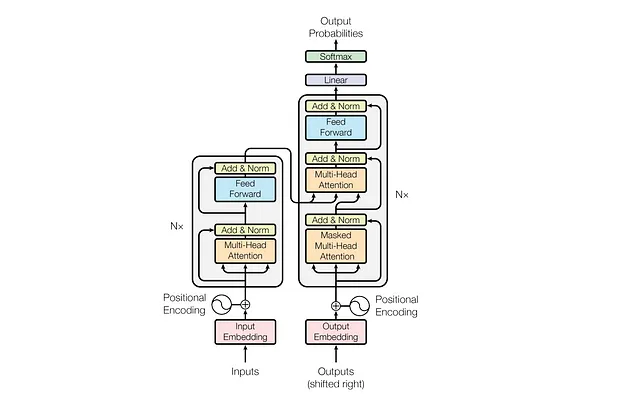
建筑分段人工智能
在2023年11月,Klaviyo向其13万名客户推出了一个名为Segments AI的新分段功能。该服务帮助公司自动化构建客户个人资料的智能分段过程。
本文将介绍Segments AI的工作原理,并思考如何验证创意、非确定性输出。
背景:segment到底是什么鬼?
公司使用Klaviyo来更好地了解和定位他们的客户。客户细分是这个过程的关键部分。
具体而言,用户使用逻辑条件构建其客户群体,通常基于客户所做/未做的事情或关于这些客户的属性。
例如,Klaviyo 用户可以为最近浏览过我的产品名字但尚未购买的客户创建一个分段。分段的输出是一个动态的客户列表,其中满足这些条件。随着时间的推移和新的事件流入,Klaviyo 会保持这些分段的最新状态。
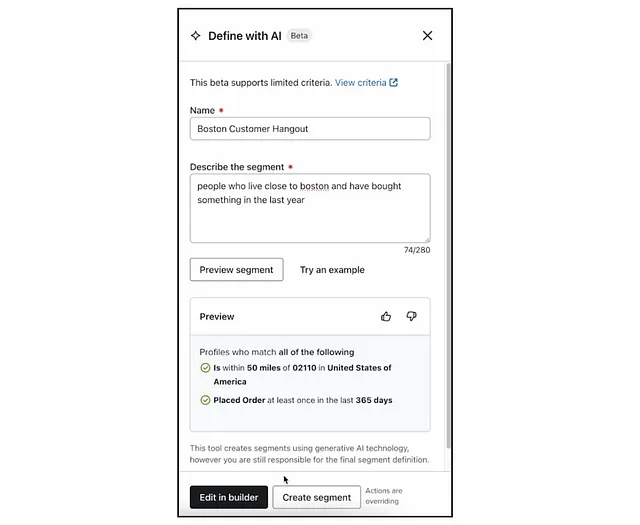
我们要解决什么问题?
当使用得当时,分段是理解和精准定位客户的强大工具。然而,我们的用户太常常无法充分发挥其功能的优势 - 具体而言,一些用户在用户界面上花费的时间要么太少要么太多。
- 问题1:经验较少的用户可能不知道如何将他们的概念表达为 Klaviyo 细分。
- 问题2:经验丰富的用户每周可能花费几个小时来构建重复的部分。
该服务旨在为没有经验的用户提供更简单的与片段进行交互的方式,并为有经验的用户提供自动创建复杂片段的方法。
它是如何工作的?
与过去1.5年开发的许多其他令人兴奋的功能一样,它涉及到一个OpenAI账户。尽管如此,该服务远非仅仅是ChatGPT的封装。
提示串联
分段AI在内部广泛使用提示链接。这意味着当我们使用LLM生成内容时,我们尽量使每个请求尽可能小、原子化和简单化。
通过保持HTML结构,将以下英文文本翻译为简体中文: 在产生结果可以无损地连接在一起的情况下,提示链通常使得生成更快速、更高质量。换句话说,当生成一个JSON对象的部分时,提示链非常有效;但是如果将一个段落逐句生成作为一系列离散请求,将会产生一个弗兰肯斯坦式的结果。
尽管提示链接通常会提高生成质量,但它也会导致错误像LLL电话游戏一样传播的风险。对于这种错误传播风险,还没有达成一致的术语,但我们称之为链熵。
链熵问题在像Segments AI这样的用例中尤为突出,其中生成的内容需要遵循特定的格式(在我们的情况下,是Klaviyo的段落JSON模式)。为了缓解这个问题,我们尽可能将子任务分离和并行处理,以减少需要通过的关卡。就像产品开发一样,瀑布结构在过程的早期选择错误路径时可能导致不幸的结果。
澄清:在Segements AI的情况下,提示链是这种方法的常用名词,但在这种情况下有点不准确。提示链意味着同步过程(即一个执行在另一个之后进行)。然而,Segment AI在许多过程中是异步进行的(即同时发生)。
少样本学习:又称阅读ChatGPT睡前故事
在数据科学中,Few-shot学习的思想是将一个通才模型(例如ChatGPT)转变为特定主题(例如定义Klaviyo段)的专家,只需使用少量的示例进行微调。然而,Few-shot学习的思想可以超越其经典用例。我们可以创建数十个子任务专家,每个都具有自己的专业领域。
少样本学习通常是通过使用手动设计的训练样本来显式地微调所需的模型来完成的。然而,在LLM的情况下,可以通过将训练样本作为系统指令隐式地进行该过程。我们发现,在这些训练样本中注释输入、理想输出和可推广的学习内容时,可以获得最佳性能。
这类似于通过儿童故事给GPT进行教学。我们发现这方法出人意料地有效。
与提示链接配对,这意味着我们可以向专门的聊天机器人代理提出一系列小型、高度具体的问题,并将这些结果拼接在一起形成最终的组合。
挑战
验证
工程师通过设计单元测试来测试新功能以挖掘边缘情况。数据科学家使用真实测试数据集验证模型。
在整个行业中,越来越明显的是,没有人确切知道如何评估LLM(联合语言模型)功能。当我们使用基于LLM的功能,比如Segments AI,我们失去了输入和期望输出之间的一对一映射关系。
简而言之,当有数十种共同有效的方法来定义“参与用户”的时候,要以一种快速、可扩展且具有成本效益的方式评估功能的表现就变得困难。
似乎人們主要集中在三種方法上,每種方法都有自己的優點和缺點。
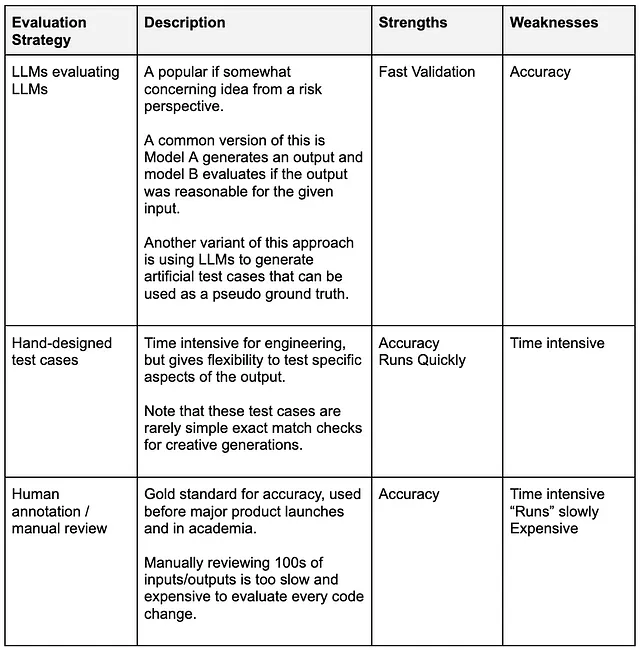
在Segments AI功能开发的过程中,团队在这些选项之间反复权衡。验证一直是一个让人头疼的问题,因为我们每周都在不同选项之间徘徊。此外,随着新功能的添加,测试用例也变得更复杂,使得回归分析更加复杂。
最终,我们决定使用混合LLMs评估LLMs和手动设计的测试用例。我们创建的验证套件是以包装形式提供的,可以在对代码库进行重大更改之前运行。这两种评估策略都不完美,但它们是一种有用的、指导性的工具,可以用于快速反馈和错误诊断。
验证LLM功能与创意输出是值得做的,尽管可能会带来一些困扰。然而,最终用户将使用您的功能,而不是您的验证套件。如果您发现自己花费超过三分之一的时间来修正验证问题,那么可能有更好的时间利用方式。
最重要的事情是确保验证是一个清晰的信号,并且与利益相关者的期望明确且一致。
最后的想法 (Zuìhòu de xiǎngfǎ)
生成式人工智能功能永远不会真正完善。客户需求会发生变化,错误会出现,而且始终存在无法预测的小问题需要处理。
所以,虽然这篇博客文章可能要结束了,但是 Klaviyo 在人工智能方面的工作绝对不会停止。实际上,随机输出和技术的快速发展意味着 Gen AI 特性通常需要比其他标准的数据科学项目更多的维护工作。不过这可能是最好的,因为我们发现花在这些工具上的时间会带来积极的溢出效应。
越多时间数据科学团队花费在建立生成性人工智能工具上,他们在解决这些问题方面就拥有越多内部力量和专业知识。客户在使用生产环境中的工具花费的时间越多,我们就越能更好地了解他们的需求。数据科学与产品团队花费更多时间一起合作开发面向客户的功能,这样的合作就能越好。
生成式人工智能的特点与数据科学家过去十年或二十年一直从事的“正常”项目有着实质性的不同。它们需要进行不同的验证,涉及新的风险,并且通常比团队所熟悉的更注重外部表现。
团队、个人甚至机器学习模型都通过示例来学习。快乐建设。