让我们开始与人工智能对话吧
欢迎来到人工智能世界!我猜测ChatGPT的热潮已经吸引了你的注意力,既然你带着好奇心来到这里,我将满足你的需求!我们将从ChatGPT基础知识开始,然后在接下来的几堂课中探索OpenAI API以构建你的人工智能应用程序。在幕后,它们利用与ChatGPT相同的GPT-3.5语言模型。
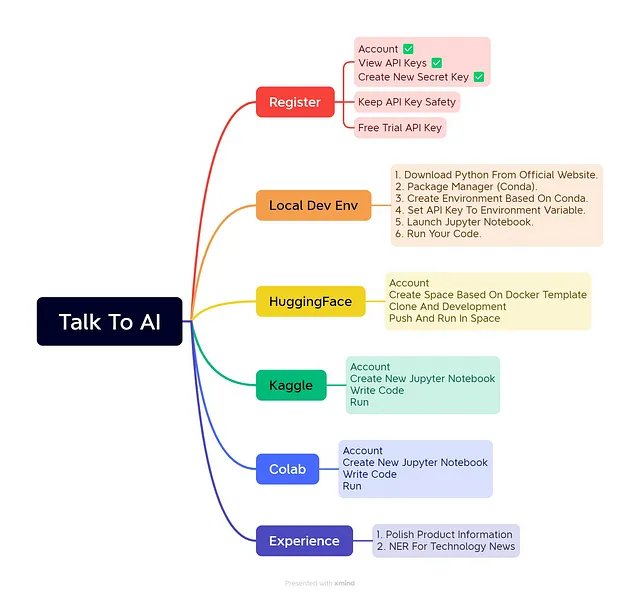
我们将使用公共数据和代码来演示利用大型语言模型的最佳实践。所以首先,让我们先介绍一下——没有必要购买昂贵的硬件来运行示例。无论您是产品经理,爱好者还是非工程师,HuggingFace、Kaggle和Google Colab提供的在线笔记本允许您在任何浏览器上运行所有操作。
这些 API 能够实现什么令人难以置信的成就?人工通用智能是如何定义的?GPT-3.5 等模型与过去的深度学习自然语言处理系统有何不同?我们还有很多内容需要揭示!
但首先,需要做一些准备工作 - 注册访问权限并设置环境。
获取OpenAI API密钥
要跟着操作,您需要一个帐户来访问OpenAI APIs - 您可以在这里注册。
一旦注册成功,在右上角展开账户菜单,选择API密钥,并创建一个新的密钥。
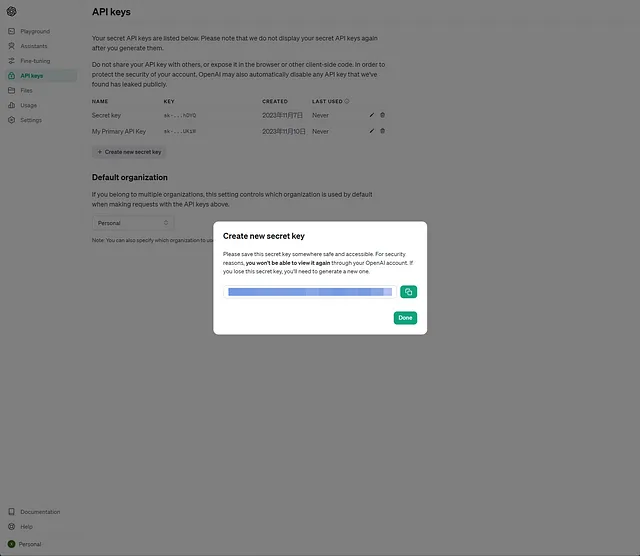
请务必将此安全存储以便稍后在 API 请求中使用。
免费服务层为本课程和初始实验提供5美元的使用额度。对于生产工作负载,请考虑升级到付费计划。
建立一个本地Jupyter Lab环境
通过使用API密钥,让我们建立一个开发环境。在整个课程中,我们将使用Python来演示应用人工智能。工程师可以从python.org安装最新的Python版本。Python 3.7将于2023年7月到达生命周期终点,所以现在推荐使用3.10版本。
为了隔离Python版本,使用Conda环境非常好。
我们将为Python 3.10创建一个,安装JupyterLab以及OpenAI和我们需要的其他库:
conda create --name chap1_talk_to_ai python=3.10
conda activate chap1_talk_to_ai
conda install -c conda-forge openai
conda install -c conda-forge jupyterlab
conda install -c conda-forge ipywidgets
熟悉以下命令 - 我们将进一步使用Conda/pip来添加更多的软件包。
在安装JupyterLab后,将API密钥设置在环境变量中并启动。这些交互式笔记本可以运行代码,亲身体验OpenAI的API。
export OPENAI_API_KEY=PUT_YOUR_API_KEY_HERE
jupyter-lab .
随意开始一个新的Python 3的笔记本来调用API。
通过HuggingFace执行示例
假设你拥有一个HuggingFace账户,在“Spaces”下:

点击“创建新空间”
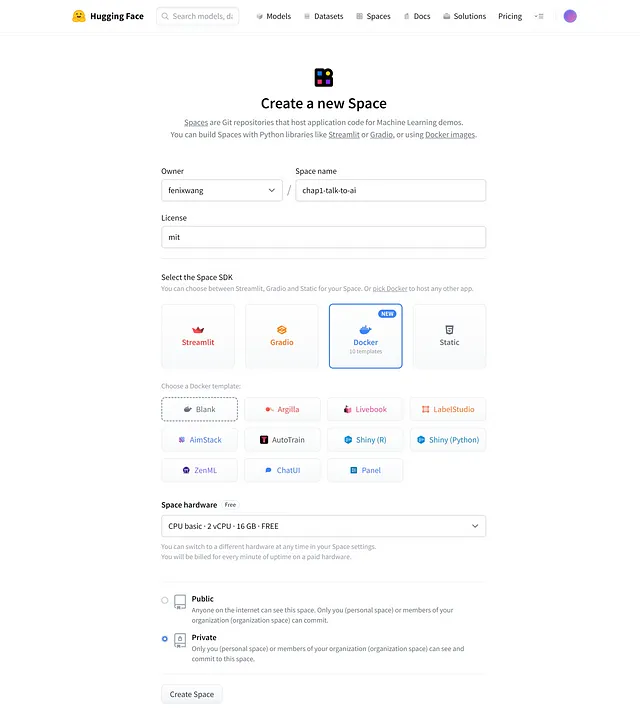
填寫:
姓名:chap1-talk-to-ai
许可证:MIT
SDK:Docker(空模板)
硬件:免费CPU层级
访问:公开或私密
一旦创建好,就在本地克隆该空间。HuggingFace提供了一个初始代码来初始化Docker项目。最后,提交并推送更改。
克隆空间
# HTTPS
git clone <https://huggingface.co/spaces/fenixwang/chap1-talk-to-ai>
# SSH
git clone git@hf.co:spaces/fenixwang/chap1-talk-to-ai
在本地创建一个Dockerfile文件,并粘贴模板。
# read the doc: <https://huggingface.co/docs/hub/spaces-sdks-docker>
# you will also find guides on how best to write your Dockerfile
FROM python:3.10
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY . .
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "7860"]
提交并推送以与HuggingFace同步
git add Dockerfile
git commit -m "Add application file"
git push
使用Kaggle笔记本
使用Kaggle账号:点击“+ 创建”并启动Jupyter笔记本。
在第一个代码块中安装库。
!pip install openai
然后在第二个区块中调用API,并运行全部。
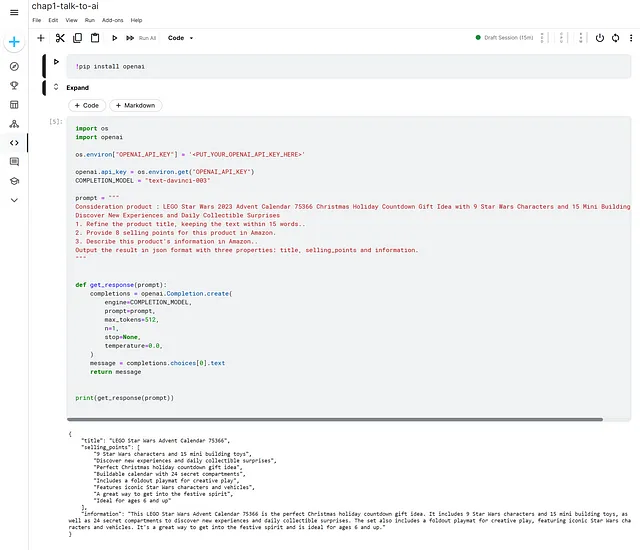
我们可以看到OpenAI的回应。
使用Colab与Jupyter Notebooks
首先,使用您的Google账号登录Colab。然后,在主页上,点击“新笔记本”按钮创建一个新的笔记本:
就像我们之前在Kaggle部分讲的那样,我创建了两个代码块并且提供了相同的代码。
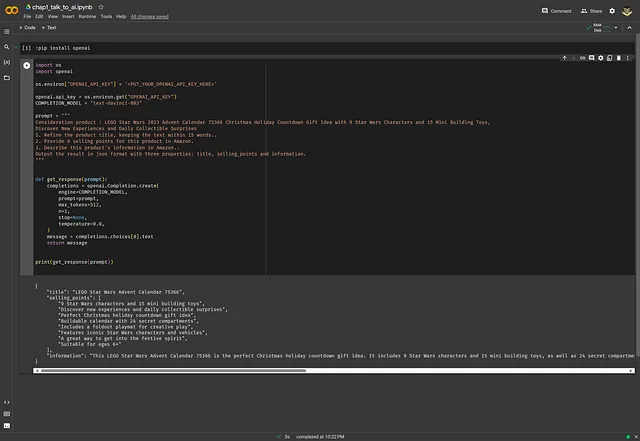
点击顶部菜单栏中的“运行时 → 运行全部”,或使用快捷键 Ctrl + F9 运行所有代码块。
我们得到了和之前一样的结果。您可以在这里查看完整的示例。
编码时间
接下来是令人激动的编码部分!整个项目结构如下:
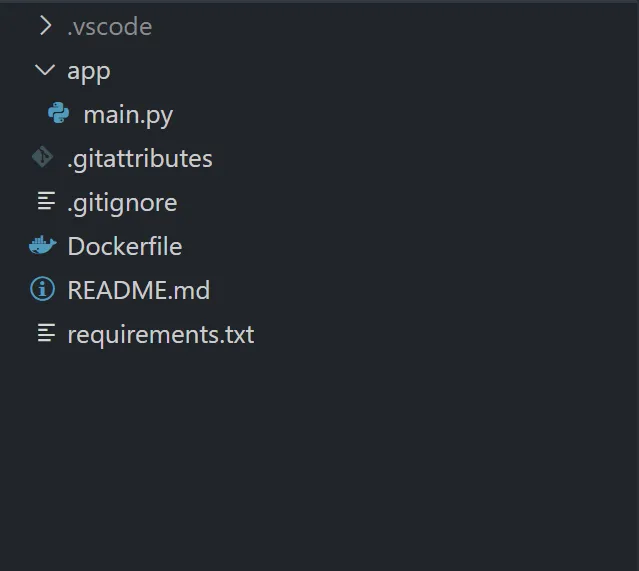
在项目中,我创建了一个 requirements.txt 文件来管理使用的Python包。
fastapi==0.104.0
uvicorn==0.23.2
openai==0.28.1
然后,在应用程序路径下,我创建一个名为main.py的代码文件,并将以下代码粘贴到其中,记得将你的API密钥替换为
from fastapi import FastAPI
import os
import openai
import json
app = FastAPI()
# notice: replace <PUT_YOUR_OPENAI_API_KEY_HERE> to your API Key
os.environ["OPENAI_API_KEY"] = '<PUT_YOUR_OPENAI_API_KEY_HERE>'
openai.api_key = os.environ.get("OPENAI_API_KEY")
COMPLETION_MODEL = "text-davinci-003"
prompt = """
Consideration product: LEGO Star Wars 2023 Advent Calendar 75366 Christmas Holiday Countdown Gift Idea with 9 Star Wars Characters and 15 Mini Building Toys,
Discover New Experiences and Daily Collectible Surprises
1. Refine the product title, keeping the text within 15 words..
2. Provide 8 selling points for this product in Amazon.
3. Describe this product's information in Amazon..
Output the result in json format with three properties: title, selling_points and information.
"""
def get_response(prompt):
completions = openai.Completion.create(
engine=COMPLETION_MODEL,
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.0,
)
message = completions.choices[0].text
return message
@app.get("/")
def read_root():
return {"message": json.loads(get_response(prompt))}
现在,您可以在本地执行代码。打开终端并运行以下命令以安装项目依赖项:
# install dependencies
pip install -r requirements.txt
接下来,运行以下命令来启动一个监听根路径并返回OpenAI API结果的网络服务:
uvicorn app.main:app --host 0.0.0.0 --port 7860
最后,打开你的浏览器并输入http://localhost:7860。你将会看到下面返回的结果:
{
"message": {
"title": "LEGO Star Wars Advent Calendar 75366",
"selling_points": [
"9 Star Wars characters and 15 mini building toys",
"Discover new experiences and daily collectible surprises",
"Perfect Christmas holiday countdown gift idea",
"Buildable calendar with 24 secret compartments",
"Includes a foldout playmat for creative play",
"Features iconic Star Wars characters and vehicles",
"A great way to get into the festive spirit",
"Ideal for ages 6 and up"
],
"information": "This LEGO Star Wars Advent Calendar 75366 is the perfect Christmas holiday countdown gift idea. It includes 9 Star Wars characters and 15 mini building toys, as well as 24 secret compartments to discover new experiences and daily collectible surprises. The set also includes a foldout playmat for creative play, featuring iconic Star Wars characters and vehicles. It's a great way to get into the festive spirit and is ideal for ages 6 and up."
}
}
完整的项目代码可以在我的HuggingFace Space页面上查看。
在这一点上,你一定有很多问题。在这个例子中,我列举了需求,OpenAI可以根据我的提示返回我所需的信息。最令人难以置信的是,它基于我的关键词提示返回了结构良好的JSON数据。让我们逐一揭示答案。
首先,此产品是从亚马逊的玩具和游戏类别中随机选择的
在上面的代码中,我调用了OpenAI的Completion接口,然后提出了三个请求:
- 我希望将原始产品标题长度缩短为15个字。
- 为该产品提供八个销售特点。
- 最后,提供关于产品的总结信息。
最后,我还告诉OpenAI希望返回的格式是JSON,其中上述三个要求由键title、selling_points和information表示。
OpenAI完全理解了我的需求,并返回了符合我的标准的JSON字符串。在此过程中,它完成了几个非常不同的任务:
第一步是按照要求重新命名产品标题。
第二个是理解语义并生成相关的回应,返回我规定的销售要点数量。
第三点是提供简洁的产品描述。
如果你觉得这难以置信,我们来看另一个例子。
prompt = """
One of the most useful benefits to having an Apple Watch is its ability to ping your iPhone. Phones are notoriously easy to misplace, forcing you to waste time searching for them when you're just about to head out the door. Fortunately, the Apple Watch has a button you can press that causes your iPhone to make a noise so you can find it.
This Apple Watch feature is relatively well-known. What's less well-known is that you can also make your lost iPhone flash its light to help you find it more quickly. This feature was originally intended to help people who are deaf or hard of hearing locate their phones, but there's no reason everyone else can't benefit from it as well.
Please use typical NER to tag entities in the above paragraph and return them as a JSON object.
"""
print(get_resp(prompt))
{
"entities": [
{
"text": "Apple Watch",
"type": "Product"
},
{
"text": "iPhone",
"type": "Product"
},
{
"text": "Apple Watch",
"type": "Product"
},
{
"text": "iPhone",
"type": "Product"
},
{
"text": "deaf or hard of hearing",
"type": "Group"
}
]
}
我提供了一段科技新闻文本,然后使用基于人工智能技术的命名实体识别(NER)按照我的标准提取和注释实体。正如您所看到的,返回的结果完全满足我的要求——从新闻片段中提取和标记实体。
在这两个示例中,有很多工作是在幕后完成的,包括文本生成、推理、NER等等。在传统机器学习中,这些功能都需要一个独立的模型。创建一个单一模型来提供这些功能意味着要实现一个复杂的多任务学习架构,这是一个非常复杂的工程壮举,对于任何小于数十人的团队来说都是难以企及的。
OpenAI尚未透露GPT-3.5或GPT-4模型的参数计数。可用的第三方估计显示,GPT-3.5具有1750亿个参数,而GPT-4具有1万亿个参数。GPT-3.5的上下文窗口为4096个标记,而GPT-4的为8192个标记。更多的参数可以理解为更大的知识容量和多样性的回应。更大的上下文窗口支持需要持续上下文的对话场景的更长连续性。
总结
到目前为止,我相信您已经对OpenAI的能力有了一些直观的理解。您的账户和API密钥也应该已经准备就绪。无论是在本地运行还是使用像Colab和Kaggle这样的在线平台,您都尝试过执行或修改源代码并查看输出结果。
OpenAI的GPT-3.5大型语言模型使您能够使用此单一模型处理任何自然语言处理任务,而无需训练专门的模型或对其进行针对特定任务的微调。过去,我们不得不训练各个独立模型,有时还要进行特定应用的定制调整。但在大型语言模型时代,这已不再必要。这极大地降低了利用人工智能解决问题的门槛。无论以往的自然语言处理工具或框架有多方便,构建一个良好运行的系统仍需要团队的专业主题专家。还有有效结合模型和准备大量训练数据的挑战。
使用大型语言模型时,我们只需要学会“提问”来开发“智能”产品。这就是本书的目的。
如果你想了解更多信息,请关注我的书籍《ChatGPT的人工智能掌握指南》。
📧 yipingw@outlook.com 📧 yipingw@outlook.com
🐦⬛ @一平武