通过量化实现消费硬件的大型语言模型

大型语言模型(LLMs)自GPT-4以来的演进在自然语言处理中取得了显著进展,并涌现出各种开源变体。这些模型通常具有庞大的参数,对计算资源提出了挑战,因此采用了量化作为运行这些模型的解决方案。本文将简要讨论量化方法,这是一种压缩这些模型的方法,已经成为缓解这些挑战的可行解决方案,并允许在常规消费硬件上运行数十亿参数模型,包括最新的Macbook Air笔记本电脑。
量化基础
量化是一种通过将浮点表示转换为较低精度格式(通常是整数)来减少模型内存占用的技术。机器学习中的整数量化主要提高了内存效率,对于CPU和GPU都具有优势。CPU由于整数运算比浮点运算更快、更简单,所以受益于量化,从而实现计算速度加快。GPU专为高精度浮点运算而优化,从量化模型的内存占用减少中获益较少。这样更小的模型尺寸允许更高效地使用GPU的内存带宽和缓存,实现更多的数据并行处理。因此,虽然CPU和GPU的好处性质不同,但量化对两者都有助于性能的提升。
这个过程包括两个主要的步骤:将原始数据缩放到特定的范围,然后将它映射到离散值。在模型大小、计算效率和准确性保持之间存在一种平衡。
量化方法的类型
存在两种主要的方法:均匀量化和非均匀量化。均匀量化通过在所有值上应用相同的标度因子简化了过程。这种方法简单直接且计算效率高,因为它统一地提供了整个数据范围的标度。然而,在处理具有不同分布的数据时,它可能不总是最准确的。均匀方法可能导致与所选标度因子不太匹配的值产生显著的信息丢失。另一方面,非均匀量化采用更为定制化的方法。它根据数据的不同段落调整标度因子,考虑每个段落的具体分布和特性。虽然这种方法计算量较大,但它通常通过在变异性或异常值较高的区域中保留更多的数据信息来保持更高的准确性。非均匀量化在关键数据范围的精度至关重要时特别有用,但它需要更复杂的算法来确定每个数据段的最佳标度。两种方法都在简单性、计算开销和准确性之间权衡,选择取决于具体要求和应用的限制。
量化示例
- 原浮点数:[-0.9, -0.2, 0.0, 0.4, 0.8]
- 缩放因子(s):7.78(基于7 / max(abs(data)))
- 量化整数:[-7,-2,0,3,6](使用round(original_value * s))
实践中的量化级别
通过类似于llama.cpp的框架,几种量化方法已经变得非常流行。术语“QK块大小”出现并与量化过程相关,其中“QK”指的是被量化的数据块的大小。调整QK块大小可以影响计算效率和模型精度之间的平衡,进而影响模型在不同硬件环境中的性能表现。
保持HTML结构,将以下英文文本翻译成简体中文: QK(块大小)的最佳值需要在压缩比和准确性之间进行权衡。它还取决于CPU架构,因为不同的大小可能对于不同的SIMD指令集更有效。SIMD代表单指令多数据(Single Instruction, Multiple Data)。这项技术使得计算机可以同时对多个数据点执行相同的操作。当一个大型语言模型处理数据时,通常会在许多数据点上执行相同的操作(如加法或乘法,比如神经网络中的权重和偏置)。SIMD使这些操作可以并行进行。
- 2至4位量化(Q2_K,Q3_K,Q4_K):这些模型经过高度压缩,因此尺寸更小,内存使用更低。它们适用于内存有限的系统,但会牺牲一些准确性。在Q4中,量化将每个权重缩小为4位表示。在Q4_0中,一组数字用一个缩放因子表示,而Q4_1则使用缩放因子和偏移因子来增强准确性。
- 5到6位量化(Q5_K,Q6_K):在尺寸和准确性之间取得更精细的平衡,使之成为对于具有中等内存容量的系统而言的首选。
- 8位量化(Q8_0):更接近原始模型准确度,但需要更高的内存,适用于具有大量RAM的系统。
量化公式
- Q4_0:涉及用单个32位浮点比例因子和多个4位整数来表示一组浮点数。压缩比是(4 + QK/2)/(2*QK)。
- Q4_1:通过引入附加的偏移因子来增强Q4_0,导致公式为(8 + QK/2)/(2*QK)。
模型尺寸
- 7b:一个70亿参数的模型,在不进行量化的情况下,可能需要大量的内存,潜在的容量可能超过几十GB。然而,当使用Q4或Q6等方法进行量化时,内存需求大幅减少,使得对于具有16GB RAM的系统(如M2 MacBook Air)来说是可行的。
- 13b:对于一个拥有130亿参数的模型,即使进行量化,其内存和计算开销也可能相当大。这类模型更适合于使用GPU设置或拥有充足内存的高端硬件。
框架和文件格式
GGML(通用神经网络推导框架)类似于TensorFlow,用于神经网络推理。GGUF(Georgi Gerganov's Universal Format,格奇·格尔加诺夫通用格式)是最新的附属文件格式,专为高效的模型分发和支持多种量化方法而设计。
LLMs在消费者硬件上的应用:M2 MacBook Air 16GB
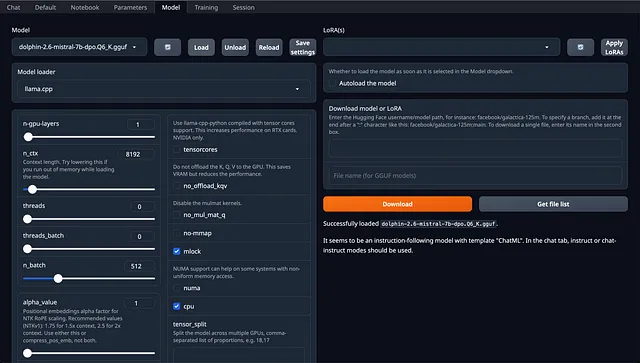
我们可以使用oobabooga/text-generation-webui轻松在消费者硬件上测试模型。克隆存储库并将.gguf文件下载到/models目录中。对于在MacBook Air上使用M2芯片和16GB内存运行大型语言模型(LLM)的用户来说,关键考虑因素是选择正确的量化级别(Q4或Q6)和有效地管理上下文窗口大小。这是一个简洁的指南,利用llama.cpp参数来优化这些方面。
量化水平
我们发现在Q4_K_S和Q6_K量化之间的选择直接影响了能够有效管理多大的上下文窗口。通过使用Q4_K_S,用户可以利用更大的上下文来进行更广泛的文本生成或分析任务,而不会过载系统。对于Q6_K,重点是在减小上下文窗口大小以保持系统的响应性时平衡准确度。
- Q4_K_S(4位量化,小型):适用于在内存限制内最大化上下文窗口大小。这种量化级别允许上下文大小高达16,384个标记,因为它占用较低的内存空间。
- Q5_K_M(5位量化,中等):建议使用此方法,因为其质量损失非常低。它在内存使用和质量保留之间取得平衡,对于优先考虑准确性但受到一些内存约束的用户来说,是一个最佳选择。
- Q6_K(6位量化):提供更好的准确性,但需要在上下文窗口大小上做出妥协,将其限制在8,192个标记以防止内存使用过高。
我们已经使用TheBloke/dolphin-2.6-mistral-7B-dpo-GGUF进行了测试,测试结果显示内存使用情况如下:
dolphin-2.6-mistral-7b-dpo.Q4_K_S.gguf 6.64 GB small, greater quality loss
dolphin-2.6-mistral-7b-dpo.Q4_K_M.gguf 6.87 GB medium, balanced quality
dolphin-2.6-mistral-7b-dpo.Q5_K_M.gguf 7.63 GB large, very low quality loss
dolphin-2.6-mistral-7b-dpo.Q6_K.gguf 8.44 GB very large, extremely low quality loss
上下文窗口大小
- Q4_K_S模型:通过4位量化,该模型能够在16,384个令牌的上下文窗口大小下平稳运行。较低位量化使模型尺寸更小(3.86 GiB),从而释放更多RAM,使得可以使用更大的上下文窗口,而不会过度负担系统。
- Q6_K模型:该模型采用6位量化,在8,192个令牌的上下文窗口中有效运行。较大的模型大小(5.53 GiB)消耗更多的内存,限制了可行的上下文窗口大小,以防止系统冻结。
模型选择
除了量化(例如 Q6_K)和参数(例如 7b),我们还希望下载 GGUF 格式的模型。有各种各样的 HuggingFace 排行榜可以辅助模型选择。您可能会遇到更多术语,例如:
- “DPO” 模型:引入直接偏好优化(DPO)。控制LLM行为的标准方法涉及从人类反馈中进行强化学习(RLHF),这是一个复杂且经常不稳定的过程。DPO通过重新参数化RLHF中的奖励模型,创新地实现了从封闭形式中提取最佳策略。这种简化使得可以使用简单的分类损失来解决标准RLHF问题。
- “未经审查的模型”:未嵌入特定对齐方式的LLM,通常用于防止生成有害或有争议性的内容。未经审查模型的概念引发了在人工智能应用中控制与自由之间平衡的辩论。例如,作家和研究人员可能需要获取更广泛的信息范围,包括敏感或有争议的主题,以进行创作和调查工作。此外,未经审查模型的概念支持用户自主权的理念,即个人可以控制他们的人工智能工具生成的内容,类似于其他个人设备。这种观点强调提供一个中立、不对齐的人工智能基础的重要性,以满足各种特定用户需求,并意识到在动态的人工智能应用世界中,一刀切并不适用于所有情况。
llama.cpp 参数
为了运行顺畅,我们可以使用llama.cpp来调整以下参数。
- - mlock: 重要的是将模型锁定在内存中,确保稳定性并防止由于交换引起的性能问题。
- --no-mmap: 禁用模型的内存映射,这在16GB系统上很少有用,并且可能导致过多的分页。
- 保证模型使用GPU,这对于管理M2芯片的计算负载是重要的因素。
我们在Macbook Air设备上每秒获得约20个令牌。
Output generated in 6.08 seconds (22.02 tokens/s, 134 tokens, context 576, seed 1476198239)
Llama.generate: prefix-match hit
Output generated in 3.65 seconds (21.62 tokens/s, 79 tokens, context 725, seed 1239662365)
Llama.generate: prefix-match hit
Output generated in 5.36 seconds (19.21 tokens/s, 103 tokens, context 829, seed 1458689517)
Llama.generate: prefix-match hit
Output generated in 5.96 seconds (19.47 tokens/s, 116 tokens, context 1066, seed 1021037349)
演示讨论:
结论
对于使用消费级硬件,如16GB内存的Apple M2 MacBook Air的用户来说,量化提供了一种实用的途径来利用LLM的能力。在这种情况下,一个70亿参数的量化模型,比如dolphin-2.6-mistral-7b-dpo.Q6_K,可以在内存效率和计算性能之间找到平衡,是一个很好的选择。这个选择强调了LLM量化中的一个更广泛的原则:优化模型大小、计算要求和准确性之间的权衡,以适应特定的硬件约束和应用需求。