第二部分:利用OpenAI嵌入进行语义搜索 - 构建高级检索系统指南
检索系统在人工智能应用中发挥着重要作用,尤其是在处理大型语言模型(LLM)时。在本文中,我们将构建一个处理文档并生成主要概念问题的应用程序。然后,我们将利用这些问题和Upstash的向量数据库,创建一个能够找到与用户查询最接近的文章的系统。最后,我们将使用特定提示从识别出的文章中提取相关信息。

理解AI嵌入:语义搜索的关键
在人工智能中,嵌入式是一种基本技术,用于将复杂和多样化的数据(如文本或图像)转化为机器能够轻松处理的数值格式。它们本质上充当了人类信息感知方式与机器的二进制世界之间的桥梁。通过将单词、句子甚至整个文档转化为数字向量,嵌入式捕捉了数据内部的基本概念和含义。这种转变使得机器能够理解和解读主要的语境、语调和语义。
这些向量可以用来通过在向量空间中测量它们之间的接近程度或距离来识别和检索语义上相似的概念。当我们将单词或短语表示为向量时,具有相似含义的向量往往位于彼此更接近的位置。这种接近程度可以使用各种算法来量化,其中最常见的是余弦相似度算法,该算法计算两个向量之间的夹角的余弦值。
嵌入的有效性可以受到诸如句子的语气和文本中多个概念的存在等因素的显著影响。为了解决这些问题并更好地与最终用户的背景和需求相匹配,我们可以通过为每个概念生成相关问题来提取文章的主要概念。
通过问题生成提取关键特征
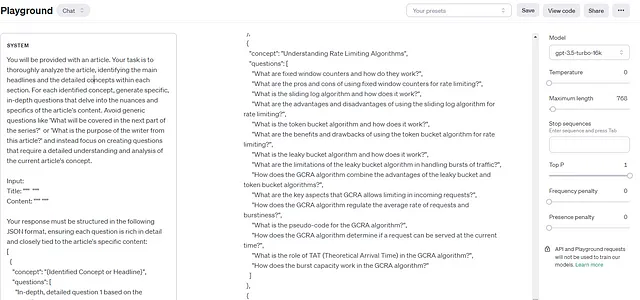
最简单的解决方案是利用一个比较便宜的模型,比如GPT-3 Turbo,该模型具备足够的推理能力,可以从一篇文章中提取主要概念和问题。我们可以将整个文档或文档的批次(如果文档特别长)输入到模型中。通过一个提示,我们要求模型提取主要概念,然后为每个概念生成问题。您将会提供一篇文章。您的任务是彻底分析这篇文章,确定每个部分中的主要标题和详细概念。对于每个确定的概念,生成具体且深入的问题,深入探讨文章内容的细微差别和具体细节。避免使用像“下一部分将包括什么?”或者“作者从这篇文章中的目的是什么?”这样的泛泛的问题,而是专注于创建需要对当前文章概念进行详细理解和分析的问题。
You will be provided with an article. Your task is to thoroughly analyze the article, identifying the main headlines and the detailed concepts within each section. For each identified concept, generate specific, in-depth questions that delve into the nuances and specifics of the article's content. Avoid generic questions like 'What will be covered in the next part of the series?' or 'What is the purpose of the writer from this article?' and instead focus on creating questions that require a detailed understanding and analysis of the current article's concept.
Input:
Title: """ """
Content: """ """
Your response must be structured in the following JSON format, ensuring each question is rich in detail and closely tied to the article's specific content:
[
{
"concept": "{Identified Concept or Headline}",
"questions": [
"In-depth, detailed question 1 based on the concept",
"In-depth, detailed question 2 based on the concept",
// More questions as necessary...
]
},
// More concepts and their questions...
]
尽管修改提示的某些部分可以解决一些明显的问题,但这样的更改也会大大降低它的准确性和性能。因此,准备一个基准样本并使用它来计算提示的准确性,以确保其有效性是一个很好的实践。
我使用了GPT-3.5-turbo-16k模型,因为它支持更大的输入,并具备足够的推理能力来满足我们的目的。此外,我将温度设置为零,因为在这个环境中我们不需要任何随机性。我将我的最后一篇文章作为提示信息输入,结果看起来很有希望。
向量数据库:识别最接近的概念
在人工智能领域,向量数据库至关重要,因为它们能够高效处理与人工智能和机器学习模型相似的复杂多维数据。这些数据库存储和管理数据的向量表示,如嵌入式中使用的向量,能够快速准确地搜索相似项。这对于语义搜索、推荐系统和自然语言处理等任务尤为重要,因为在高维空间中找到最相似的匹配项是必不可少的。现在我们了解了向量搜索的重要性,让我们来探讨一下最常用的用于查找与查询最接近的项的算法。
余弦相似度是在多维空间中计算两个非零向量之间夹角的余弦值,表示它们之间的相似程度。
- 优点:它是尺度不变的,仅关注向量的方向而不是大小,使其在文本处理中对频率变化较为常见的情况下非常有效。
- 缺点:在高维数据中,向量之间的夹角信息较少时,它的性能可能不佳。
欧几里得距离计算欧几里得空间中两点之间的"直线"距离,常用于衡量不相似性。
- 优点:它直观且适用于低维数据,可以提供直接的距离测量。
- 缺点:在高维空间中,距离可能会被夸大并且变得不那么有意义(“维度灾难”)。
点积(Dot Product)是指两个数列对应项相乘之和的度量,用于判断两个向量在多大程度上同向。
- 优点:在计算相似度方面非常有用,特别是在低维空间中,并且对于许多矩阵运算来说是至关重要的。
- 缺点:对向量的大小非常敏感,并且对于比较归一化数据可能不够有效。
余弦相似度特别适用于我们的目的,因为它能够有效地捕捉到向量之间的方向相似性(或方向相似性),这在与文本相关的任务中至关重要,其中向量的大小(或长度)并不重要。
准备Upstash向量索引
在创建索引之前,我们首先需要决定用于创建嵌入的算法或技术。这非常重要,因为不同的算法产生的嵌入维度各不相同,但在我们的数据库中,所有行的维度必须一致。对于本文,我将使用OpenAI最新的嵌入模型text-embedding-3-small,该模型产生的嵌入维度为1536。
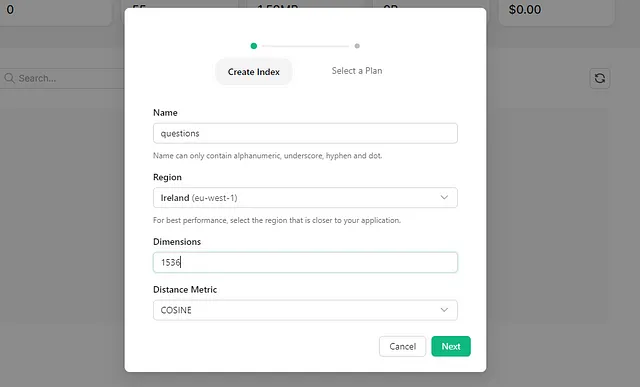
你可以尝试使用Redis搜索等各种技术来实现这个目的。然而,设置和管理可持久化的、适用于生产环境的实例可能会很复杂且耗时。在这种情况下,我建议尝试使用Upstash。它的免费套餐每天提供高达10,000次查询,是一个出色的起点。他们还提供灵活的定价选项,包括按需计费和固定计划,可以根据你的需求进行选择。
创建并存储问题的嵌入
现在我们的设置已经完成,我们可以将生成的问题输入到text-embedding-3-small模型中来创建嵌入,并将这些嵌入存储在我们在Upstash中创建的索引中。为了生成这些嵌入,有许多有用的包可用于支持嵌入的OpenAI的API。例如,Golang用户可以利用https://github.com/sashabaranov/go-openai。
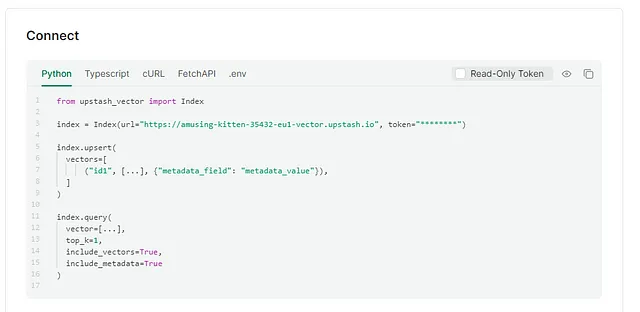
在Upstash网站的主页上,您将找到与您的向量索引交互的示例代码。Upstash提供Python和TypeScript的软件包,但如果您使用的是其他语言,如Golang,您可以轻松设置自己的软件包来使用提供的cURL命令与索引进行通信。
回答问题:最后一步
既然我们可以找到与特定问题相关的文件,我们可以再次使用GPT-3 Turbo。这次,我们的目标是确定所包含答案的准确段落。此外,我们可以要求模型生成自己的解释,以确保答案与问题自然对齐。
You will be provided with an article and a question. Your task is to find the answer to the question, if it exists, in the article. If the answer is not present in the article, do not answer it.
Input:
Title: """ """
Content: """ """
Question: """ """
Your response must be structured in the following JSON format:
{
"exists": boolean,
"paragraph": "Exact paragraph containing the answer from the article",
"answer_with_interpretation": "Model's interpretation based on the answer in the article"
}
Your response must follow these rules:
- You must mention one or more paragraphs that include the answer
- Paragraphs must be the exact text from the article
- Your answer with interpretation must only use those paragraphs as the context
这种上下文感知的问答方法对于急救问题(常见问题解答)和直接问答等应用特别有效,其中答案可以从作为上下文的数据库中相对较小的部分找到。然而,对于那些需要跨多个文档进行交叉引用的更复杂问题,需要使用其他解决方案。

似乎一切运作正常。现在,是时候将所有这些功能整合到一个统一的流程中了。
AI应用中的管道网络
在大多数情况下,即使使用像GPT-4 Turbo这样的尖端LLM,一个单独的提示可能还不够。根据OpenAI在其提示工程指南中的建议,许多场景受益于使用两个或更多提示来提高结果的质量和准确性。类似于本文的应用通常需要一个全面的数据收集、清洗、处理、消化和最终存储在数据仓库中的流程。在各种服务中处理高数据吞吐量时,流水线变得必不可少。在这种情况下,Kafka可能是一个很好的选择。
在即将发布的文章中,我们将利用Kafka构建一个包含本文所讨论的所有功能的流水线,从而实现一个有凝聚力和全面性的应用程序。