使用OpenAI API在20行代码中解决情感分析问题
使用大型语言模型处理情感分析问题的最简单方法是利用其嵌入式 API。该 API 可以将您指定的任何文本段转化为一个向量,即一组固定长度的参数,以表示大型语言模型下的任何文本段。
首先,我们需要计算“正面评价”和“负面评价”这两个词的嵌入。嵌入API可以让您获取任意给定文本的向量空间值。然后,余弦相似度计算文本与给定词之间的“距离”。通过计算文本嵌入与“正面评价”之间的相似度减去该文本嵌入与“负面评价”之间的相似度,我们将得到一个最终分数。如果此分数大于0,则您的文本在“距离”上更接近“正面评价”,因此可以判断该文本很可能是一个“正面评价”;否则,它可能是一个“负面评价”。
以下,我将使用这种方法来分析两个亚马逊乐高玩具评论。


以下,我将使用这种方法分析两个亚马逊乐高玩具的评论。
用于情感分析的代码仅有20行。让我们看一下它是否能够快速对这两篇评论进行情感分析:
import numpy as np
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
EMBEDDING_MODEL = "text-embedding-ada-002"
def get_embedding(text, model):
text = text.replace("\\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Get Positive Review And Negative Review's Embedding
positive_review = get_embedding("Positive Review", EMBEDDING_MODEL)
negative_review = get_embedding("Negative Review", EMBEDDING_MODEL)
positive_example = get_embedding(
"Overall, packaging was very nice. Purchased this as a gift for a kid's birthday party. Loved the detachable book on the front of the box. The kid should be extremely pleased with the item.", EMBEDDING_MODEL)
negative_example = get_embedding(
"I purchased this product for a birthday gift. The Lego box was shipped in a bag and the box was all dented and damaged. No time to make a return as it was a gift.", EMBEDDING_MODEL)
def get_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
positive_score = get_score(positive_example)
negative_score = get_score(negative_example)
print("Positive rating : %f" % (positive_score))
print("Negative rating : %f" % (negative_score))
结果:
Positive rating : 0.080185
Negative rating : -0.054586
如我们所预期,通过嵌入相似度计算,产品的积极评价获得了大于0的分数,而消极评价则得分低于0。
这难道不是一个特别简单的方法吗?让我以前面评估咖啡的句子为例,看看它是否同样有效。
import numpy as np
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
EMBEDDING_MODEL = "text-embedding-ada-002"
def get_embedding(text, model=EMBEDDING_MODEL):
text = text.replace("\\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Get Your API Key
# Get Positive Review And Negative Review's Embedding
positive_review = get_embedding("Positive Review")
negative_review = get_embedding("Negative Review")
positive_example = get_embedding(
"The coffee at this cafe is exceptional, hardly disappointing.")
negative_example = get_embedding(
"The coffee at this cafe is disappointing, hardly exceptional.")
def get_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
positive_score = get_score(positive_example)
negative_score = get_score(negative_example)
print("Positive rating : %f" % (positive_score))
print("Negative rating : %f" % (negative_score))
结果
Positive rating : 0.040689
Negative rating : -0.116913
同样地,我们得到了正确的结果。
在较大的数据集上的真实示例
上述示例看起来运作良好。这可能是巧合吗?让我们采用真实数据集进行验证,并使用OpenAI嵌入式API进行情感分析,以查看是否可以获得预期结果。
以下代码是来自OpenAI Cookbook的一个示例。它使用相同的方法来评判亚马逊提供的一些食品的用户评价。在这个评价数据中,包括评价内容和用户对这些食品的星级评分。星级评分数据间接反映了我们的情感分析方法是否准确。我们将1-2星的评价视为负面评价,将4-5星的评价视为正面评价。
首先,我使用 Pandas 将这个带有 CSV 扩展名的数据集加载到内存中,为了避免不必要的 API 调用消耗,已经转换为嵌入向量的值会在这个数据集中保存,而无需重新计算。
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report
datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(np.array)
# convert 5-star rating to binary sentiment
df = df[df.Score != 3]
df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
对于每一条评论,我将使用先前的方法将其与预定义的“正面评论”和“负面评论”进行比较,然后查看哪个评论在与“正面评论”或“负面评论”的“距离”更接近。我在这里定义的“正面评论”和“负面评论”标签文本稍长,分别为“具有负面情绪的亚马逊评论。”和“具有正面情绪的亚马逊评论。”
计算出结果之后,我使用scikit-learn机器学习库来将预测值与实际的用户星级评价数据进行比较,然后输出比较结果。
from sklearn.metrics import PrecisionRecallDisplay
def evaluate_embeddings_approach(
labels = ['negative', 'positive'],
model = EMBEDDING_MODEL,
):
label_embeddings = [get_embedding(label, model=model) for label in labels]
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
probas = df["embedding"].apply(lambda x: label_score(x, label_embeddings))
preds = probas.apply(lambda x: 'positive' if x>0 else 'negative')
report = classification_report(df.sentiment, preds)
print(report)
display = PrecisionRecallDisplay.from_predictions(df.sentiment, probas, pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
结果:
precision recall f1-score support
negative 0.98 0.73 0.84 136
positive 0.96 1.00 0.98 789
accuracy 0.96 925
macro avg 0.97 0.86 0.91 925
weighted avg 0.96 0.96 0.96 925
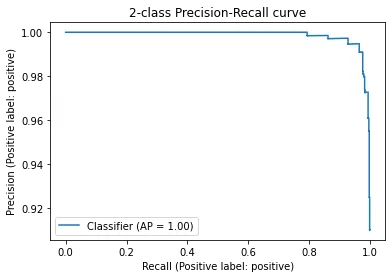
从结果来看,通过这种简单的方式来判定正面和负面评论,正面和负面的精确度分别达到了0.98和0.96,超过95%。
根据上图所示的召回率,即上图中的“召回”,对于负面评价的性能稍微差一些,仅为73%,这表明仍有相当数量的负面评价被判定为正面评价。然而,正面评价的召回率达到了100%,意味着模型找到了全部的正面评价。总体准确率为96%,在机器学习中被认为是非常高的。要实现这样的准确率,我们只需要调用开放API嵌入接口并添加几行代码来计算向量之间的相似度。
协同示例
Translate to Simplified Chinese
请点击以下链接以将下列英文文本翻译成简体中文:
翻译至简体中文链接Kaggle示例
You can use the following HTML structure to translate the English text to Simplified Chinese: ```html
AI审美 - 第二章
网址:https://www.kaggle.com/fenixping/ai-aesthetics-chap02
``` Please note that this is a basic example and you can modify the HTML structure according to your specific needs.GitHub 示例
在主分支上,将以下英文文本翻译为简体中文保持HTML结构:ai_aesthetics/chap02/chap02.ipynb at main · yipingw/ai_aesthetics (github.com)
如果你想学到更多知识,请关注我的书籍《ChatGPT人工智能掌握指南》。
📧 电子邮件:yipingw@outlook.com
🐦⬛ @yipingw 🐦⬛ @yipingw