改革自然语言生成:深入剖析基于LLM的评估方法
自然语言生成(NLG)的进化需要健壮的评估方法。本研究论文深入研究了使用大型语言模型(LLMs)进行NLG评估(即LLM评估)的方法,讨论了它们的优势、局限性以及面临的挑战。该研究提出了基于LLM的评估指标的结构化分类,并在探索未解决的问题,如偏见、鲁棒性和统一评估方法的需求时进行了批判性评估。
1. 简介
- 自然语言生成(NLG)的进步: 尤其是在深度学习和大规模数据集方面,已经极大地提高了文本生成的能力。
- 传统度量的限制:像BLEU和ROUGE这样的传统度量通常无法捕捉语义方面的特征,导致与人类判断产生错位,并需要更细致的评估方法。
- 具有前途的博士学位:博士学位提供精密且符合人类需求的评估,具备生成解释、与人类偏好协调以及处理各种评价任务的能力。
2. 形式化和分类
- 评估框架(E = f(h, s, r)):建立了一个正式的框架,其中“h”代表假设文本,“s”表示输入来源,“r”指的是真实参考资料。
三个分类维度:
- 评估任务(T):解决自然语言生成任务中的多样性,如机器翻译、文本摘要、对话生成等。
- 评估参考(r):区分基于参考和无参考场景。
- 评估函数(f):区分基于匹配和基于生成的方法。
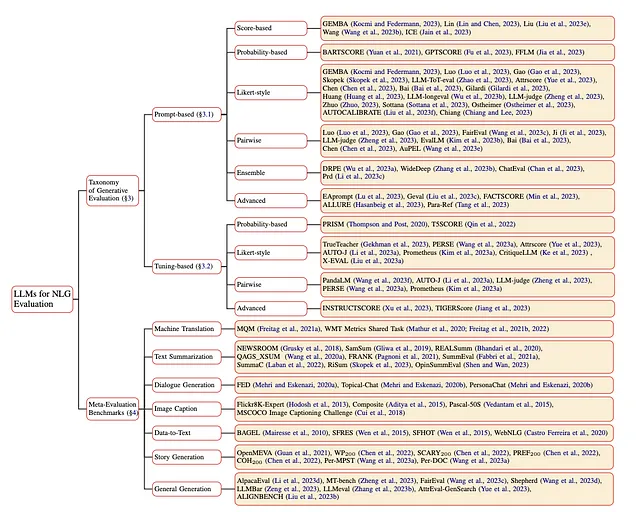
3. 生成评估
- 以基于提示和基于调整两种主要类型的生成式评估区分,根据LLM评估员是否需要微调。
- 评分协议: 检查各种协议,如基于分数的、基于概率的、Likert式、成对比较、集合和高级评估协议。
不同提示类型的例子:
- 基于评分:LLMs为生成的文本分配质量评分。
- 基于概率的:根据提示、来源或参考文献评估文本生成的概率。
- Likert风格:利用Likert量表将文本质量分为多个级别。
- 成对比较:比较生成的文本对,确定哪个更优秀。
- 集成:利用多个LLM评估程序从不同的角度对生成的文本进行评估。
- 高级:采用细粒度的标准或结合思维链或上下文学习的能力进行全面评估。
4. 基准和任务
- 机器翻译(MT):专注于翻译文本同时保留语义意义,通过像WMT Metrics Shared Tasks这样的基准进行评估。
- 文本摘要(TS):包括生成简洁而连贯的摘要,并使用像SummEval这样的基准进行评估。
- 对话生成(DG):旨在生成自然且上下文相关的回应,使用FED等基准进行评估。
- 图像字幕生成(IC):专注于为图像生成文本描述,具有Flickr8K等基准。
- 数据到文本(D2T):将结构化数据转换为可读文本,使用像BAGEL这样的数据集进行评估。
- 故事生成(SG):涉及创建连贯的叙事,具有类似OpenMEVA的基准。
- 一般生成(GE):处理一般自然语言生成任务,通过多场景评估基准例如MT-bench进行评估。
5. 未解决的问题
- LLM评估者的偏见:涉及LLM的固有偏见,包括社会偏见和特定偏见,如排序偏见、自我中心偏见和长度偏见。
- LLM-based评估器的稳健性:突出显示LLM-based评估器在恶意条件下稳健性有显著改进的空间。
- 特定领域评估:强调了需要领域感知的LLMs,能够根据特定领域的标准对内容进行评估。
- 统一的评估:主张使用更全面的评估方法来处理复杂指令和多样化的现实场景。
6.主要发现
- LLMs作为高级评估工具:大型语言模型(LLMs)被认为是自然语言生成(NLG)评估的强大工具。与传统方法相比,它们提供了复杂、精细和与人类对齐的评估。
- LLM基于评估的综合分类法:本调查介绍了一个结构化的分类法,用于对现有的基于LLM的评估方法进行分类。这个分类法对于系统地理解和比较不同的方法论是至关重要的。
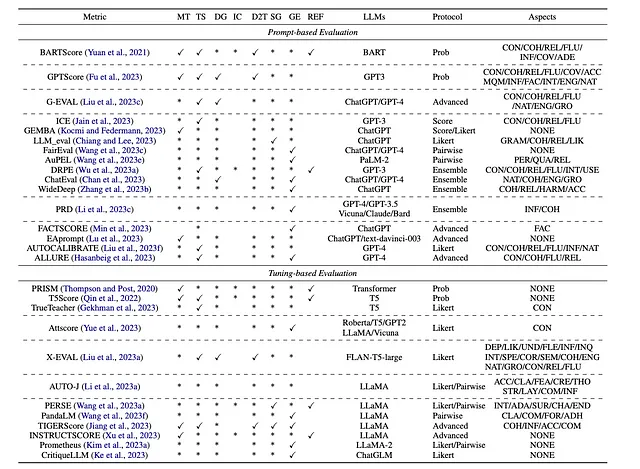
- 多样化的评估协议和方法论:本文探讨了一系列基于LLM的评估协议,包括基于分数、基于概率、利克特式、两两比较和集成方法,每种方法都有其独特的评估生成文本的方法。
7. 结论
这篇研究论文中的调查提供了关于利用LLMs进行NLG评估的结构化概述,介绍了分类法,探讨了方法论,并讨论了所面临的挑战。尽管取得了显著的进展,但该领域仍存在着未解决的问题,如偏差、鲁棒性以及对领域特定和统一评估方法的需求。解决这些挑战对于NLG评估技术的推进是至关重要的。
附录
常见问题解答
1. 使用大型语言模型(LLMs)进行自然语言生成(NLG)评估的主要优势是什么?— 这个问题涉及了利用LLMs评估NLG系统生成文本质量的核心好处,重点关注LLMs在评估过程中带来的先进能力和细致理解。
2. 论文如何对不同的基于LLM的评估方法进行分类,并且它们之间的关键区别是什么?——这个问题旨在探索论文中呈现的分类法,澄清不同的基于LLM的评估方法是如何组织和比较的,包括基于提示和基于调整的方法。
3. LLM在NLG评估中面临的最重要挑战是什么,并且如何解决? — 在这里,重点是理解该论文所突出的LLM在NLG评估领域中存在的限制和未解决问题,如偏见和鲁棒性,并讨论潜在的解决方案或未来发展方向。
4. 请您提供一些例子来说明根据论文如何使用LLM来评估不同的自然语言生成任务,比如文本摘要或对话生成? — 这个问题要求从论文中具体举例或者案例研究,阐述LLM为基础的评估方法是如何应用于不同的自然语言生成任务中,并强调每个任务的细微差别和考虑因素。
5. 本文对于改进基于LLM的自然语言生成系统评估提出了哪些未来的进展或研究方向?- 这里的目的是深入探讨本文对于自然语言生成评估的未来观点,包括进一步研究或发展更高级、公正和全面的基于LLM的评估技术的提议途径。
缩写
自然语言生成任务:
- 机器翻译:MT
- 文本摘要:TS
- 对话生成: DG
- 图像字幕:IC
- 数据到文本:D2T
- 故事生成:SG
- 常规发电:GE
评估的方面:
- 一致性: CON
- 连贯性:COH
- 相关性:REL
- 流利程度: 流利
- 信息性: 信息
- 语义覆盖: COV
- 充足性: ADE
- 自然性:NAT
- 参与:ENG
- 地面性: GRO
- 语法正确性:GRAM
- 受欢迎程度:LIK
- 个性化:PER
- 质量:质
- 兴趣:INT
- 用途: 使用
- 无害性:伤害
- 准确度:ACC
- 事实:FAC
- 适应性:ADA
- 惊喜:SUR
- 角色:CHA
- 结束:结束
- 可行性:有限元分析
- 创造力: 创造力
- 彻底性:THO
- 保持HTML结构,将以下英文文本翻译为简体中文: 结构:STR
- 布局:LAY
- 清晰度:CLA
- 综合性: COM
- 正式:FPR
- 遵守:ADH
- 主题深度: DEP
- 可理解性: UND
- 灵活性: FLE
- 好奇心:INQ
- 具体性:SPE
- 正确性:COR
- 语义适应性:SEM
- 没有特定方面(总体评价):无