生成式人工智能如何改善数据工程?
与大多数人不同,我不是坚信生成式人工智能有能力颠覆每一个行业的人。

这是因为我对人工智能的了解是逐渐深入的,并且通常对这个术语持相对怀疑的态度! 从实际角度来看,AI只是打造许多机器学习(“ML”)模型的一种方式。ML模型只是预测模型的子集(即,一个算法,给定输入,会产生系统准确的预测)。线性回归是一个预测模型。因此,在某种意义上,你可以认为我们应该问自己的问题是如何提高数据工程的统计/数据科学。
让我们举一个简单的例子。
以数据摄入为例,很难看出一个真正好的预测模型如何帮助数据工程师。
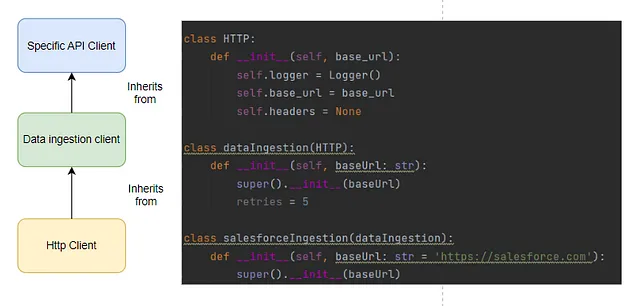
数据摄入通常采用工程师编写通信客户端(HTTP最常见)的模式。在此基础上,可能还会有某种摄入HTTP客户端,其中包括重试和退避等逻辑,并在此基础上,您可能还会有一个与第三方API进行接口的客户端,例如Salesforce。
该客户端随后被嵌入应用程序中,并间歇性调用以触发来自第三方的数据提取。在这些情况下,没有什么可以预测的。例如,假设您正在尝试导入 Salesforce 中的帐户列表,并且要求前40个字段,您只需指定这40个字段的名称,帐户和集成名称(Salesforce)。很难看出在这里预测任何事情是有意义的。
一个可以使用这种方法的领域是错误处理。如果某个过程出错,那么基于输入可以预测出修正方法。例如,如果出现“X列不存在”的错误消息,您可以轻松地建立一个准确预测失败原因为“请求的列不存在”的预测模型,并将其映射到修正方案,在该方案中我们使用git push来移除代码中该列名称。虽然这将非常酷,但是由于提供商错误消息的异质性,手动使用正则表达式映射所有错误可能更快,而不是使用数据科学。所以我们在这里遇到了瓶颈。
好的,那么生成式人工智能怎么样?
生成式人工智能已经能够使用开源软件包进行编程。例如,您可以要求Chat GPT编写Airbyte代码。这很酷。您可以通过Chat GPT建立整个数据摄入框架,但是您可能需要指定一些其他指令,您可能无法完全使用这些代码,不过这可以极大地加速开发过程。
进一步来说,不难想象一种公司,它运行使用 Open AI 插件创建的代码,并且这些代码与 Terraform 代码相结合。我的意思是,如果您要求 Chat GPT 返回一些 Airbyte 代码,该代码将运行但不会被良好地构造,您不能将其部署到您选择的基础设施(例如 AWS、GCP 等),您还可能需要手动添加代码以获取秘密信息。如果所有这些都由数据摄取提供者(“Open AI 数据摄取者”)处理,那么您只需要输入“每天将应用服务部署到 Azure,将 Salesforce 账户、机会和联系人摄取到 Snowflake 中,并确保每天的负载都是增量的。这些信息的秘密存储在 Azure 密钥保管库中,称为“SALESFORCE_API_SECRET”和“SNOWFLAKE_API_KEY”,然后您就可以轻松地将其工作。
这里有趣的是,仍需要建立数据摄入基础设施。事实上,仍是同样的人在做。Fivetran的使命是消除数据团队在构建集成时所需的所有手动工作,他们成功了。然而,现在同样的问题存在,因为Airbyte、Stitch、Fivetran等都有团队在做完全相同的事情——构建和维护集成!具有讽刺意味的是,如果生成式人工智能革命化了数据摄入,另一家公司可以推出基于上述段落描述的基础设施,并将其销售给Fivetran、Stitch等公司。数据工程师的工作将更容易,因为我们可以只编写英语,而无需使用点和按界面。成本也应更便宜,因为生成式人工智能本质上为像Fivetran这样的公司创造了成本节约,他们不需要维护其部署基础设施,而只需购买它即可。
总之,就数据接收的例子而言,很难看出传统统计甚至先进的预测模型如何显著影响数据工程师的日常工作。尽管如此,生成式人工智能似乎在生成用于维护和部署基础设施的代码方面提供了一些前景。结果应该是对非技术性数据工程师来说更容易的体验以及更便宜的成本。我们并没有在这里考虑很多领域(联合驾驶员、分析工程、其他所有领域),所以请继续关注更多讨论!