使用ChatGPT即时获取网页文章的摘要和情感分析

在一个信息过载的时代,迅速理解并评估文章的情感色调变得至关重要。在本小文章中,我们的目标是通过构建一个用户友好的小部件来满足这一需求。我们为您提供了一个全面的工具,可以即时对互联网上搜集到的网页文章进行总结和情感分析。
预期会有什么
您将会遇到一种创新的小部件,旨在简化从基于网络的文章中提取有意义的见解的过程。本文将为您阐明以下内容:
- 网页文章摘要:只需点击几下,您就能获得长篇网页文章的简明摘要。对于那些需要快速掌握文章精华而又没有时间阅读全部内容的人来说,非常有用。时间就是金钱 ;-)。
- 情感分析:我们对被抓取的文章的情感进行了平等的评估。这使您能够理解其中潜在的情感倾向 —— 无论是积极的、消极的还是中性的。这一功能对于研究人员、市场营销人员和对公众舆论和媒体分析感兴趣的任何人来说都是无价之宝。
- 交互式小工具:在该项目的核心是一个交互式小工具,使整个过程变得顺畅和用户友好。您只需输入网页文章的URL,该小工具会处理剩下的一切,并为您提供摘要和情感分析,同时附有文章的一些细节,如标题、作者和发表日期(如果有)。
通过这个项目的完成,您将获得对一种强大的自然语言处理应用的实际操作经验,展示了在真实世界场景中进行摘要和情感分析的实际好处。祝您愉快!
必要的库
!pip install newspaper3k #https://newspaper.readthedocs.io/en/latest/
!pip install textblob==0.9.0 #https://textblob.readthedocs.io/en/dev/
!pip install nltk #https://www.nltk.org/
!pip install openai #https://openai.com/
!pip install --upgrade pydantic #https://docs.pydantic.dev/latest/
!pip install --force-reinstall langchain #https://www.langchain.com/
必要的导入
from langchain_community.document_loaders import WebBaseLoader
from langchain.chains.summarize import load_summarize_chain
from langchain_community.chat_models import ChatOpenAI
from newspaper import Article,Config
from newspaper import ArticleException
from textblob import TextBlob
import ipywidgets as widgets
import nltk
import os
nltk.download('punkt')
获取您的API设置
os.environ["OPENAI_API_KEY"] = "Your_OPENAI_API_KEY_goes_here"
报纸库的自定义配置,使用修改后的用户代理
这将帮助您像人一样浏览,以避免被屏蔽。
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
config = Config()
config.browser_user_agent = user_agent
我们的LLM初始化用于摘要
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
- llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106"):创建 ChatOpenAI 类的一个实例,该类是 OpenAI 的 GPT 模型的包装器。温度参数被设置为 0,意味着模型会产生更确定性、更少随机的回答。model_name 参数指定了模型的版本,此处为 "gpt-3.5-turbo-1106",最新版 :)。
- chain = load_summarize_chain(llm, chain_type="stuff"):加载具有指定llm(语言模型)的摘要链。 chain_type参数设置为“stuff”,指的是在Langchain中定义的特定类型的摘要链。该链将使用提供的语言模型(llm)来执行其任务,即在我们的环境中,对文本进行摘要。
创建输入字段,输出区域和按钮
layout_large = widgets.Layout(width='800px', height='200px') # Large layout for text areas
layout_small = widgets.Layout(width='800px', height='50px') # Smaller layout for single-line inputs
style = {'description_width': 'initial'}
utext = widgets.Textarea(description='URL:', layout=widgets.Layout(width='800px', height='20px'))
title = widgets.Textarea(description='Title:', disabled=True, layout=layout_small)
author = widgets.Textarea(description='Author:', disabled=True, layout=layout_small)
publication = widgets.Textarea(description='Pub. Date:', disabled=True, layout=layout_small)
summary = widgets.Textarea(description='Summary:', disabled=True, layout=layout_large)
sentiment = widgets.Textarea(description='Sentiment:', disabled=True, layout=layout_small)
button = widgets.Button(description='Search', layout=widgets.Layout(width='100px'))
button.style.button_color = 'black'
定义总结函数
def summarise(b):
button.description = 'Searching...'
button.disabled = True
try:
url = utext.value.strip()
loader = WebBaseLoader(url)
docs = loader.load()
article = Article(url,config=config)
article.download()
article.parse()
article.nlp()
title.value = article.title if article.title else '-Not Found-'
author.value = ', '.join(article.authors) if article.authors else '-Not Found-'
publication.value = str(article.publish_date) if article.publish_date else '-Not Found-'
# Use Langchain to summarize
summary_text = chain.run(docs)
summary.value = summary_text if summary_text else article.text
analysis = TextBlob(article.text) if article.text else TextBlob(str(docs))
sentiment_val = "Positive" if analysis.polarity > 0 else "Negative" if analysis.polarity < 0 else "Neutral"
sentiment.value = sentiment_val
except ArticleException as e:
summary.value = "Failed to download the article: " + str(e)
finally:
button.description = 'Summarized'
button.disabled = False
button.on_click(summarise)
在这个概述功能中,我们使用TextBlob Python库平衡地捕捉文章的情绪。
展示小部件
utext.value = ''
title.value = ''
author.value = ''
publication.value = ''
summary.value = ''
sentiment.value = ''
# Then display the widgets
display(utext, button, title, author, publication, summary, sentiment)
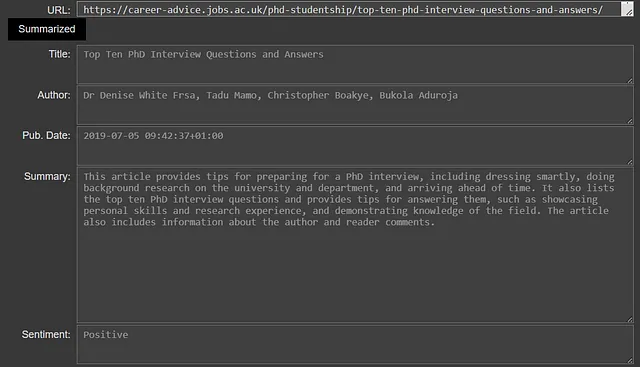
总结和情感分析功能具有双重优势。
- 保留HTML结构,将以下英文文本翻译成简体中文: 摘要将内容进行概括,使其更易消化,同时
- 情感分析为文本的情感色彩增添了一层理解的能力。
这种组合对于全面理解网页文章非常有用。
该应用的重要性
其重要性在于其将大量文本提炼成易于理解的摘要,并提供对文章情感色彩的快速理解。这样的工具对以下方面非常有益处:
- 学生和学者:这个工具可以帮助快速浏览大量文章,仅关注相关信息。
- 业务专业人员:尤其是那些从事传媒、媒体或公共关系工作的人,理解各种文章的内容和情感对于战略制定非常重要。
- 休闲读者:这个工具提供了一种快速了解信息而不被可用信息的数量所压倒的方法。
含义和未来发展趋势
- 这个工具可以作为进一步研究自动文本摘要和情感分析的起点,潜在地可以带来更细致和准确的算法。
- 企业和组织可以针对媒体监测、品牌情感分析和快速信息检索应用这项技术,提升决策过程。
- 这个工具可以作为一个教育资源,供对自然语言处理(NLP)及其实际应用感兴趣的人使用,促进对人工智能和机器学习的深入兴趣。
结论
NLP领域正在不断发展,未来将带来更复杂的工具和应用。我们希望这个笔记本不仅能为您提供有用的工具,还能引发您对NLP和人工智能潜力的好奇和兴趣。感谢您与我一同参与这个启发性之旅! :)
一些重要的链接
- 网页基础加载器
- LangChain 摘要
- 我的Github页面