知识图谱与LLMs:微调与检索增强生成
LLM的限制是什么,如何克服它们?
这是Neo4j NaLLM项目的第二篇博客文章。我们启动这个项目来探索、开发并展示 LLMs 与 Neo4j 的实际应用。作为这个项目的一部分,我们将建立并公开展示在 GitHub 存储库中的演示,为我们的社区提供一个开放空间观察、学习和贡献。此外,我们正在博客文章中记录我们的发现。您可以在此处找到第一篇博客文章。
大语言模型(LLMs)的第一波炒作主要来自ChatGPT和类似的基于Web的聊天机器人,这些模型在理解和生成文本方面非常出色,以至于人们感到震惊,包括我自己在内。
许多人登陆并测试LLM的写作俳句、激励信或电子邮件回复的能力。很快就显而易见,LLM不仅擅长生成创意内容,而且擅长解决典型的自然语言处理和其他任务。
在LLM热潮开始不久,人们开始考虑将其融入他们的应用中。不幸的是,如果您只是在LLM API周围开发一个包装器,那么您的应用程序成功的机会很小,因为它没有提供额外的价值。
一种LLM的主要问题是所谓的知识截断。知识截断术语指的是LLM在培训后不知道发生的任何事件。例如,如果您询问ChatGPT关于2023年的某个事件,您将得到以下回复。
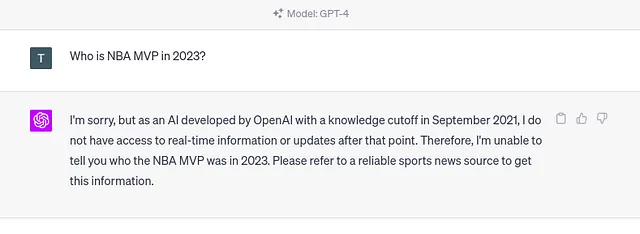
如果您询问LLM有关其培训数据集中不存在的任何事件,同样的问题将会发生。虽然知识截止日期适用于任何公开可用信息,但LLM对于可能早于知识截止日期的私人或机密信息没有任何了解。
例如,大多数公司都有一些机密信息,他们不会公开分享,但可能有兴趣拥有一个定制的LLM来回答这些问题。另一方面,LLM已经知道的很多公开信息可能已经过时了。
因此,更新和扩展LLM知识在今天非常相关。
LLMs存在的另一个问题是它们被训练出产生听起来十分真实的文本,但这些文本可能不准确。有些无效信息比其他信息更加难以发现。特别是对于缺失数据,LLM很有可能会编造一个听起来令人信服但实际上错误的答案,而不是承认自己在培训过程中缺乏基础知识。
例如,研究或法庭引用可能更容易验证。一周前,一名律师因盲目相信 CHATGPT 生成的法庭引用而陷入麻烦。
我还注意到,LLM会始终产生自信的、不正确的关于任何类型的ID,如WikiData或其他的识别号码的信息。

由于ChatGPT的响应很自信,你可能期望它是准确的。然而,所给的WikiData ID指向英格兰的一个农场。因此,你必须非常小心,不要盲目相信LLM所产生的一切。验证答案或从LLM中产生更准确的结果是另一个需要解决的大问题。
当然,LLMs 还有其他问题,如偏见、提示注入等等。但是,我们不会在这里讨论它们。相反,在这篇博客文章中,我们将介绍和专注于微调和检索增强 LLMs 的概念,并评估它们的优点和缺点。
监督微调LLM
解释LLMs的训练超出了此博客文章的范围。相反,您可以观看Andrei Karpathy的这个令人难以置信的视频,了解LLMs的各个阶段和不同的训练方式。
通过微调LLM,我们指的是有监督的训练阶段,您可以提供额外的问题-答案对来优化大型语言模型(LLM)的性能。
此外,我们已经确定了LLM微调的两种不同使用情况。
一个用例是微调模型以更新和扩展其内部知识。相反,另一个用例专注于微调模型以完成特定任务,例如文本摘要或将自然语言翻译成数据库查询。
首先,我们将谈论第一个用例,即使用微调技术来更新和扩展LLM的内部知识。
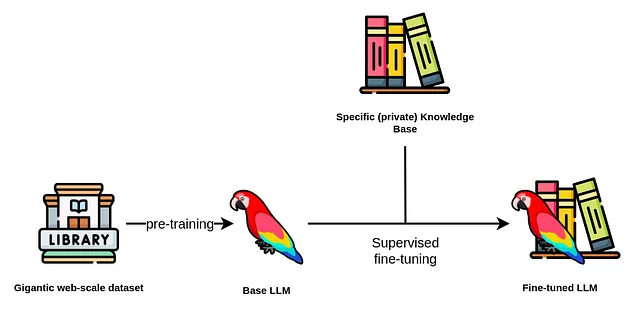
通常情况下,您要避免预训练LLM,因为成本可能高达数十万甚至数百万美元。基本LLM使用一个巨大的文本语料库进行预训练,通常包含数十亿甚至数万亿的标记。
虽然一个LLM的参数数量很重要,但在选择基础LLM时不是唯一要考虑的参数。除了许可证,您还应考虑预训练数据集和基础LLM的偏差和毒性。
选择了基础LLM之后,您可以开始微调。微调步骤相对于计算成本而言比较便宜,因为现有技术如LoRa和QLoRA。
然而,构建训练数据集更为复杂且花费更高。如果您无法承担专门的标注团队,那么使用一个LLM来构建训练数据集以微调您想要的LLM似乎是一个趋势(这真的是元)。
例如,斯坦福大学的羊驼训练数据集是使用OpenAI的LLMs创建的。创建52000个训练指令的成本约为500美元,相对便宜。
另一方面,维库纳模型是通过使用在ShareGPT.com上发布的ChatGPT对话进行微调的。
还有一个由H2O推出的相对新鲜的项目叫做WizardLM,旨在将文档转化为问题与答案对,可用于微调LLM。
我们还没有找到任何最近的文章描述如何使用知识图谱来准备可以用于微调LLM的好问答对。
这是我们计划在NaLLM项目中探索的领域。我们有一些使用LLM从知识图谱上下文构建问答对的想法。
然而,目前仍然有许多未知。例如,您是否可以针对同一个问题提供两个不同的答案,然后LLM将它们以某种方式组合在其内部知识库中?
另一个需要考虑的问题是,知识图谱中的一些信息如果不考虑其关系,就没有意义。因此,我们需要预定义有关的查询,还是有更通用的方法可以处理?能否使用节点-关系-节点模式来表示主语-谓语-宾语表达式以生成相关的对呢?
这些是我们在即将发布的博客文章中打算回答的一些问题。
想象一下,您以某种方式成功地生成了一个培训数据集,其中包含基于您的知识图中存储的信息的问题答案对。因此,LLM现在包括更新的知识。
然而,微调模型并没有解决知识截止问题,因为它只是把知识截止时间推迟到了更晚的日期。
因此,我们建议只使用精细调整技术来更新LLM的内部知识,以适用于变化缓慢或更新的数据。例如,您可以使用经过微调的模型提供旅游信息。
然而,一旦您想在响应中包含特殊的时间相关(实时)或个性化促销,您就会遇到麻烦。同样,Fine-tuned 模型并不适合分析工作流程,例如您想问公司上个星期获得了多少新顾客。
目前,微调方法可以帮助减轻幻觉,但无法完全消除它们。一个问题是LLM在提供答案时没有引用它们的来源。因此,您不知道回答是来自预训练数据、微调数据集还是由LLM编造的。此外,如果您使用LLM创建微调数据集,可能还会有另一个可能的虚假信息源。
最后,一个调整精细的模型不能自动根据提问者提供不同的响应。同样,没有访问限制的概念,这意味着与LLM交互的任何人都可以访问其所有信息。
检索增强生成技术
保持HTML结构,将以下英文文本翻译为简体中文:大型语言模型在自然语言应用中表现出色,例如
- 文本摘要
- 提取相关信息
- 实体消歧
- from one dialect to another, can be challenging. It requires not only a solid grasp of both languages or dialects, but also an understanding of the cultures and contexts in which these languages are used.
- 将自然语言转换为数据库查询或脚本代码。
此外,以往的 NLP 模型大多是特定于领域和任务的,这意味着你最有可能需要根据你的使用情况和领域训练一个定制的自然语言模型。然而,由于 LLMs 具有广泛的泛化能力,一个模型可以被应用于解决各种任务集合。
我们注意到使用检索增强LLMs的趋势相当强烈,其中不是使用LLMs来访问其内部知识,而是将LLM用作与公司或私人信息进行自然语言交互的界面。
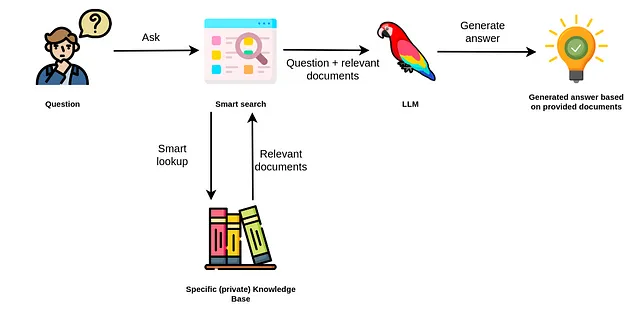
检索增强方法使用LLM根据数据源中提供的相关文档生成答案。
因此,您不依赖于对LLM的内部了解来生成答案。相反,LLM仅用于从您提交的文件中提取相关信息并进行总结。
例如,ChatGPT插件可以被视为增加检索的LLM应用程序的方法。启用浏览插件的ChatGPT界面允许LLM搜索互联网以访问最新信息并用其构建最终答案。
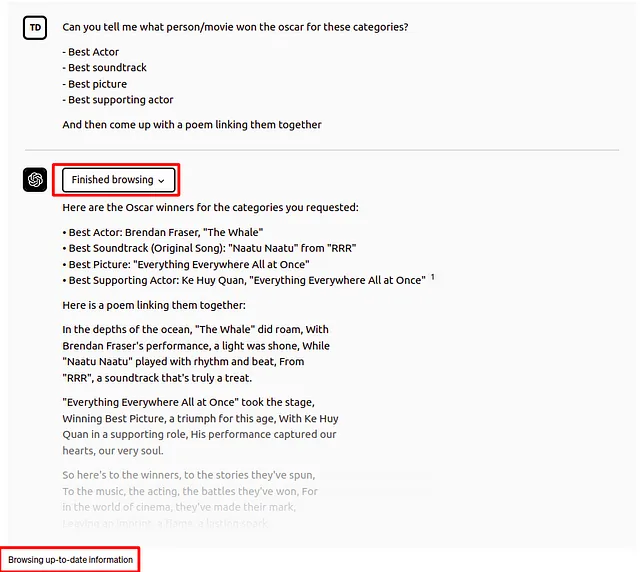
在这个例子中,ChatGPT 能够回答谁赢得了 2023 年各个类别的奥斯卡奖。但是,记住,ChatGPT 的截止知识日期是 2021 年,所以它无法从内部知识了解谁赢得了 2023 年的奥斯卡奖。因此,它通过浏览插件访问外部信息,使其能够用最新信息回答问题。这些插件在 OpenAI 平台内部提供了一个集成的增强机制。
如果你一直在关注LLM领域,可能听说过LangChain图书馆。
LangChain库可以用于让LLM从各种来源(如Google搜索、向量数据库或知识图谱)获取实时信息。例如,LangChain添加了Cypher Search链,将自然语言问题转换为Cypher语句,并使用它从Neo4j数据库中检索信息,并根据提供的信息构建最终答案。
使用Cypher搜索链,LLM不仅用于构建最终答案,还用于将自然语言问题翻译成Cypher查询。
另一个用于检索增强LLM工作流的流行库是LlamaIndex(GPT Index)。LlamaIndex是一个全面的数据框架,旨在通过使其能够利用私有或自定义数据来提高大型语言模型(LLMs)的性能。
首先,LlamaIndex提供数据连接器,方便摄取各种数据源和格式,包括API、PDF和文档、SQL或图形数据等。
此功能允许将现有数据轻松集成到LLM中。其次,它提供了有效的机制来使用索引和图表来结构化摄入的数据,确保数据适合用于LLM。此外,它还包括先进的检索和查询界面,使用户能够输入LLM提示并收到上下文检索、知识增强的输出。
检索增强型LLM应用程序(例如ChatGPT插件和LangChain)背后的思想是避免仅依赖内部LLM知识生成答案。相反,LLM被用于解决任务,如从自然语言构建数据库查询以及根据外部提供的信息或利用检索插件/代理构建答案。
检索增强方法相比微调方法具有一些明显的优势:
- 答案可以引用其信息来源,这使您可以验证信息并根据要求潜在地更改或更新基础信息。
- 幻觉不太可能发生,因为您不依赖LLM的内部知识来回答问题,而只使用相关文件中提供的信息。
- 将LLM使用的基础信息更改,更新和维护变得更容易,因为您将问题从LLM维护问题转变为数据库维护,查询和上下文构建问题。
- 答案可以根据用户的上下文或其访问权限进行个性化定制。
另一方面,在使用检索增强方法时,您应考虑以下限制:
- 答案只取决于智能搜索工具的好坏
- 该应用程序需要访问您特定的知识库,可以是数据库或其他数据存储设备。
- 完全忽略语言模型的内部知识会限制可以回答的问题数量。
- 有时LLMs不遵循说明,所以如果上下文中没有找到相关的答案数据,就有忽视上下文或产生幻觉的风险。
摘要
GPT-3, and the potential drawbacks of their widespread use. Specifically, LLMs are criticized for perpetuating societal biases, being prone to generating fake news and misinformation, and exacerbating the digital divide by further empowering tech giants. While LLMs have shown impressive advancements in natural language processing, it is important to carefully consider their impact on our society and mitigate their potential negative effects.
- 知识截止。
- 幻觉,和
- 用户定制的缺乏。
为了克服这些问题,我们探讨了两个概念,即微调和检索增强的LLMs使用。
调整 LLM 的过程中包括监督训练阶段,提供问题和答案对以优化 LLM 的性能。这可以用于更新和扩展 LLM 的内部知识或将其微调为特定任务。然而,微调无法解决知识截止问题,因为它只是将截止日期推迟。它也无法完全消除幻觉。因此,我们建议在缓慢变化的数据集中使用微调方法,允许一些幻觉发生。由于微调 LLM 相对较新,我们渴望了解更多关于微调方法和最佳实践。
第二种克服LLMs局限性的方法是所谓的检索增强生成,其中LLM作为自然语言接口用于访问外部信息,因此不仅依靠其内部知识来生成答案。检索增强方法的优点包括源引用、可忽略的幻觉、易于更改和更新信息、以及个性化。然而,它严重依赖于智能搜索工具来检索相关信息,并需要访问用户的知识库。此外,它只能回答提供所需信息的查询。
随着项目的发展,我们团队将会通过GitHub库公开记录所有最新进展,请持续关注。
/ Neo4j NaLLM 项目核心团队:Jon Harris、Noah Mayerhofer、Oskar Hane、Tomaz Bratanic