使用Vader和gensim对Reddit标题进行情绪分析和主题模型。
使用自然语言处理(NLP)分析热门 ChatGPT 标题的情感和主题模型。
情感分析和主题建模再访
用通俗易懂的语言来说,情感分析是基于积极和消极的词语,从文本信息中识别洞察,其中包括产品的客户评论,以及在社交媒体上的意见挖掘等多个应用场景。情感分析在商业增长和与产品建立更强的客户关系方面起着重要作用。
主题建模是一种从文本或文档语料库中提取主题的统计方法。常见的企业应用案例包括对报纸文章、研究论文甚至是在线帖子进行主题提取。
对于这个项目,我们将利用Python NLP库,如VADER和gensim,从标题中生成情感分数,以及将它们建模成主题集群。 对于这个项目,我们将应用潜在狄利克雷分配(LDA)模型。 如果您想了解更多关于LDA的知识,可以参考Shashank Kapadia的下面的文章。
简介
在我们开始编码之前,我们将前往Reddit应用程序开发者网站www.reddit.com/prefs/apps开发该应用程序,以从Reddit中提取标题。首先,我们将为我们的应用程序输入一个名称。对于此项目,我们将使用“examplenlp”。请注意,不允许在我的应用程序名称选择中使用Reddit这个单词。
然后我们将选择脚本选项,因为我们正在基于Python代码构建主题模型。描述和关于url是可选的,但我们必须为应用程序输入一个默认的URI。为了这个例子,我们将使用http://localhost:8080。
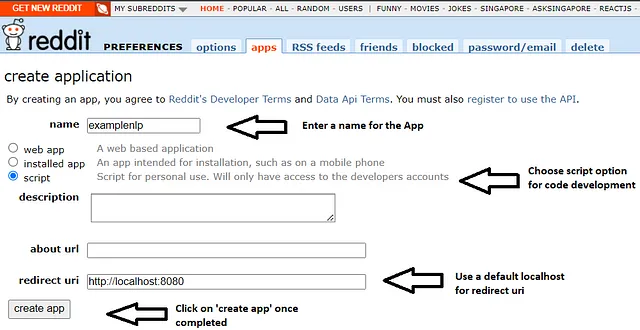
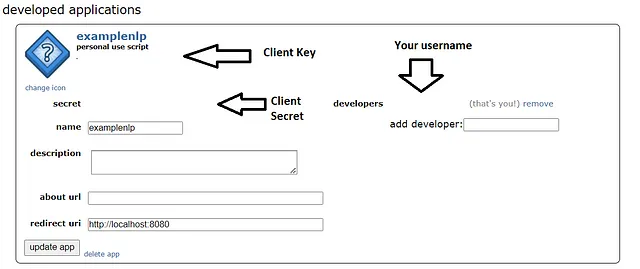
一旦完成,我们将点击“创建应用程序”按钮,它将生成“客户端密钥”和“客户端密钥”。为了匿名目的,信息已被清空。
代码开发
第一步:安装PRAW库,提取Reddit头条
!pip install praw第二步:通过插入生成的客户端密钥和客户端密码设置Reddit API抓取器。
import praw
user_agent = "Scraper 1.0 "
reddit = praw.Reddit(
client_id="<INSERT CLIENT ID>",
client_secret="<INSERT CLIENT SECRET>",
user_agent=user_agent,
check_for_sync=False
)第三步:使用Reddit爬虫提取标题。导入pandas库,将标题集转换为Pandas DataFrame。
import pandas as pd
headlines = set()
for submission in reddit.subreddit('cryptocurrency').hot(limit=None):
headlines.add(submission.title)
df = pd.DataFrame(headlines)
df.head()
第四步:我们将使用nltk库的Vader Lexicon模块以及SentimentIntensityAnalyzer来从标题中获取复合分数。复合分数基本上是一种度量标准,它计算了被归一化为-1到1的词典评分的总和。
import nltk
nltk.download("vader_lexicon")
from nltk.sentiment.vader import SentimentIntensityAnalyzer as SIA
sia = SIA()
results = []
for line in headlines:
pol_score = sia.polarity_scores(line)
pol_score['headline'] = line
results.append(pol_score)
df = pd.DataFrame.from_records(results)
df.head()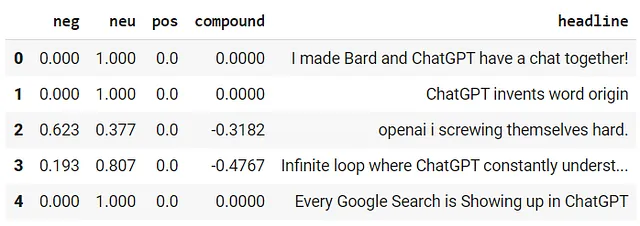
第五步:根据复合分数对标题进行分类。对于此示例,我们将应用0.2的阈值来区分正面和负面的标题。
df['label'] = 0
df.loc[df['compound'] > 0.2, 'label'] = 1
df.loc[df['compound'] < -0.2, 'label'] = -1
df.head()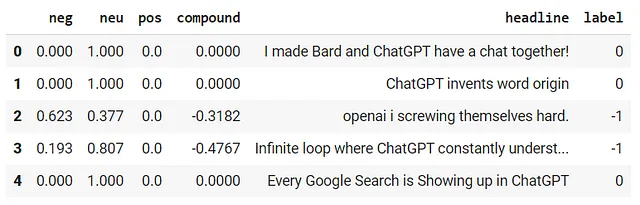
第六步:生成标题语料库的词云,以确定出现最多的单词。
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
sw = STOPWORDS
text = “ “.join(i for i in df[“headline”])
wc2 = WordCloud(stopwords=sw, background_color=“white”, max_words=300)
.generate(text)
plt.figure(figsize=(10,10))
plt.imshow(wc2, interpolation=“bilinear”)
plt.axis(‘off’)
plt.show()
步骤7:打印一些正面和负面标题样本以进行一次可行性检查。
from pprint import pprint
df = df[['headline','label']]
print("Positive headlines:\n")
pprint(list(df[df['label'] == 1].headline)[:5], width=200)
print("Negative headlines:\n")
pprint(list(df[df['label'] == - 1].headline[:5]), width=200)
第八步:导入正则库re来删除特殊字符,如标点符号,并将标题设置为小写。
import re
df['headline_processed'] = df['headline'] \
.map(lambda x : re.sub('[,\.!?]', '', x))
df['headline_processed'] = df['headline_processed'] \
.map(lambda x : x.lower())
df.head()
第九步:从nltk库中导入gensim库和stopwords模块,以构建词袋(BOW)和向量嵌入,为创建语料库字典做准备。
import gensim
from gensim.utils import simple_preprocess
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
# Extend stopwords based on frequency of words on wordcloud
stop_words.extend(['chatgpt','chat','ai','google','asked'])
# Convert sentences to words
def sentence_to_words(sentences):
for i in sentences:
yield(simple_preprocess(str(i), deacc=True))
# Remove stopwords
def rm_stopwords(texts):
return [[word for word in simple_preprocess(str(doc)) if
not word in stop_words] for doc in texts]
data = df.headline_processed.values.tolist()
data_words = list(sentence_to_words(data))
data_words = rm_stopwords(data_words)
print(data_words[:1][0][:30])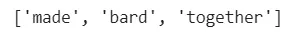
import gensim.corpora as corpora
id2word = corpora.Dictionary(data_words)
txt = data_words
corpus = [id2word.doc2bow(text) for text in txt]
print(corpus[:1][0][:30])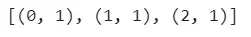
第10步:使用gensim.models.LdaMulticore生成主题模型。在这个例子中,我们将生成10个与ChatGPT相关的主题。
# number of topics
num_topics = 10
# Build LDA model
lda_model = gensim.models.LdaMulticore(corpus=corpus,
id2word=id2word,
num_topics=num_topics,
workers=2,
passes=5,
iterations=100)
pprint(lda_model.print_topics())
doc_lda = lda_model[corpus]
第11步:安装并导入pyLDAvis来可视化模型输出
!pip install pyLDAvis
import pyLDAvis
import pyLDAvis.gensim
# Visualize the topics
pyLDAvis.enable_notebook()
LDAvis_prepared = pyLDAvis.gensim.prepare(lda_model, corpus, id2word)
LDAvis_prepared







