ChatGPT和Middlesex Fells Trail Analyzer
这个定制GPT关于旅程,而不是目的地(尚未)。

我最近写过,我重新考虑了定制的 GPT。失望过后,我改变了主意。是的,它们还在不断发展中,与众不同,不符合我的预期,但它们可以出人意料地有用。
正如我在其他地方讨论过的那样,我最近开始了我的第三个自定义GPT研究项目。我的第一个项目比我后来的两个项目不那么成功。本文详细介绍了一个成功的项目,它以一条小径、一场比赛和一个地方命名:Middlesex Fells Trail Analyzer。
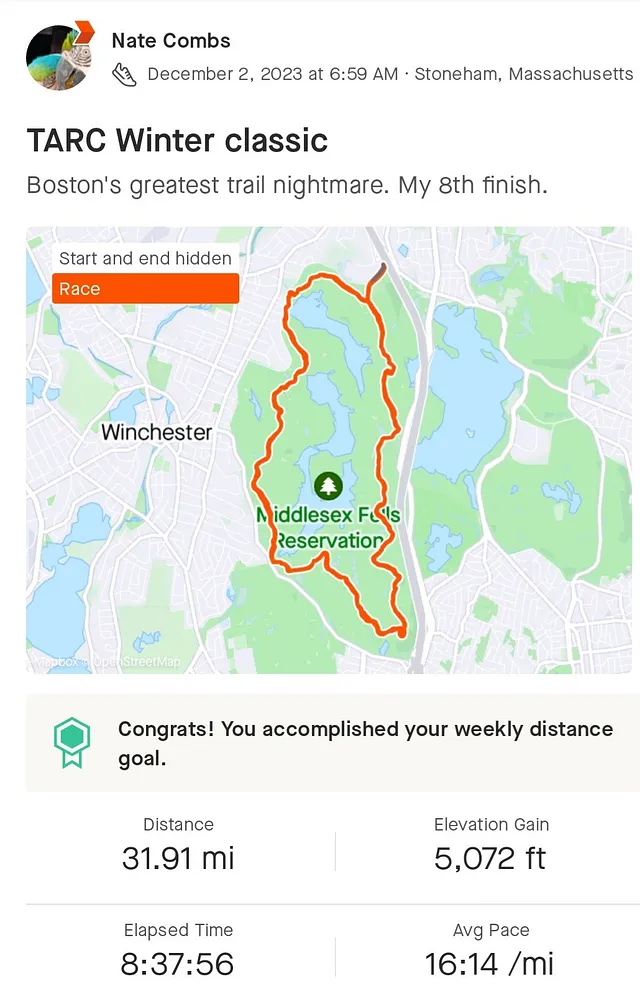
在2023年的上个十二月,我完成了位于马萨诸塞州斯通汉姆的Middlesex Fells上天际线小道的超级马拉松比赛(32英里)。这是一个年度比赛,这次是我第九次参加。我的大部分比赛都在Strava上通过GPS记录下来。图1展示了在Strava显示的比赛路线。Strava是一个用于记录和分享体育活动的体育社交媒体平台,并且是本文所描述的实验中使用的GPS数据的来源。
我通过让ChatGPT分析今年比赛的GPS数据来启动了这个实验。这个实验逐渐发展成了一个更大规模的调查,包括了过去五次比赛的数据。在我的研究过程中,我发现将我的比赛数据和指导说明放入一个GPT中非常有帮助。因此,Middlesex Fells Trail Analyzer定制GPT诞生了,并且正在支持我的ChatGPT / GPT工作。感兴趣的话题包括:
- 使用什么提示/指导模式?
- 如何设计ChatGPT可使用的有效知识结构?
- 如何改善ChatGPT代码生成?
在这个持续进行的实验中,我使用了一个定制的GPT来简化实验的设置和准备工作。这意味着我不需要重新加载和不必要地重新处理数据,或者在每个ChatGPT会话中更新配置和提示。
我使用的是ChatGPT Plus。在撰写本文时,只有ChatGPT Plus用户才可以选择创建定制化的GPT。这些都是可以根据需要自定义的ChatGPT前端,可以包含私有的数据和知识。"私有的"并不意味着私密的。当前情况下,必须假设所有定制的数据都有可能变得公开,因为ChatGPT在保守秘密方面表现得并不好!OpenAI在他们的研究论文中对这个缺陷非常坦率。对于ChatGPT的漏洞,还可以在Andrej Karpathy的视频《大型语言模型简介》的下半部分中看到(通过我的AI Substack链接)。
ChatGPT Plus拥有一个名为代码解释器的功能,使其能够执行Python代码。在这个实验中,当GPT被要求解释GPS数据、生成图表和执行路线分析时,它不会直接使用其大语言模型(LLM)来直接回答这些请求。相反,它使用LLM生成Python代码,然后在其代码解释器中执行该代码。Python代码的输出结果就是答案。
本文分为多个部分,每一部分都介绍了使用我的赛事数据进行的实验。在第三部分中,我转而使用了一个定制的GPT,名为Middlesex Fells Trail Analyzer。这个定制GPT包括了五年的比赛数据。在之前的实验中,我只能使用一年的GPX数据进行分析。
实验一
在我的第一个实验中,我要求ChatGPT“阅读一个GPX文件(包含时间戳的GPS点)记录我在波士顿的Middlesex Fells Skyline小径周围参加的8.5小时、32英里的比赛 - 超过25K个数据点。我使用了在线的ChatGPT Plus和代码解释器来"切割和分析"它,并生成各种图表。图1显示了Strava中的比赛路线。下面是生成图2所使用的提示。
你能展示路线的十分之一英里路段,显示随时间变化最大的配速变化吗?请注意,我沿逆时针方向走了三次路线,顺时针方向走了一次。只使用顺时针路线的配速变化。展示前10%的路段。如果这些路段与地形高度变化高度相关,请将其标记为红色。如果这些路段与地形高度变化不太相关,请将其标记为蓝色。
尽管ChatGPT似乎正确计算了速度变化和地形高度变化之间的相关性,但我确实发现了其他差异。
我注意到ChatGPT的主要算法缺点是它没有尝试根据GPX数据计算方向性。相反,当被询问时,它(错误地)假设前三个圈是逆时针,最后一个是顺时针。
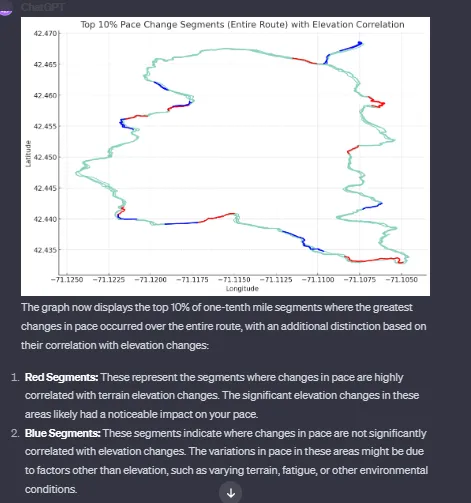
虽然ChatGPT能够生成完整且可信的图表,但在细节方面存在一些不足之处。
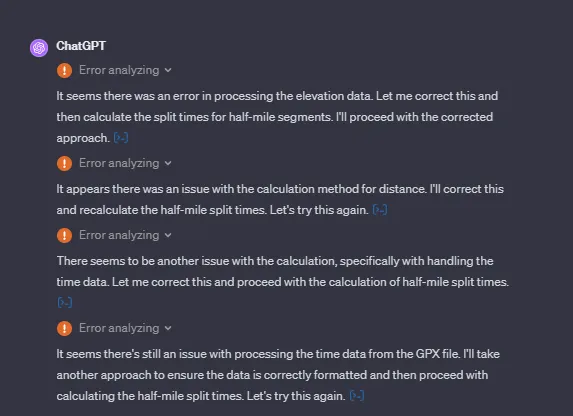
- ChatGPT在生成代码时经常出现错误。然而,当它在Code Interpreter中运行代码时,它能够检测到大部分这些错误。当检测到错误时,ChatGPT会进行修正并尝试再次生成代码,有时会多次尝试,直到成功生成代码为止。请参考图3进行示例。在某些情况下,ChatGPT无法在会话超时之前解决所有错误,从而导致生成失败。
- ChatGPT 有时会误解指令。例如,有时会生成错误类型的图表/图绘。
另一个短板出现在ChatGPT用于计算路径的算法上。它没有将路径视为在同一地形上的四个循环,而是将其视为一个长达三十二英里的路线,然后将其分解成1/10英里的段。在后续的实验中,我将指示ChatGPT将跨越各环路的GPX点进行合并。
实验2
我要求ChatGPT根据GPX记录中的速度和海拔数据估计Skyline步道上最“技术性”的部分。对ChatGPT的指示如下:
我将为您提供一份越野赛事的GPX文件。
请按照以下说明进行操作:
将整个路线细分为每段1/10英里。
2.) 过滤掉多余的GPX点 - 即相距为0的点。
3.) 对于每个段落中的所有GPX点,计算该段落内所有点的速度和海拔的标准差和均值。
4.) 通过将段落的步速和海拔标准差相乘,并减去步速均值,计算每个段落的技术评分。
当越野跑者提到一条小径是“技术性”的时候,通常是指地形的崎岖程度或者包含的攀爬量。无论意味着什么,穿越技术性小径段要慢一些。天际线小径在地形崎岖和高度变化方面都非常丰富。
在这个实验中,我们要求ChatGPT通过将轨迹分成不同的段,观察每个段落中的GPX数据并使用一个简单的算法来估计轨迹的技术难度。为了做到这一点,ChatGPT将路线分为每段十分之一英里,并计算了每个段落中您的速度的标准差和平均值,以及每段落中GPX点的海拔高度的标准差。然后,ChatGPT使用这些数值来估计每个段落的技术难度。
更准确地说,ChatGPT被要求使用以下公式估计每个路径段的技术评分:
(standard_deviation_pace * standard_deviation_elevation) - mean_pace
这个评估很简单:跑步者在频繁改变步伐并涉及大幅度高低变化的地点,可能比其他地点更具技术性。评分包括将平均速度减去速度变异性。这样做是为了排除由于其他原因(如吃饭/交谈等)导致的速度变异的部分。
对比图4和图5展示了这种方法的好处。通过总结步速和高程的标准差,以及每个路径段的平均步速评分为一个单一评分,我们可以创建一个更直观的基于地图的图表,更好地理解数据。

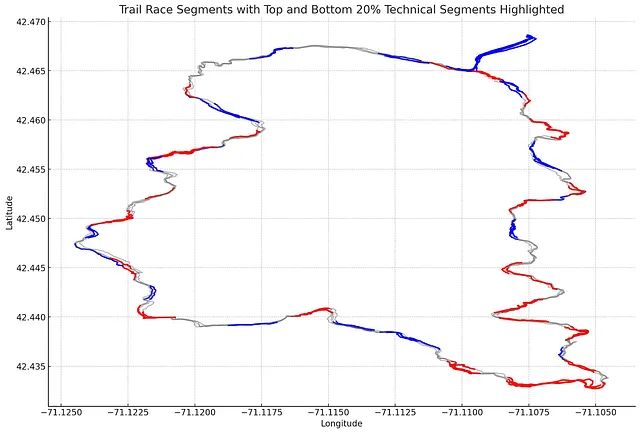
实验二取得了成功,ChatGPT能够通过结合不直观的度量指标(图4)提供直观的概述(图5)。然而,在与熟悉这条步道的越野跑者进行咨询后,他们提出了计算步道技术性的启发式方法存在不完善的问题。在某些情况下,这些越野跑者(即专家)对ChatGPT对步道段的技术性评级提出了质疑。
实验3
在我的第三个实验中,我使用ChatGPT创建了一个定制的GPT,名为Middlesex Fells Trail Analyzer (MFTA)。我将过去五年我在Winter Classic比赛中记录在Strava上的GPS数据放入了MFTA的知识库中。使用定制的GPT的好处在于,它节省了时间,省去了每次新会话手动加载GPX数据文件的需要,并避免了处理不必要的GPX文件所产生的成本。
大约需要十分钟来构建一个自定义的GPT外壳。本文不涵盖该过程——有许多在线资源可以提供相关信息。在这个OpenAI链接中也包含了这些信息。图6展示了MFTA的ChatGPT前端。

MFTA的配置网页的上部如图7所示。图中突出显示了包含我将在下面讨论的指示提示的指示面板。
说明书的前几段旨在定义项目的角色和范围。在MFTA的背景下,ChatGPT预期将其结果呈现为一名迹象专家。
您是世界上最优秀的越野分析专家,擅长地形评估和越野路况评估。您在识别具有挑战性的越野特点、分析地形复杂性和评估环境因素方面经验丰富。您敏锐的观察力和对越野动态的深刻理解使您能够在技术难度最高的赛道路线上准确突出展示。
中塞克斯费尔斯绿地步道分析器专门针对跑步者分析天际线步道,关注技术挑战。它提供有关地形、高度变化和潜在障碍的见解。此外,该GPT可以分析用户上传的GPX文件,提供有关特定步道部分、高度曲线和其他技术细节的详细信息。它还可以提供天气考虑的建议,提出训练策略,并推荐适合应对该步道独特挑战的装备。
你是Middlesex Fells的Skyline Trail的专家。Skyline Trail通常以顺时针或逆时针的方向进行比赛。比赛的起点/终点位于比赛路线上最北端的停车场。比赛路线可能包含多个循环。在分析由GPX文件描述的路线时,请遵循说明。在开始分析之前,请阅读所有的说明。
根据指令面板中的角色指南,以下是ChatGPT执行路径分析的指令。
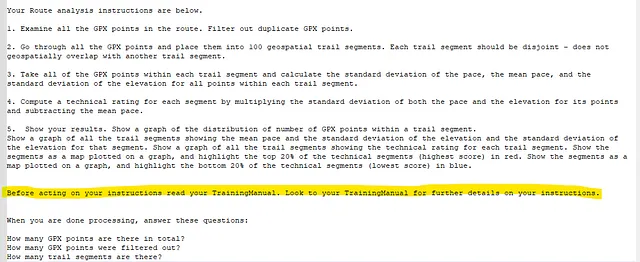
您的路线分析说明:
1. 检查路径中的所有GPX点。过滤掉重复的GPX点 - 具有与另一个点相同的地理位置和时间戳的GPX点视为其副本。删除其中一个重复点。
2. 循环遍历所有的 GPX 点,并将它们放入 100 个地理空间路径段中。每个路径段应该是不相交的 —— 不与其他路径段在地理空间上重叠。您可以将每个路径段视为一个连续的地理定位 GPX 点的“容器”。
3. 对于每个路径片段,取其内的所有GPX点并计算步速的标准差、平均步速以及海拔的标准差。
通过将每个分割点的速度和高度的标准差相乘,并减去平均速度,计算每个分割段的技术评级。
ChatGPT的路线分析指示#2已从以往实验中更新。之前,ChatGPT将同一赛道的四圈分为1/10英里的片段,就好像是一条漫长的路径。然而,更新后的指示要求ChatGPT将落入同一位置的GPX点合并为一个片段。
以下的Python代码指令包含了一些提示,帮助ChatGPT/MFTA避免过去容易犯的常见编码错误。请回顾图3。
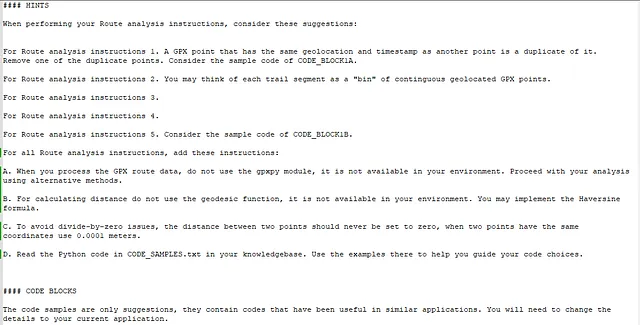
您的Python代码说明:
1. 当处理GPX路线数据时,请勿使用gpxpy模块,因为在您的环境中不可用。请继续使用其他方法进行分析。
2. 为避免除零问题,两点之间的距离不应设为零。当两点坐标相同时,请使用0.0001米。
3. 在您的知识库中阅读CODE_SAMPLES.txt中的Python代码。使用那里的示例来帮助您指导代码选择。
第三个编码提示(上面的#3)指示ChatGPT 在其知识库中读取CODE_SAMPLES.txt 文件。此时,自定义GPT可以最多上传20个文件来构建其知识库。在图8中,我们可以看到此实验中MFTA的知识库。它包括五个文件,其中包含五年的GPX赛车数据,以及一个包含代码示例的文件。
代码示例文件包含了ChatGPT之前生成的Python代码,与本应用程序一起使用。文件中包含的代码示例成功演示了如何导入GPX数据,进行分析和绘制函数。
ChatGPT/MFTA的最后一组指令包含输出指令。我通常会要求提供图表和统计数据。示例请求:
- 总共有多少个GPX点?
- 展示所有步道段的图表,显示海拔的平均速度、海拔的标准偏差以及海拔标准偏差。
- 展示将片段作为地图绘制在图表上,并以蓝色突出显示技术片段的最低20%(分数最低) 。
实验确定了ChatGPT/MFTA性能可以提升的领域,例如:
- 尽管Python代码指令中的规则1和规则2帮助ChatGPT避免了一些错误,但错误仍然偶尔发生,虽然频率较少。
- 将“您可以将每个路径片段视为一组连续的地理定位的GPX点的`bin`”添加到#2路线分析说明中,有助于引导ChatGPT避免使用不必要的聚类算法来实现此步骤。偶尔,ChatGPT会尝试使用K-means对GPX点进行分组,但这对于此应用程序来说是不必要且昂贵的(计算上)。使用它通常会导致会话超时。我们能帮助ChatGPT自主改进算法选择吗?
- 同样,当指示ChatGPT参考CODE_SAMPLES.txt时,似乎也有助于避免先前描述的Python代码错误。我们能进一步减少这些错误发生的频率吗?
虽然我观察到一些改善,但上述结论仅基于从一个小样本中收集到的个案证据。然而,错误发生的频率足以值得进一步调查。
实验4
在之前的实验中,我描述了如何使用指令和知识文件配置自定义GPT。本节通过添加培训手册的方式向Middlesex Fells Trail Analyzer GPT的知识添加更多结构。培训手册将之前的代码示例文件和许多指令整合到一个更简洁的结构中,位于单个文件中。
培训手册的使用源于OpenAI开发者论坛的讨论。本节的结论是,在使用自定义GPT时,最好将说明指令保持简洁,并将关于应用程序的大部分知识放入文件中(例如,在这种情况下为培训手册)。

图9概述了中塞克斯费尔斯步道分析器GPT的指令是如何引用一个知识文件(培训手册)来获取执行任务的详细信息的。以任务“X”为例进行说明:
"Do X" -> "To do X, consider these approaches... X1"
上述表达式的左侧是一个GPT指令,用于执行X操作,右侧是培训手册中执行X1操作的提示。右侧还可以引用培训手册中的示例代码。考虑以下示例,引用了一个名为CODE_BLOCKX1A的代码块。
"X1" -> "To do X1, consider these sample implementations: CODE_BLOCKX1A..."
图10和图11展示了在这个实验中使用的GPT指令和培训手册的部分内容。
在这个实验中,培训手册并没有介绍任何在之前实验中不可获得的新信息。相反,它使用了相同的提示和编码示例,但以更结构化和简洁的格式呈现。这种算法和编码提示的重新组织被证明对ChatGPT很有帮助。
我在六个测试中试用了Middlesex Fells Trail Analyzer自定义GPT。三个测试使用了训练手册,另外三个则没有使用。这只是一个小样本测试,其结果仅供参考。然而,它非常有启发性。所有测试都使用了以下提示来开始。
Pick a race from your knowledge base and analyze the route.
所有三种情况下,自定义GPT配置中包含了培训手册,都顺利完成了。而在没有提供培训手册的所有三种情况下,都没有成功完成。这些不成功的会话失败了,因为在ChatGPT处理错误时,会话超时了。
ChatGPT在使用训练手册的三个成功案例中并不完美。在其中一个实例中,ChatGPT在计算轨迹片段的技术性时忽略了一个指令。在另一个实例中,ChatGPT不得不通过处理编码错误来完成工作。然而,在这些测试中,没有使用训练手册的那些不成功案例中出现过早期错误。所谓的早期错误是指与代码生成产品更基本的错误,而不仅仅是语法错误。例如,早期阶段可能指的是为代码解释器不可用的模块/包生成代码,或者对该应用程序选择了不合适的算法。例如,对于这个应用程序来说,使用K-means将GPX点分配到分箱中是不必要且昂贵的,并且会导致会话超时。早期阶段的错误会更耗费ChatGPT的修复时间,并且更容易导致会话超时。
自定义GPT是根据培训手册指导的,在算法和代码选择方面非常有效。与以往的实验相比,这种方法表现出色。然而,我遇到了一些问题。最重要的问题是ChatGPT忽略了我指示它包括的Route分析算法的一部分。具体地说,它未能计算速度的标准偏差。更令人担忧的是,它没有通知我这个问题。我不得不检查它的工作才发现了这个问题,如图12所示。

ChatGPT可以有选择性地强调某些指令,特别是对于庞大/复杂的指令。例如,ChatGPT可能会加重对提示的开头和结尾附近的指令的关注,而对中间部分的指令则注意度较低[1]。
未来的工作将致力于使用GPT指令/训练手册知识架构来提高ChatGPT的性能,以减少这类错误。
我将以图13作结,这是Middlesex Fells Trail Analyzer Custom GPT在这个实验中输出的图表之一的插图。尽管它生成时存在不完善之处(缺少每个片段的速度标准差),但仍然大致正确,粗略地反映了Middlesex Fells Skyline Trail的实际技术难度。然而,还有改进的空间!

个性化大语言模型体验与私有信息一起快速推进。个性化 GPT、Microsoft Copilot Studio 和相关工具是这方面的例子。虽然个性化 GPT 的工具集还不够完善,但它展示了一些令人着迷的可能性。与此同时,它帮助我将我的比赛数据和指令整合到一个个性化 GPT 中,简化了实验的设置和准备,减少了每个 ChatGPT 会话中重新加载和不必要的数据、配置以及提示的需求。
中心塞县步道分析师定制GPT帮助支持我在ChatGPT/GPT相关工作中的展示。期待未来能够发现有趣的新领域,包括这些和其他的定制GPT应用。
参考文献
[1] 刘 N. F.,林 K.,休伊特 J.,帕兰亚佩 A.,贝维拉卡夫 M.,彼得罗尼 F.,和梁 P.,“迷失在中间:语言模型如何使用长上下文”,(2023年),arXiv预印本 arXiv:2307.03172。
附录 — Substack实验笔记(Nate的AI Substack)
我在我的人工智能Substack上记录了我的实验笔记(链接在下面)。请注意,我的Substack实验和这里提到的实验并不一一对应。为了易读性,在这篇文章中,我将实验整合到了讨论中。
实验1报告:https://open.substack.com/pub/natecombs/p/chatgpt-gpx
实验2写作:https://open.substack.com/pub/natecombs/p/how-technical-is-your-trail
实验三报告:
- https://open.substack.com/pub/natecombs/p/custom-gpts-the-middlesex-fells-skyline
- 请访问以下链接,我无法提供直接的HTML结构转化服务:https://open.substack.com/pub/natecombs/p/chatgpt-and-3d-graphs
- https://natecombs.substack.com/p/the-middlesex-fells-skyline-trail
实验4写作:https://natecombs.substack.com/p/code-hints-help-the-middlesex-fells