Gen-AI(VilimiAI)RAG与知识图谱
通过链接实体、提取关系并整合外部数据库进行丰富化,构建一个语料库和医疗知识图谱。
实时应用程序:https://knowledge.vilimin.com/
👨🏾💻 领英 ⭐️| 🐦 Vilimin.com | ❤️ViliminGPT.com

一个知识图谱(KG),或任何图谱,由节点和边组成,其中每个节点表示一个概念,每个边表示两个概念之间的关系。本文介绍一种将任何文本语料库转化为知识图谱(GK)的技术,该术语与本演示的上下文中的KG可互换使用,以更好地传达概念。
实时原型

知识图谱
一个知识图谱封装了两个实体之间关系的本质。在这个结构中,节点代表人、地点或事件等实体,而边表示这些实体之间的连接。知识图谱的独特之处在于它们包含了第三个元素,通常称为谓词或边标签,用来描述关系的性质。
一个知识图谱,就像一个智能网络一样,展示了现实世界中事物的连接方式。它存储在图数据库中,并以图形结构进行可视化,形成我们称之为“知识图谱”的样式。用户可以与图形数据进行即时聊天机器人对话。
知识图谱发挥着各种目的。通过应用图算法,我们可以计算任何节点的中心度,从而洞察一个概念在某一工作领域中的重要性。分析连接和未连接的概念集,或者确定概念群体,能够提供对主题的全面理解。知识图谱使我们能够发现 seemingly unrelated 概念之间的联系。
此外,知识图谱可以用于图检索增强生成(GRAG或GAG),并促进与文档的对话交互。与常规版本的RAG相比,这种方法通常能产生更好的结果,因为常规版本存在固有限制。例如,仅依靠简单的语义相似度搜索来进行上下文检索并不总是有效的,特别是当查询缺乏足够的上下文或相关信息分散在大量文本语料库中时。
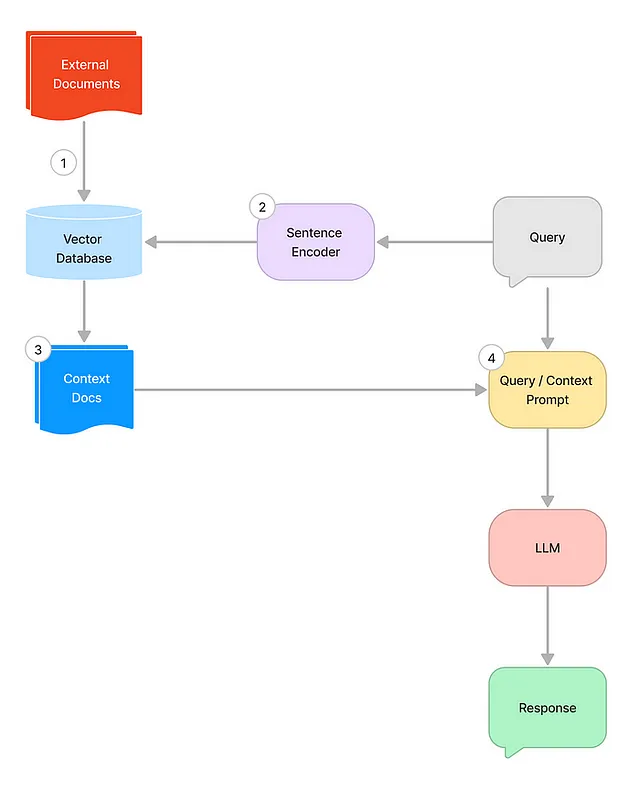
高级RAG架构
- 填充一个向量数据库,其中包含编码的文档。
- 将查询转换为向量,使用句子转换器。
- 从向量数据库中根据输入的查询检索相关上下文。
- 使用查询和检索到的上下文来激发LLM。
RAG的限制
RAG的一个主要缺点是在提供复杂和微妙查询的精确回答方面存在困难。这一限制源于几个因素:
- 理解用户意图:RAG系统可能难以完全把握用户查询背后的确切意图,这对于向LLM提供准确信息至关重要。
- 依赖于向量嵌入:RAG在解释和匹配查询与相关信息时严重依赖于向量嵌入。虽然这些嵌入具有强大的能力,但它们并非十全十美,有时可能会导致不准确或过度简化对查询上下文的理解。
- 黑盒子式自然:生成和比较向量嵌入的过程是复杂而且通常缺乏透明度的。考虑到嵌入可能具有的众多维度,解析其结构并理解其对语义搜索中相似度得分的影响是一个挑战。
- 通用训练数据:嵌入模型通常在通用数据集上进行训练,可能会缺乏某些查询所必需的特定细微差别或背景。这可能导致在不同的内容片段之间绘制出肤浅的相似之处。
知识图谱的类型
- 百科知识图谱:这种常见类型通过整合来自百科全书、数据库和专家见解等各种信息源来捕获普遍知识。例如,Wikidata从维基百科文章中汇编了广泛的知识,形成了跨多种语言的庞大而多样化的知识图谱,包含数百万个实体和关系。
- 常识知识图谱:以日常知识为重点,这些知识图谱包含有关对象、事件及其关系的信息。它们有助于理解我们日常生活中使用的基本、常常隐含的知识。例如,ConceptNet包括常识概念和关系,帮助计算机更自然地理解人类语言。
- 领域特定的知识图谱:针对诸如医学、金融或生物学等特定领域,这些知识图谱较小而且高度精准可信。例如,在医学领域中,UMLS包含详细的生物医学概念和关系,以满足专业知识需求。
- 多模态知识图谱:超越文本,这些知识图谱包含图片、声音和视频,用于实现例如图片文本匹配或视觉问答等功能。像IMGpedia和MMKG这样的示例无缝融合了文本和视觉信息,为全面的知识表示提供了支持。
搜索引擎的使用案例
在搜索引擎领域中,知识图谱对于提高搜索精度和相关性至关重要。通过理解知识图谱中嵌入的关系和上下文,搜索引擎能够超越仅仅关键词匹配,深入到用户查询背后的意图和深层含义。这种进化使得搜索结果不仅更直观,还能与上下文相适应,从根本上改变我们在线获取信息的方式。

该应用的业务架构
数据来自多个渠道,涵盖了非结构化数据、平面文件以及使用XML或JSON数据库、传统SQL数据库等结构化数据。这些多样化的数据通过多个系统进行处理,以提取实体和关系,这些是知识图谱的关键组成部分。与传统的ETL等方法不同,现在有一种转向利用生成性AI的趋势。这种先进的方法不仅自动提取实体和关系,还生成Neo4j的密码语言查询。结果是这些元素自动集成到Neo4j数据库中,表示在图表的左侧。

在光谱的另一端,客户展示了由生成式人工智能生成的知识图谱。通过具备文本界面的Web应用程序,用户可以提出查询。生成式人工智能通过将这些问题转换为数据库查询语言Cipher来实现。查询被执行并从数据库中获得结果,然后经过另一轮生成式人工智能处理将其转换回自然语言。
在中间层,图数据库将根据语料数据生成基于概念图的模式,使用节点和边。当您连接这些元素时,您可以看到以下节点和边的关系。

构建知识图谱
有四个步骤参与,如下所示,但这会根据业务需求和使用情况而有所不同。
- 识别和捕捉内容中的概念和实体。这些元素代表系统中的节点。
- 揭示已确定概念之间的关系,形成结构的框架。
- 用已识别的节点(概念)和边缘(关系)填充一个图数据结构或图数据库。
- 将构建的图表视觉化,既可以得到分析洞察力,又能够带来艺术享受的潜力。
下面给出了语料库数据流程图,这个流程将根据您使用的数据库模型而有所不同。例如,如果您使用图形数据库和数据科学数据库,数据将存储在后端系统中。如果您使用的是内存占位符,您可以使用Pandas数据框等。
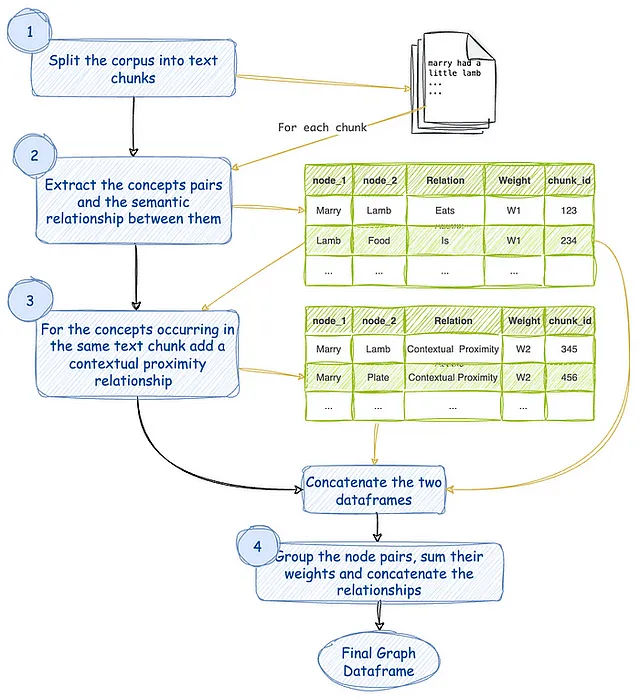
在初始阶段,文本语料库经过分词处理,每个分词片段被分配一个独特的块标识符(chunk_id)。随后,使用语言模型(LLM)从每个文本块中提取概念及其语义关系,并为这些关系赋予权重W1。需要注意的是,同一对概念之间可能存在多个关系。
随后,同一文本块中的上下文接近性被考虑,与概念之间的另一个关系以权重W2建立起来。这种识别也适用于同一概念对在不同块中出现的情况。为了简化数据,类似的对会被分组,它们的权重被求和,并且它们的关系被连接起来。结果是一个整合的表示,每个不同概念对都有一个单独的边,包括一个特定的权重和关系列表作为它的标识符。
现在让我们将这个GenAI模型运行通过输入数据框的每个文本块,并将json转换为Pandas数据框,这是它的样子。

如果您正在使用后端数据库,则实体如下:

每一行在这个表示中表示了两个概念之间的关系,作为连接我们图中的两个节点的边。同一对概念之间可能存在多个边或关系。提供的数据框中的计数被任意设置为4,表示权重。
将知识图谱与LLM-RAG集成
保持HTML结构,将以下英文文本翻译为简体中文: 知识图谱(KG)与大型语言模型(LLM)的融合有望大幅提升检索增强生成(RAG)过程,并改进知识表示和推理。这种协作方法有助于实现动态知识融合,确保真实世界的知识与文本空间保持当前和独立。因此,推理过程中提供的信息始终是最新和相关的。
动态知识融合
考虑将知识图谱(KG)视为动态数据库,供大型语言模型(LLMs)查询最新和相关信息。这一方法在诸如问题回答等需要保持最新的任务中非常有效。通过先进的架构,将此知识与LLMs集成在一起,实现了文本令牌和KG实体之间的深入交互。这使LLMs的回应得以丰富,结构化和确凿的数据提升了生成信息的质量。
KG强化RAG
将知识图谱(KGs)应用于提升关联数据生成(RAG)技术,涉及在知识图谱中搜索相关事实,并将其作为背景信息呈现给LLMs。这种方法能够为生成精确、多样化和事实准确的内容提供支持。例如,当LLM被要求就最近发生的事件进行回复时,它可以首先查阅知识图谱获取最新的事实,然后再进行回复的构思。
此外,LLMs在编写高质量文本方面也非常重要,能够准确描述知识图谱信息。这对于生成真实的叙事、对话和故事具有巨大潜力。无论是利用LLMs的知识还是构建庞大的知识图谱-文本语料库,这个过程都显著增强了知识图谱到文本生成的能力,特别是在训练数据有限的情况下。
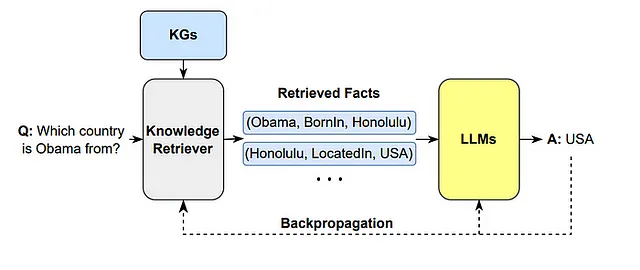
与LLMs和KGs进行推理
LLMs和KGs在推理任务中的协同影响变得显而易见。利用LLMs解释文本问题并促进对KGs的推理建立了文本和结构信息之间的连接,增强了可解释性和推理能力。这种连贯的方法在各个领域都有应用,从对话系统中的个性化推荐到通过融入领域知识图谱来加强任务特定的训练过程。
图形可视化
可视化阶段为这个练习增添了一种令人愉悦的维度,提供了独特的艺术满足感。我们已经确定了边权重以影响其粗细,给节点社区分配了颜色,并确定了节点度以确定其大小。
实时原型
通过页面底部的滑块面板,探索缩放、操作节点和边缘以及调整图形物理效果的灵活性。见证这个动态图形如何促进洞察问题的提出并增强对主题的理解能力!
结论
知识图谱在需要混合结构化和非结构化数据来支持RAG应用时证明非常有效。本博客文章将指导您如何使用Graph DB和GenAI函数构建知识图谱,适用于语料库、医疗或任何文本。来自GenAI/模型函数的整洁结构化输出使它们成为提取组织化信息的理想选择。为了在图构建中获得最佳体验,请详细定义图模式,并在提取后加入实体消歧步骤。希望我们的RAG KG图能够支持图增强检索的开发,为整个RAG流程的改进做出贡献。
将知识图谱(KG)融入到检索增强生成(RAG)系统具备巨大的潜力。通过利用知识图谱中结构化且相互关联的数据,我们能够大幅提升现有RAG系统的推理能力。这种强大的融合有望减轻当前RAG流程固有的限制,并提供更准确、具有上下文意识和更细致的响应。
KG(知识图谱)作为对LLM(语言模型学习者)可访问的大量信息的强大储备,不仅能帮助其检索事实,还能理解与这些事实相关联的关系和潜在背景。这种提升的理解水平对于推动具备更有效用户互动能力、提供不仅相关而且深度洞察的信息的AI系统的发展至关重要。
请通过👨🏾💻 领英 进行进一步的发展沟通。