础上,LLM引入了用于可读性的别名和ORDER BY子句来对结果排序,显示了对查询的可用性和数据呈现的改进尝试。
第三次试验
- 改进:向查询中引入限制(LIMIT)。
- 结果:成功。
- 分析:LLM 添加了 LIMIT 子句,通过限制返回行数来优化查询性能。这是数据库查询中常用的一个实践,特别是在处理大型数据集时,可以改善响应时间。
试验4
- 改进:尝试使用索引。
- 结果:失败。
- 分析:该试验引入了一个索引提示(USE INDEX)以进一步优化查询。然而,它失败了,可能是由于语法问题或指定索引不存在。这显示了LLM在更高级别上优化查询性能的尝试,尽管并非所有的尝试都成功。
试用五
- 改进:使用优化器提示来进行连接操作。
- 结果:成功。
- 分析:LLM通过使用优化器提示(USE_NL)来改变策略,具体指示数据库如何执行连接操作。这表明具有精密的数据库优化技巧,旨在使查询执行更加高效。
LLM从失败和成功中汲取经验。第四次试验的失败很可能在第五次试验中影响了方法,从使用特定的索引提示转变为更广泛的优化提示。在建立成功的基础查询之后,后续的试验侧重于优化——对结果进行排序、限制输出和指导查询执行计划。
这种迭代方法展示了LLM根据结果进行调整和优化策略的能力,展示了在SQL查询中的基础理解和高级优化技巧的混合。
以下是成功执行的查询,按照延迟排名。
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| | Query | Latency | |
| |-------|---------| |
| | SELECT /*+ USE_NL(r) USE_NL(f) */ r.reservation_id, r.customer_id, r.flight_id, r.reservation_datetime, r.status, f.origin, f.destination, f.departure_datetime, f.arrival_datetime, f.carrier, f.price FROM arun-genai-bb.flight_reservations.reservations AS r JOIN arun-genai-bb.flight_reservations.flights AS f ON r.flight_id = f.flight_id WHERE r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59' ORDER BY r.reservation_datetime LIMIT 100; | 7.883168 | |
| | SELECT r.reservation_id, r.customer_id, r.flight_id, r.reservation_datetime, r.status, f.origin, f.destination, f.departure_datetime, f.arrival_datetime, f.carrier, f.price FROM arun-genai-bb.flight_reservations.reservations r JOIN arun-genai-bb.flight_reservations.flights f ON CAST(r.flight_id AS STRING) = CAST(f.flight_id AS STRING) WHERE r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59'; | 8.936372 | |
| | SELECT r.reservation_id, r.customer_id, r.flight_id, r.reservation_datetime, r.status, f.origin, f.destination, f.departure_datetime, f.arrival_datetime, f.carrier, f.price FROM arun-genai-bb.flight_reservations.reservations AS r JOIN arun-genai-bb.flight_reservations.flights AS f ON r.flight_id = f.flight_id WHERE r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59' ORDER BY r.reservation_datetime LIMIT 100; | 11.076487 | |
| | SELECT r.reservation_id, r.customer_id, r.flight_id, r.reservation_datetime, r.status, f.origin, f.destination, f.departure_datetime, f.arrival_datetime, f.carrier, f.price FROM arun-genai-bb.flight_reservations.reservations AS r JOIN arun-genai-bb.flight_reservations.flights AS f ON r.flight_id = f.flight_id WHERE r.reservation_datetime BETWEEN '2023-10-10 00:00:00' AND '2023-10-15 23:59:59' ORDER BY r.reservation_datetime; | 12.221815 | |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
以下是执行优化查询后的最终结果。
+----------------+-------------+-----------+----------------------+---------------------+-----------+-------------+--------------------+---------------------+---------------------+----------+-------+
| reservation_id | customer_id | flight_id | reservation_datetime | status | origin | destination | departure_datetime | arrival_datetime | carrier | price | |
+----------------+-------------+-----------+----------------------+---------------------+-----------+-------------+--------------------+---------------------+---------------------+----------+-------+
| 0 | 6 | 6 | 6 | 2023-10-10 10:00:00 | Confirmed | SEA | JFK | 2023-11-25 06:00:00 | 2023-11-25 14:30:00 | United | 550.0 |
| 1 | 7 | 6 | 7 | 2023-10-12 11:30:00 | Confirmed | JFK | MIA | 2023-11-27 20:00:00 | 2023-11-27 23:30:00 | American | 380.0 |
| 2 | 8 | 8 | 8 | 2023-10-15 13:20:00 | Confirmed | MIA | JFK | 2023-11-30 10:00:00 | 2023-11-30 13:30:00 | American | 380.0 |
+----------------+-------------+-----------+----------------------+---------------------+-----------+-------------+--------------------+---------------------+---------------------+----------+-------+
结论
我们上面探讨的五种模式提供了一系列的策略,包括简单的意图检测和实体识别,以及更复杂的自我纠正和优化技术。每种技术都有其利与弊,强调了根据应用的独特需求和数据集的复杂性选择合适方法的必要性。
展望未来,我们可以预期LLMs会不断演化,很可能导致更无缝集成和更智能的数据库交互界面。这种演化将带来更直观、高效和用户友好的数据管理系统,能满足各行各业以及各种使用场景的需求。
这次讨论中穿插的实际示例和演示不仅展示了这些模型当前的功能,还为该领域的未来突破奠定了基础。掌握了这些模式,开发者和组织可以充分利用文本转SQL技术,简化数据工作流程,并从数据库中发现新的见解。
谢谢阅读本文以及您的参与。您的关注和点赞意义非凡。如果您对内容或共享笔记本有任何问题或疑虑,欢迎随时通过arunpshankar@google.com或shankar.arunp@gmail.com与我联系。您也可以在https://www.linkedin.com/in/arunprasath-shankar/上找到我。
欢迎各种反馈和建议。如果你对大规模机器学习、自然语言处理或自然语言理解感兴趣,并且愿意合作,我非常乐意与你联系。此外,如果你是个人、创业公司或企业,希望了解Google Cloud、VertexAI以及各种生成式人工智能组件在自然语言处理和机器学习中的应用,我会很乐意帮助。请随时与我联系。
参考资料
- Google Palm 2 AI:大型语言模型
- 探索棕榈2
- 棕榈2技术报告
- 了解有关Vertex AI上的生成式AI模型。
- 顶点AI:代码聊天的模型参考
- 自然语言生成AI模型
- Vertex AI:文本聊天模型参考
- 在 Papers with Code 上的 Text-to-SQL 任务
- BigQuery ODBC和JDBC驱动程序概述
- 下载 ODBC 发布版 2.5.2.1004
- 辛巴Google BigQuery ODBC连接器配置指南