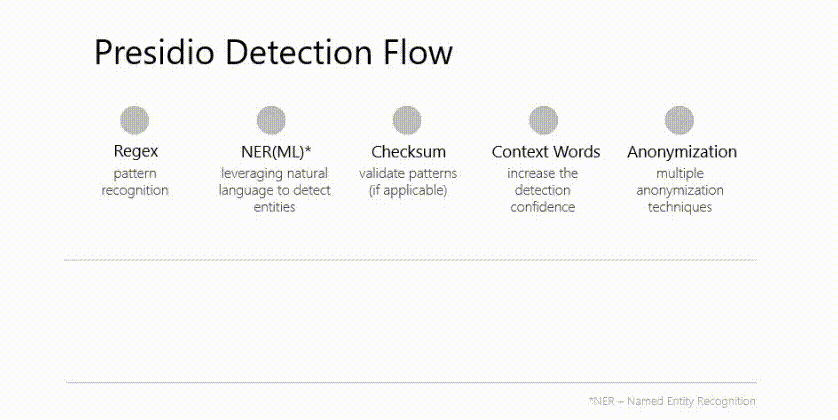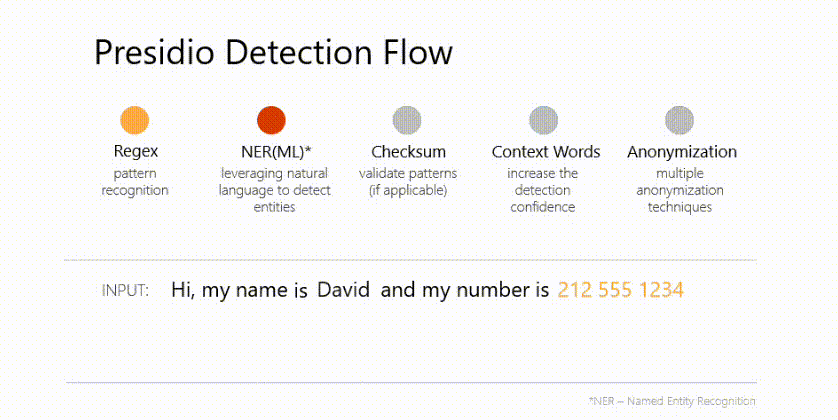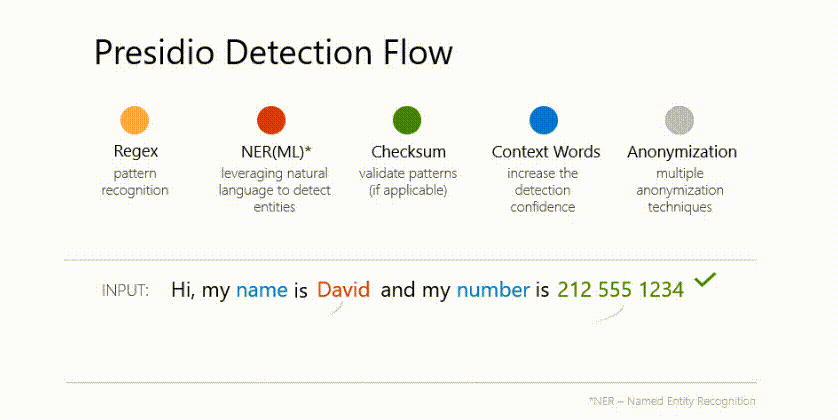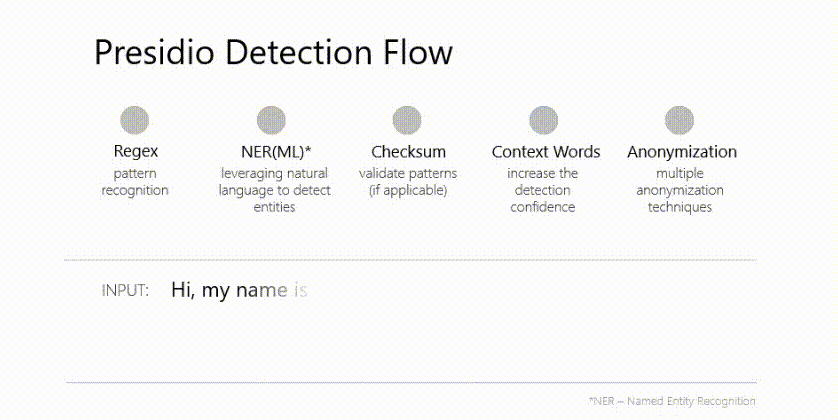
LLM基准测试:评估2024年的LLMs

但是在所有这些案例中,大型语言模型(LLM)普遍存在一些非常有缺陷的行为。
- 一些提示会导致LLMs产生一些无意义的输出,被称为“越狱提示”。
- LLMs并不总是事实正确的,这也被称为“幻觉”现象。
- LLMs可能会展示出对消费者使用来说是不安全的意外行为。
显然仅仅训练LLM是不够的。因此,问题出现了:我们如何确信LLM 'A'(具有'n'个参数)比LLM 'B'(具有'm'个参数)更优秀?或者基于可量化、合理的观察,LLM 'A'比LLM 'B'更可靠吗?
需要有一个标准来评估LLMs,确保它们在道德上可靠且表现良好。虽然已经对基准测试进行了很多研究(这将在本文的后面部分讨论),但仅仅进行研究也不足以满足实际生产需求。对于LLMs和LLM应用程序来说,一个可扩展的、接近实时的评估基础设施也非常重要。(这里有一个关于LLM评估的很好介绍)
本文提供了对当前LLMs评估研究的概述,以及在该领域中一些杰出的开源实现。在这篇博客中,您将了解到:
- 场景、任务、基准数据集和评价指标
- 当前关于基准线学位法(LLM)的研究以及目前存在的问题
- LLM基准评估的最佳实践
- 使用DeepEval来执行评估最佳实践
场景,任务,基准数据集和度量
“场景”,“任务”,“基准数据集”和“评价指标”是评估领域中经常使用的一些术语,因此在继续之前,了解它们的含义非常重要。
情境
一个场景是一个广泛的上下文/设置或LLM性能被评估或测试的条件。例如:
- 问题回答
- 推理
- 机器翻译
- 文本生成和自然语言处理。
任务
与其听起来的简单一样,任务可以被认为是场景的更精细化形式。它更具体地描述了LLM评估的基础。一个任务可以是很多子任务的组合(或集合)。
例如,算术可以被视为一个任务。它明确提到它评估算术问题上的 LLMs。在此下面,可以有许多子任务,如算术一级、二级等等。在这个例子中,所有的算术子任务(从一级到五级)构成了算术任务。
同样地,我们可以将多项选择作为一个任务。在此之下,我们可以有有关历史、代数等的多项选择,作为所有子任务。
公制
度量标准可以被定义为用于评估语言模型在某些任务/场景上的表现的定性分析指标。度量标准可以是简单的:
- 确定性统计/数学函数(例如,准确度)
- 或者由神经网络或机器学习模型产生的评分。(例如,BERT评分)
- 由LLMs自身生成的分数(例如,G-Eval)。
这是各种指标类型的简要概述:
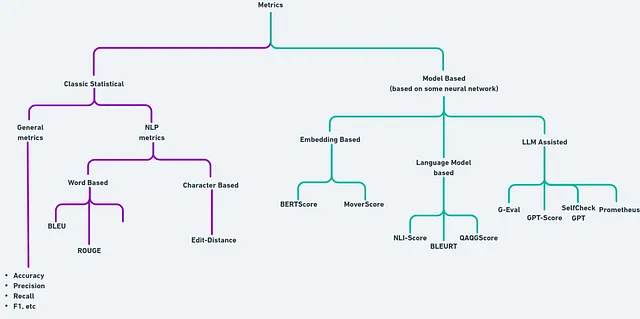
上述图表尝试简化LLM评估中使用的不同类型指标的分类体系。指标还可以是不同原子/粒度指标的组合。一个非常简单的例子是F1得分,它是精确度和召回率的调和平均数。
同样地,在自然语言处理中,BLEU(双语评估协助)分数是由准确性、简洁惩罚和N-gram匹配组成的。如果您愿意,您也可以结合不同的指标来得出一个新的指标。
基准数据集
一个基准数据集是一组用于评估在给定任务或场景中的LLMs的标准化测试集合。以下是一些例子:
- 问答式SQuAD
- GLUE(语言理解与问答)
- 用于情感分析的IMDB
在后面的部分中,大多数情况下你会看到,一个场景通常包含许多基准数据集。一个任务可能由许多子任务组成,每个子任务又可以由一堆数据集组成。但是,它也可以只是一个包含某个基准数据集的任务。
当前用于基准测试LLMs的研究框架

在这个部分,我们将看一些基准测试框架及其提供的功能。请注意:目前在命名约定方面还没有标准化。第一次理解时可能会感到非常困惑,请耐心等待。
语言模型评估工具(由EleutherAI开发)
语言模型评估工具提供了一个统一的框架,在大量的评估任务中对语言模型进行基准测试。我有意地强调了任务这个词,因为在Harness中没有情境这个概念(我将使用Harness代替语言模型评估工具)。
在Harness下,我们可以看到许多任务,其中包含不同的子任务。每个任务或一组子任务对LLM在生成能力、不同领域的推理等方面进行评估。
每个任务下的子任务(有时甚至包括任务本身)都有一个基准数据集,并且这些任务通常与评估方面的重要研究相关联。Harness致力于将所有这些数据集、配置和评估策略(如与评估基准数据集相关的指标)统一和结构化到一个地方。
不仅如此,Harness还支持不同类型的LLM后端(例如:VLLM,GGUF等)。它使得更改提示和进行实验具有极大的可定制性。
这是一个小例子,展示了如何轻松评估 Mistral 模型在 HellaSwag 任务上的表现(这是一个评估 LLM 通识能力的任务)。
lm_eval --model hf \
--model_args pretrained=mistralai/Mistral-7B-v0.1 \
--tasks hellaswag \
--device cuda:0 \
--batch_size 8
灵感来自LM评估工具包(LM Evaluation Harness),BigCode项目还推出了另一个名为BigCode Evaluation Harness的框架,它尝试提供类似的API和CLI方法,专门用于评估LLM(语言模型)在代码生成任务中的表现。由于代码生成的评估是一个非常特定的主题,我们可以在下一篇博客中讨论这个问题,所以请继续关注!
斯坦福大学HELM
HELM或整体语言模型评估使用"场景"来概述可以应用LM的地方,并使用"指标"来详细说明我们希望LLM在基准测试环境中做什么。一个场景由以下部分组成:
- 一个与场景相符的任务 (保持HTML结构)
- 一个域(由文本的类型,作者和写作日期组成)
- 语言(即任务所使用的语言)
HELM然后试图根据社会关联性(例如,考虑用户界面应用的可靠性的场景)、覆盖范围(多语言)、以及可行性(即,选择计算出的最优显著子集的评估,而不是逐个运行所有数据点)对一部分场景和指标进行优先排序。
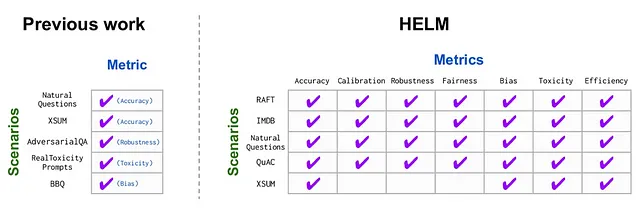
不仅如此,这个HELM还试图覆盖一组7个指标(准确性、校准性、鲁棒性、公平性、偏见、有毒性和效率),几乎适用于所有场景,因为仅靠准确性无法提供对LLM性能的最高可靠性。
PromptBench(由Microsoft提供)
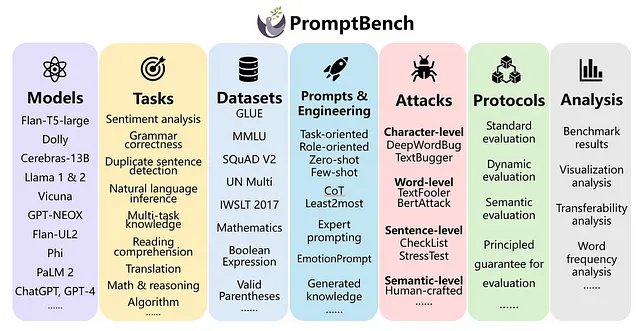
PromptBench是另一个用于LLM基准测试的统一库。它与HELM和Harness非常相似,支持不同的LLM框架(例如:Hugging Face、VLLM等)。与其他框架的不同之处在于,除了仅评估任务外,它还支持评估不同的提示工程方法,并在不同的提示级对抗攻击上评估LLMs。我们还可以构建不同评估的流水线,从而使生产级用例更容易。
ChatArena(由LMSys开发)
与以往的基准测试框架不同,这个框架尝试以不同的方式来解决基准测试问题。这个基准测试平台通过特定的提示和用户投票,匿名而随机地对不同的LLM进行对比,以决定哪个LLM(保持匿名)做得更好。
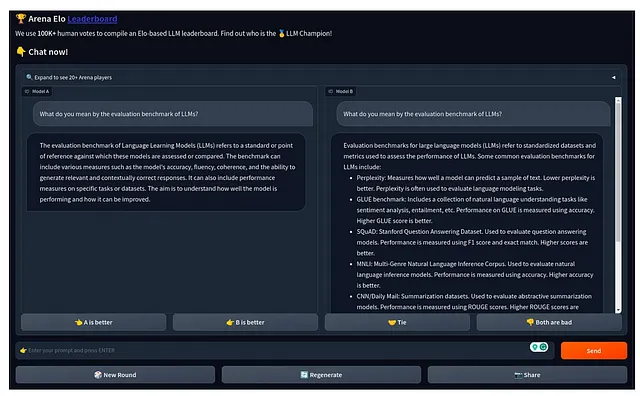
正如您在上面的图像中所看到的,您可以从您的提示和两个匿名的LLM(模型A和B)开始。这两个模型都会给出一些答案,然后您可以选择哪个模型表现更好。非常简单直观,没有花哨的东西。然而,它非常出色地量化了LLM的性能。通过最大似然估计Elo(MLE-Elo)评分(又称Bradley-Terry模型),完成了比较的量化。
LmSys还提供了一个排行榜,根据MLE-Elo评级,对不同专业的LLM进行排名。您可以在这里查看。
尽管如此,对于基准测试LLM仍然存在问题。
到目前为止,我们深入研究了一些令人惊叹的研究以及它们的各种实施方法。我们学到了:
- 如何框架(如Harness和HELM)衍生出不同的分类法来组织评估任务的结构。
- 像 Chatbot Arena 这样的开源平台如何简化 LLMs 的基准测试。
- 像 PromptBench 这样的实现更加专注于生产场景(如提示注入攻击或对抗性攻击)。 保持 HTML 结构,将以下英文文本翻译为简体中文: 像 PromptBench 这样的实现更加专注于生产场景(如提示注入攻击或对抗性攻击)。
然而,这些系统由许多不同的移动组件组成,如向量数据库、不同LLM工作负载(也称为代理)、提示工程、用于精调的数据等等,管理起来非常繁琐。
另一个问题是研究和生产评估的区别。迅速构建和优化LLMs,并投入生产是一项并不容易完成的任务。除了忽视成本和推理优化之外,生产级评估基础设施也是另一个重要的瓶颈。让我详细解释一下。
正如我们都可以认同的那样,测试是传统快速软件开发的重要组成部分(例如,在Python中,PyTest在测试中扮演着重要的角色),并且在将更新的软件运送到CI/CD流水线之前使用,从而使开发过程变得高效可靠。
然而,我们没有用于LLMs的类似Pytest的测试基础设施。即使我们有类似的东西,LLMs是概率机器,这使得定义确定性测试案例是不足够的。实时的全面测试和压力测试(红队测试)也是重要的。但是,目前在规模上也没有这种类型的东西,这阻碍了建立生产级别的通用人工智能产品的过程。
由于需要持续微调LLMs,以后会用于开发LLM系统(例如基于RAG的系统),因此您需要的基础设施有:
- 在微调过程中同时评估
- 评估测试的前/后期案例
- 红队测试/压力测试和大规模的LLM和LLM系统的A/B测试。
- 用于LLMs的数据的评估和更正。
现在到了这个点,如果你认为简历或者HELM可能非常有用,那么你既对又不对。虽然HELM和简历为用户在评估LLM方面带来了巨大的飞跃,但是所有这些库都有影子接口(API接口在文档中没有明确说明)并且主要使用或者通过CLI执行,这对于快速原型设计模型来说并不理想。
最后,我们可能需要非常特定领域的评估,这超出了当前基准测试框架的范围。编写这些评估应该和为PyTest编写测试用例一样容易,对于基准测试LLMs也是如此,而这些框架目前不支持。
LLM 法学硕士标杆案例的最佳实践
虽然整个领域仍然非常新,但我们正在看到一个新兴趋势,即从业者主要将LLM用于非常具体的用例,例如文本摘要、内部知识库的问答和数据提取。在大多数情况下,LLM需要在其忠实度上进行基准测试,同时它们还需要在将要部署的领域中进行准确度的基准测试。
那么,一个典型的开发生命周期:
- 从现有的开源LLM或闭源LLM开始。
- 将您的LLM适应到所需的用例中。我们可以通过进行一些提示工程(如思维链或使用上下文学习)或使用RAG中的向量数据库来提供更多的上下文来实现这一点。我们可以对LLM进行微调,并与之前的方法一起使用,以充分发挥LLM的性能。
- 使用额外的LLM警栏投入生产,并将其与后端服务器连接以获取数据作为其输入。
以上一组过程可以分为两个阶段。
- 预生产评估。
- 后期制作评估。
前期评估
在这个初步探索阶段,我们可以尝试以下每种组合:
- LLM + 提示工程(如CoT或上下文学习)。
- LLM + 提示工程 + RAG
- 通过微调LLM +启发式引擎+ RAG等方法效果最佳。
由于与LLMs合作是一项昂贵的业务,我们需要在成本和质量之间保持完美的平衡。因此,实验是这个过程的一个重要组成部分。我们还需要拥有适当的评估基础设施, 包括:
- 可以对不同的提示评估LLMs,并有一个地方可以对哪些提示组合效果最好进行排名。
- 可以在基于RAG的使用情况中评估检索引擎(由检索模型组成),以了解在提供给LLM之前检索的上下文是否准确无误。
- 可以评估不同的微调检查点(在微调LLM时进行的检查点),并评估哪些检查点效果最好。
- 可以从HELM或Harness获取一些标准化得分(即来自于它们的标准化基准数据集,该数据集属于目标领域)。这很重要,这样我们就可以拥有一个评估评分卡(与模型卡或数据集卡非常相似),这是通用且正在标准化的。
- 可以评估一个特定领域的自定义专有基准数据集,以确保我们对LLM在生产过程中将会遇到的相似数据的性能能有完全的把握。
- 可以通过评估LLMs的可靠性(即LLMs不能有毒或不忠实,也不能诱发高度劫持等)来确定其准确性(即LLM的事实正确性如何)。
- 可以评估不同的流水线(如上述组合中所提到的)以了解哪种流水线组合效果最佳。
- 最后但同样重要的是,在投入生产之前,对LLM进行严格的红队测试是非常必要的(特别是针对基于聊天的模型)。
后期制作评估
一旦部署了LLMs,将LLM流水线投入生产后,以下是可以采用的一些非常重要的最佳实践:
- 持续监控LLM应用程序是非常重要的,这样我们就能够为LLM应用程序的不满意输出维护准实时更改系统。这也有助于轻松理解出错的原因并进行修复。
- 明确的反馈,诸如指标(例如,用户的赞/踩评级)可以提供对LLM生成的反馈。
- 支持LLM的持续微调(以及RAG应用中使用的嵌入模型)和持续部署以维持以客户为中心的生成,否则应用可能面临最终的数据漂移。
实施LLM基准测试的最佳实践
如果您想要练习为LLM构建一个测试框架,从头开始实现是一个很好的选择。然而,如果您想要使用一个现有的强大的LLM评估框架,那么使用DeepEval是一个很好的选择,因为我们已经为您完成了所有艰巨的工作。
DeepEval是LLMs的开源评估基础设施,它使得遵循评估过程最佳实践变得像在PyTest中编写测试用例一样简单。以下是它提供的解决基准测试LLMs当前问题的功能:
- 与PyTest集成,因此它为您提供了与PyTest非常相似的接口和装饰器,这样您就可以编写特定于领域的测试用例,用于评估当前基准测试框架无法涵盖的LLM用例。
- DeepEval提供了14个以上的预定义评估指标,用于评估基于LLMs/RAG的系统,可以在本地计算机上运行,也可以使用GPT模型。用户还可以自由编写自己定制的评估指标,所有这些指标都会自动集成到DeepEval的评估生态系统中。
- 将评估结果推送到Confident AI,DeepEval的托管平台上,该平台允许您跟踪评估实验、调试评估结果、将基准数据集集中在一起用于评估,并通过不同的无参考指标跟踪生产事件以持续评估LLMs。
不仅如此,还有一些新功能即将推出,比如集成了LM-Evaluation Harness,以及使用HuggingFace进行微调期间的并发评估。如果你想了解更多关于DeepEval的信息,请查看⭐ GitHub仓库⭐。
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
def test_hallucination():
metric = HallucinationMetric(minimum_score=0.5)
test_case = LLMTestcase(input="...", actual_output="...")
assert_test(test_case, [metric])
不要忘记给它一个星星,让我们知道我们正在朝着正确的方向前进。此外,我们有一套精选的文档和教程,您可以轻松开始使用DeepEval。
总结
在这篇文章中,我们了解了当前的评估范式,并理解了LLM基准测试/评估的术语。我们还了解了一些关于评估基准测试和比较LLM在不同任务或场景下的重要研究。最后,我们讨论了在生产使用案例中评估LLM的当前问题,并介绍了一些最佳实践,可以帮助我们克服常见的与生产相关的问题,并安全自信地部署LLM。
参考资料
- LM评估工具
- 语言模型正在改变人工智能:对整体评估的需求
- LLM评估的闪电演讲:由Anindyadeep
- 代码生成评估工具
- 关于LLM护栏的一切你需要知道的。
- 部署开放AI的LLMs的最佳实践。