Transformer 模型及其变体(ChatGPT)
本文首先会深入探讨 Transformer 的架构及其各种变体。Transformer 架构最初的简介可以归功于 Vaswani 等人撰写的刊物《Attention is All You Need》(2017)。我们将考察他们研究中所开发的 Transformer 模型的具体结构。此外,本文还将全面探讨模型内部各个组件的工作原理。这些见解来自于 Denis Rothman 撰写的富有洞察力的书籍《Transformers for Natural Language Processing》。
原始Transformer模型由六层堆栈组成,每层的输出将作为后续层的输入,直到获得最终预测。Transformer架构由左侧的六层编码器堆栈和右侧的六层解码器堆栈组成。
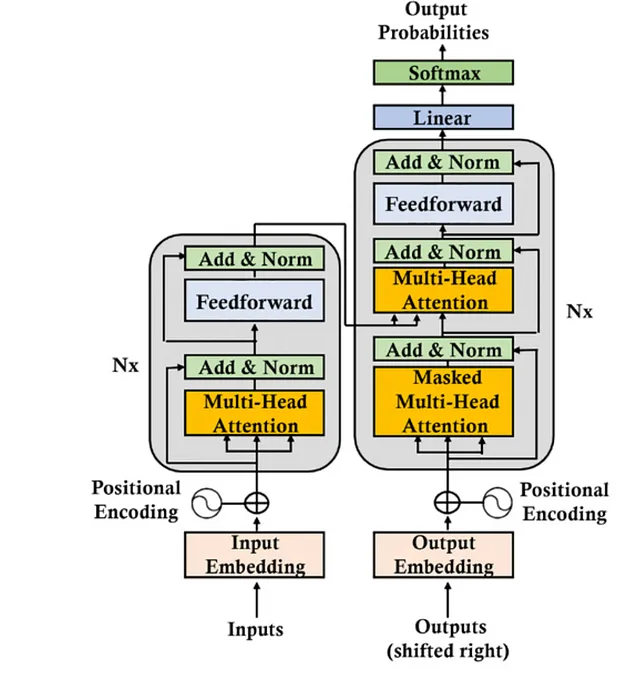
在 Transformer 的编码器端,输入经历了两个主要子层:一个注意力子层和一个前馈子层。而在解码器端,目标输出通过两个注意力子层和一个前馈网络子层。值得注意的是,这种架构与传统模型(如 RNN、LSTM 或 CNN)不同,因为它放弃了递归。注意力机制取代了需要递归函数的需求,这些函数随着单词之间的距离增加需要增加参数。
注意机制以“词对词”的方式运作,在这种情况下,它会检查序列中每个词与所有其他词的关系,包括其本身。为简单起见,我们可以考虑在单词级别上进行此操作,即使它在标记级别上发挥作用。通过计算词向量之间的点积,注意力确定一个词与序列中所有其他词之间最强的关系,甚至考虑分析的单词重复的情况(例如,“it”和“it”)。
例如,我们以以下句子为例:“这只动物之所以没过马路是因为它太累了。” 注意机制将在单词向量之间进行点积,以确定它们之间的关系程度,包括针对诸如“它”和“它”之类的重复单词的自我注意。
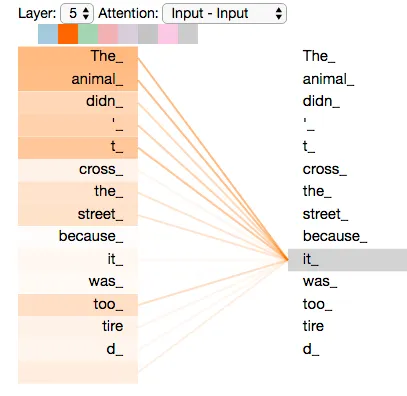
让我们详细探讨变形金刚架构。