面对挑战:教师在识别研究生法学硕士生成的文本和抄袭方面的困扰


在过去的几天里,我一直在访问Kaggle网站,原因有很多。大部分时间,是为了找到一些与银行相关的使用案例的相关数据集,以帮助或训练我正在构建的对话AI产品。这个产品将为用户提供一个分析或洞察发现平台,以查询数据并挖掘洞察,但采用对话式格式,而不是做所有的繁重工作(从设置Python/R笔记本到建立规则以自动化工作/流程)。现在,让我暂停对话AI的故事,将焦点放在目前出现的最新关注点上-学术抄袭问题上。教师们现在很难区分LLM生成的文本和学生们在作业/考试中手动撰写的文本,这令他们非常困惑和担忧。我想谈一谈这个问题的原因,因为这是我长期以来感兴趣的领域。
所以正如我之前所说,我一直在Kaggle上找各种各样的数据和数据集,但有一次,我被一个非常有趣的比赛吸引住了(由于数据和代码许可限制,我不会详细介绍,请在比赛进行期间阅读/看到这篇文章的时候,我请求你不要分享/传播我在下面提到的代码,因为那将是非法的,并且违反规定。我只是为了增加知识而分享代码,所以请只阅读代码,不要分享它。谢谢 :))。但为了给你一个整体的观点——这个比赛是关于识别/区分由LLM(ChatGPT)生成的文本和手动编写的文本。
并且那就是促使我深入研究这个主题,探寻一些根源并进行分析的地方。
首先,我分享以下两段文字。每一段都是关于“工作场所恐怖主义”的短文。其中一段是由LLM生成的,而另一段是我写的。你能否轻松/困难地辨别出哪一段是哪一段?请在评论中留下你的答案/回复。
1.
工作场所恐怖主义是一个严重问题,要求雇主、员工和当局同样给予毫不动摇的重视。这种可怕的威胁以各种形式出现,从身体暴力到网络攻击,营造出一种恐惧和不确定的氛围。雇主必须通过实施全面的安全措施、定期风险评估和提供相关培训,优先保护员工的安全和福祉。推动开放沟通和警觉的文化至关重要,以培养一个能够共同阻止任何潜在恐怖主义行为的有韧性的员工队伍。与执法机构合作、制定应急响应计划,以及利用先进技术进行监控和威胁检测是减轻工作场所恐怖主义风险的关键组成部分。通过营造积极主动和警觉的环境,组织可以为创造一个员工安全至上的工作环境做出贡献,确保恐怖主义威胁最小化,以便个人在安全受保护的环境中履行职业职责。
#2
警惕是当下的需要。无论是在边境保卫国家免受敌人侵犯,还是在我们的家庭中确保妇女和儿童的安全和幸福,又或者在我们的工作场所中,通过工作压力和政治手段,有时隐藏着一种微妙的恐怖氛围。有时正常的训斥可能会演变成严厉的恐吓言辞,人们常常未察觉但却会影响到受害者的稳定和心理平静。无论是出于个人私心还是对下属表现不佳的真正关切,主管和负责人常常会失去冷静并采取威胁手段,认为这些手段可以吓住受害者并迫使其接受他们的条件或放弃职位。在这两种情况下,对受害者来说,都会成为一种基本的情境危机,他们的安全和心理健康都会受到威胁。重要的是,组织应该在工作场所采取严格措施,为员工营造一个安全且无威胁的环境。
对于你们中的一些人来说,由于你们在特定语言的书面形式和口语形式以及相关语言学方面的专业知识,区分LLM生成的文本和手动书写的文本可能相对容易。然而,如果我们从一个外行人的角度来看,他对语言学领域不太精通,就会在划分上失败得很惨。
即使对于小学教师们来说,他们可能会给学生们布置写关于各种主题的文章的任务;遏制抄袭仍然十分困难。考虑到现在全世界的学生都能够使用ChatGPT等AI模型,他们有很大可能会利用这些语言模型完成作业。有时即使对于语言学专家来说,也很难区分一个由语言模型生成的文本和手动撰写的自然语言,因为语言模型和人类大脑都能够带来多样性。即使现在不能实现,或许在不久的将来,无论哪一方都会在某个关键时刻发展得如此出色,以至于能够几乎完全模拟人类大脑。
这是关于一个语言学专家的问题,在这里,我们正在处理可能没有深入技术细微差别的小学英语教师,他们无法区分由LLM生成的文本和手动编写的文本;因此,对于他们来说,这是一种绝对的危险,我个人认为。
但实际上,感谢机器学习,才能做出这种区别。

在我们查看代码之前,对于初学者来说:我们将查看一个分类模型,它将区分LLM生成的文本和手动编写的文本。我使用了MultinomialNB和RandomForestClassifier模型来完成这个任务。
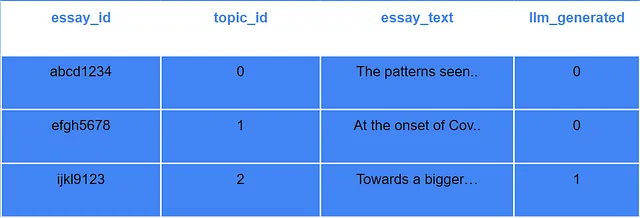
训练数据
我们来看看我们将要处理的训练数据集的类型。这只是实际数据的虚拟表示。
数据应该有四列,分别是:
- 论文编号:这将是分配给论文的唯一标识。
- 主题ID:这将是分配给学生所写的几个话题中每个话题的唯一标识符。
- This will be the actual text of the essay. 这将是论文的实际文本。
- llm_generated:这将是一个二进制值(1或0)。1表示该论文是由LLM生成的,0表示该论文是人工撰写的(非LLM生成的)。
分类模型
据他们所说,对于分类器和专家来说,采用集成方法总是更好的选择。为了提高准确性,我决定使用两种方法对分类模型进行训练,一次是用MultinomialNB,另一次是使用RandomForestClassifier。
在这两种情况下,当我在Kaggle上运行代码时,准确率目前都没有超过70%,显然这是一个问题,但我将单独解决并在另一篇文章中进行讨论。但是,如果您向下滚动几个折叠,您将遇到我在实施MultinomialNB分类器模型时提到的对于100%准确率的超现实体验;正如你将看到的那样。
MultinomialNB:多项式朴素贝叶斯分类器模型非常简单且有效,适用于文本分类任务,并且长期以来一直是受欢迎的选择。它以处理离散数据而闻名。该模型具有概率性质,并且其处理离散数据的能力广受瞩目。总的来说,它是一个非常多才多艺的算法,适用于从垃圾邮件检测到情感分析等各种应用。今天,我将在一个使用案例中应用它,该案例是想要查看一群小学生写的文章,并试图确定其中哪些是由LLM生成的,哪些是学生真实手写的。我并不是说我要帮助老师们!或者,我是吗? 😝
RandomForestClassifier(随机森林分类器):随机森林算法是一种监督式机器学习算法,在数据科学和机器学习领域非常受欢迎,因其在分类和回归问题中的应用而闻名。理解和认识RandomForestClassifier的优点的一种有趣方式是与森林进行类比;森林由众多树组成,树越多,越能提高算法的稳健性。
RandomForestClassifier的主要优势之一是它们可以处理高维稀疏数据集,就像Virat在2023年10月23日应对压力一样(知道的都知道),这在文本分析中很常见。RandomForestClassifier模型也非常受欢迎,因为它们具有处理缺失值、异常值和不平衡类别的能力,而这些问题可能会影响其他算法的性能。
代码时间
第一次尝试:MultinomialNB
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
# Loading the training data
train_data = pd.read_csv(r"-----path to the file which has the train dataset------")
# Splitting the data into training and validation sets
train_set, val_set = train_test_split(train_data, test_size=0.2, random_state=42)
# Preprocessing the text data using TF-IDF vectorization
vectorizer = TfidfVectorizer(max_features=5000, stop_words="english")
X_train = vectorizer.fit_transform(train_set["text"])
X_val = vectorizer.transform(val_set["text"])
# Creating the target labels
y_train = train_set["generated"] # Here "generated" is the column indicating whether the essay was generated by a student or an LLM
y_val = val_set["generated"]
# Training a simple Naive Bayes classifier
classifier = MultinomialNB()
classifier.fit(X_train, y_train)
# Making predictions on the validation set
# predictions = classifier.predict(X_val)
predictions = classifier.predict_proba(X_val)[:, 1] #here we are trying to get a probability score of whether an essay is manually written or llm-generated
# Evaluating the model
accuracy = accuracy_score(y_val, predictions)
report = classification_report(y_val, predictions)
print(f"Accuracy: {accuracy}")
print("Classification Report:")
print(report)
# Using the trained model to make predictions on the test set
test_data = pd.read_csv(r"-----path to the file which has the test dataset------")
X_test = vectorizer.transform(test_data["text"])
test_predictions = classifier.predict_proba(X_test)[:, 1]
# test_data["generated"] = test_predictions
submission_df = pd.DataFrame({"id": test_data["id"], "generated": test_predictions})
submission_df.to_csv("submission.csv", index=False)
在Jupyter上运行此代码后,我获得了以下准确率:
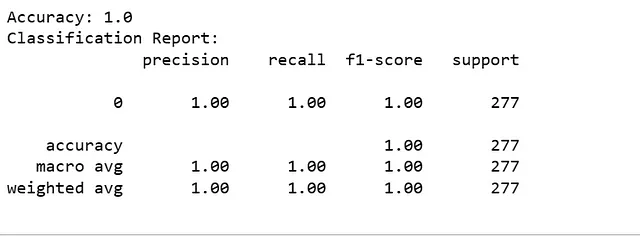
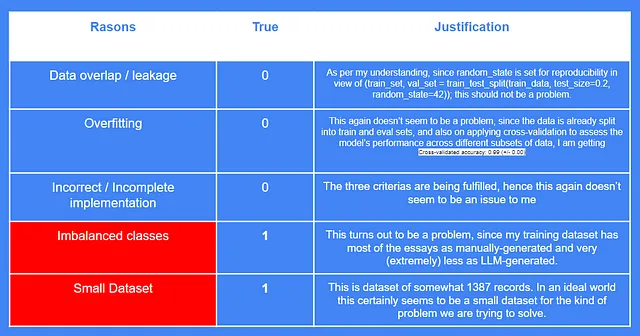
而且这确实让我感到担心,因为我并没有真正期望模型输出一个1。为了深入了解,我搜索了更多关于为什么MultinomialNB可能会给出100%准确率的原因。所以我找到的原因有:
- 数据重叠/泄漏: 在这里,目的是确保没有任何类型的数据泄漏,以及测试数据集中的信息不会意外地出现在训练数据集中。这也可能人为地提高准确性。
- 过拟合: 您所训练的MultinomialNB模型可能是过拟合的受害者。这意味着模型可能捕捉到数据中的噪音,并根据不适用于新数据的特定模式进行调整。因此,您可能在训练数据集上观察到高准确性,但在测试数据集上获得低准确性。
- 不平衡的分类:由于这是一个分类任务,所以您的训练数据集中应该包含标签。这些标签是将每个记录分组或分配到的类别。可能发生的情况是记录分布/分配给每个标签不均匀,导致模型预测多数类别,从而获得100%的准确性(或任何让您感到困惑的数字)。
- 不正确/不完整的实施:有时候,我们只是实施了一个非常粗糙的分类或其他机器学习模型。我所说的是,虽然算法的选择在你的分类工作或其他任何工作中都起着至关重要的作用,但数据的质量和封装特征也同样重要。一些全球数据科学家提出的建议是:1)确保数据经过良好的预处理,2)进行特征缩放,3)将数据正确地拆分为训练集和测试集。
- 小数据集:如果您的数据集较小,模型可能会把所有训练示例都记住,导致训练集准确率很高,但泛化能力较差。
尝试重新检查我的模型和训练数据集,我试图确定在我的情况下可能是真实的原因。结果发现,由于类别不平衡和数据集较小,我的MultinomialNB模型的准确度奇怪地达到了100%。
现在我们都意识到了这种情况,我建议你自己训练模型时,在你这一端处理好最后两个要点,这将帮助你远离不真实的100%准确性的花招。
第二次尝试:多项式贝叶斯(调整后)
在这里,我对之前标准的MultinomialNB代码做出的改进是通过参数进行了一些调整。
- 在TfidfVectorizer中将max_features增加到10000(max_features用于在训练/分类过程中对文本进行特征化,通过设置一个上限)。
- 将ngram_range设置为(1,2),这意味着我要求模型在数据中寻找单个词和两个词的组合。限制模型仅寻找单个词,以便提交到词袋模型中,显然会影响准确性。
- 将alpha超参数的值设为0.1进行平滑。这种平滑技术常用于文本分类任务中,其中特征(单词)可能不会出现在所有类别中,导致概率为零。
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# Assuming you have already loaded and preprocessed your training data
# Split the data into training and validation sets
train_set, val_set = train_test_split(train_data, test_size=0.2, random_state=42)
# Preprocess the text data using TF-IDF vectorization
vectorizer = TfidfVectorizer(max_features=10000, stop_words="english", ngram_range=(1, 2))
X_train = vectorizer.fit_transform(train_set["text"])
X_val = vectorizer.transform(val_set["text"])
# Create the target labels
y_train = train_set["generated"] # Assuming "label" is the column indicating student or LLM
y_val = val_set["generated"]
# Train a Multinomial Naive Bayes classifier with tuned hyperparameters
classifier = MultinomialNB(alpha=0.1) # Adjust alpha based on your hyperparameter tuning
classifier.fit(X_train, y_train)
# Make predictions on the validation set
val_predictions = classifier.predict(X_val)
# Evaluate the model
accuracy = accuracy_score(y_val, val_predictions)
print("Accuracy:", accuracy)
# Print classification report and confusion matrix for more insights
print("Classification Report:")
print(classification_report(y_val, val_predictions))
print("Confusion Matrix:")
print(confusion_matrix(y_val, val_predictions))
第三次尝试:随机森林分类器
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# Assuming you have already loaded and preprocessed your training data
# Split the data into training and validation sets
train_set, val_set = train_test_split(train_data, test_size=0.2, random_state=42)
# Preprocess the text data using TF-IDF vectorization
vectorizer = TfidfVectorizer(max_features=10000, stop_words="english", ngram_range=(1, 2))
X_train = vectorizer.fit_transform(train_set["text"])
X_val = vectorizer.transform(val_set["text"])
# Create the target labels
y_train = train_set["generated"] # Assuming "label" is the column indicating student or LLM
y_val = val_set["generated"]
# Train a Random Forest classifier with tuned hyperparameters
classifier = RandomForestClassifier(n_estimators=100, max_depth=50, random_state=42)
classifier.fit(X_train, y_train)
# Make predictions on the validation set
val_predictions = classifier.predict(X_val)
# Evaluate the model
accuracy = accuracy_score(y_val, val_predictions)
print("Accuracy:", accuracy)
# Print classification report and confusion matrix for more insights
print("Classification Report:")
print(classification_report(y_val, val_predictions))
print("Confusion Matrix:")
print(confusion_matrix(y_val, val_predictions))
在我的尝试2和3中,我得到的准确率在我的本地Jupyter笔记本上再次达到了100%。所以在这一方面,这两次尝试更像是试图将果冻钉到墙上。
然而,在Kaggle上,我的第三次尝试帮助我在准确性上取得了进一步的提升,相比我使用MultinomialNB的第一次尝试。我想你应该知道,为什么在我本地VS上执行模型和在Kaggle上执行模型时,准确度不同。原因很简单:在我的本地上,我使用的数据集相当小,因此我得到的准确度达到了100%(就像我在这篇文章中提到的可能原因表中也提到的)。然而,在Kaggle上,社区(或者更准确地说是评委们)会对你的准确度进行验证,并将其与一个更大且更多样化的隐藏数据集进行比较。
我现在得去买杯咖啡了。我不确定今天是否还想再写。所以,如果你有评论要留下,请赶快留言吧。我会尽早查看并回复。我感觉这是我在2024年的第一篇文章,所以对于所有已经阅读到的朋友们——新年快乐 :) 冬天虽然阴郁,但内心却有一团火焰。
而且,如果偶然有位老师看到了这篇文章的结尾,我希望你能够理解(毕竟你是我写作的目标读者)。我已经花了将近一周的时间向我妈妈解释ChatGPT的工作原理,猜猜现在她成了一个好奇的学生,哈哈(角色逆转,时代的变迁)。
祝你平安。再见 :)