使用LLMs进行快速工程化

这个博客将讨论使用LLM进行提示工程的基础知识。
有广泛的两种大型语言模型:
- 基础LLM - 这些LLM是我们大多数人用来构建的LLM。在这里,我们使用来自Web或其他来源的大量数据来训练我们的模型,使得模型可以预测给定一组单词后的下一个单词。例如,如果我写“Paris is famed for”,那么模型可能会补全句子“Paris is famed for its fashion houses”。但是,如果我给这个模型一个提示,比如“法国的首都是什么?”,那么这个模型将不会回答Paris,而是会建议更多的问题,比如“法国最大的城市是什么?”,“法国的人口是多少?”,等等。这是因为基础LLM的训练性质。我们没有训练它回答这样的查询,而是训练它用下一个最可能的标记来完成句子。
- 指令调整LLM- 相比之下,指令调整LLM被训练为遵循指令。这是为了获得我们的提示的答案,就像上面的例子中,当提示“法国的首都是什么?”时,这个模型应该回答:“法国的首都是巴黎。”这些模型是在我们的基础LLM之上训练的。我们在我们的基础LLM上加入了两层训练。首先,我们对许多输入(指令)-输出(尝试遵循指令)对进行微调。然后,我们应用强化学习与人类反馈(RLHF),以确保我们的模型是逻辑的,并遵循人工智能的伦理方面。
指令调优的直觉理解
假设你在医疗保健领域运营一家初创企业,并雇用了一名精通编程的聪明员工。但是,除非您为他提供所有必要的针对您的创业公司的具体说明,否则该员工对您没有任何用处。只有他理解了说明书,才能将他的技能应用于业务逻辑。这就是我们在指令调整中所做的事情。基础LLM就像我们需要为其提供指导以执行任务的聪明员工。
指令(提示)指南
所以基本上,我们作为快捷工程师充当用户应用程序和聊天GPT之间的渠道。我们的主要角色是开发,优化LLM生成的文本,以确保它们与应用程序标准相符,并且准确无误。我们接收输入文本,将该文本与我们的提示(说明)一起输入LLM中。我们的提示是请求LLM对给定文本进行优化和精炼的内容。根据输入文本和我们的提示,我们收到LLM的响应。然后我们可以将该响应返回给最终用户。我们可以使用任何LLM,但是假设我们正在使用聊天GPT。
首先,我们应该有访问chatGPT API的权限。我们需要安装openAI python库并设置openAI API的密钥(可在openAI网站上获取)。接着,我们只需使用openAI的聊天完成来设置API网关。例如:
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)我们可以使用这个设置从chatGPT获得回应。但在此之前,我们需要使用提示进行指令调整。指令调整主要有两个原则:
撰写清晰明确的指令——为使我们的指令更加明确明确,您应该使用定界符,如引号、反引号、短划线、括号、XML标记等。这些定界符有助于我们避免提示注入问题。提示注入是当用户能够向我们的提示添加输入时可能会导致我们的模型出现冲突指令的情况。这也有助于将提示与其他文本分开。此外,我们应该要求我们的模型提供结构化响应。例如,在JSON或XML中。这将帮助我们在Python中使用各种方便的数据结构,如字典或列表。我们还可以要求模型检查是否满足条件。这就像异常处理,但是与提示一起。例如,如果您有一段描述食品配方的段落,您可以要求chatGPT将它们写成步骤,如:
prompt = f"""
You will be provided with text delimited by triple quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.\"
\"\"\"{text}\"\"\"
"""
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
)给模型留时间思考 - 如果查询中存在一些复杂的问题,我们可以指示我们的模型花时间思考,而不是匆忙地回答错误。假设我们想要验证一个数学问题的答案,那么我们可以写出指示,例如“先自行解决问题,然后验证答案”。如果我们想询问任何产品的描述,我们可以添加指示,让其花时间检查自己的知识再回复。
限制。
尽管LLM在培训过程中接触到了大量的知识,但他们并不总是能正确地记住所有的东西。他们经常会出现幻觉,提供貌似合理但错误的信息。例如,以前如果询问聊天GPT关于原始行业中的一些虚假产品名称,它可能会提供许多看似合理的虚假信息。
迭代提示开发
就像机器学习模型开发一样,我们尝试各种参数并迭代地测试模型,这里我们也通过提示测试模型,然后迭代地改进。我们分析当前提示(说明)的结果,完善想法和提示,然后重复上述过程。
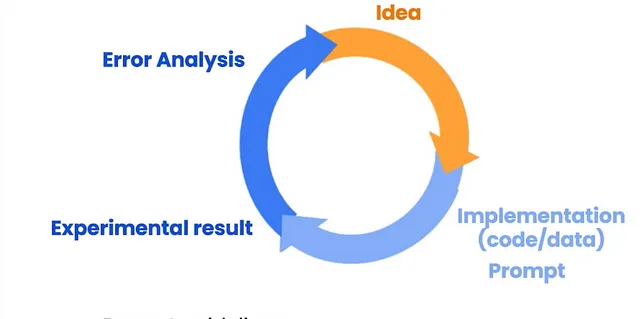
不同的应用程序
我们可以使用快速工程来进行不同的应用,例如概括、推测、转换、扩展、聊天机器人等。假设我们有一篇关于某个产品的大型文本评论,你想要在30个单词内总结内容,那么可以给出以下提示:
prompt = f"""
Your task is to generate a short summary of a product \
review from an ecommerce site.
Summarize the review below, delimited by triple
backticks, in at most 30 words.
Review: ```{review}```
"""
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
)同样地,如果你有一些文本,你可以在提示符中简单地询问“下面的产品评论的情感是什么,用{你使用的任何分隔符}分隔?”如果我们采取琐碎的方式,我们需要大量的数据,并将它们标记为正面和负面类,然后进行多次训练来建立情感分类器。但是随着LLMs和提示工程的进步,你可以很快地构建这个应用程序。我们还可以使用提示工程开发翻译系统,在那里我们可以要求LLM API生成翻译并在用户所需的格式中返回。这也可以用来构建聊天机器人。我们还可以创建文档简化应用程序等等。
参考:https://www.deeplearning.ai