? 使用Python利用OpenAI的API构建基于嵌入式的文档问答式简单智能聊天机器人。
导言 ?
聊天机器人已成为许多应用程序的不可或缺的一部分,为用户提供即时和准确的答案。在本文中,我们将探讨如何利用OpenAI的API构建一个定制的聊天机器人,使用基于文档的问答技术提供智能答案,给出一个非常简单的例子。
在本教程中,我们希望ChatGPT api根据我们的文档回答我们的问题。
如果你的文件很小,比如说只有几百个单词,你可以简单地向 OpenAI 发送提示并获取一个答案。
I have a document below. I want you to answer my question using it.
Document: bla bla bla ...
My Question is: How can I do this and that?但是,如果你有一份有成千上万页的文档,你将会受到 OpenAI 的令牌限制,这个限制是 4097。 (你可以把令牌看作是单词。此外,OpenAPI 的定价是基于令牌的。详情请见 https://platform.openai.com/tokenizer)
为了处理成千上万的页面,我们将使用嵌入 API。
不再拖延,我们开始吧!
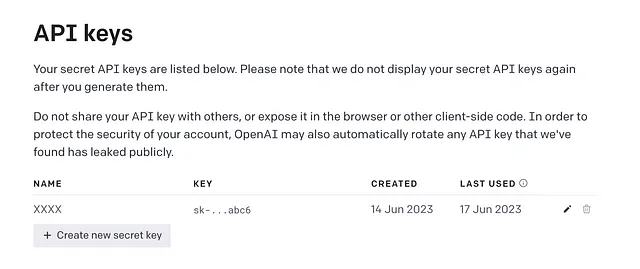
1. 创建 OpenAI API 密钥?
在开始之前,如果您没有API密钥,您应该从https://platform.openai.com/account/api-keys创建它。
通过点击“创建新的密钥”,您将获得您的 API 密钥。
2. 准备测试环境 ?️
为了方便测试,您可以使用Google Colab。只需要访问https://colab.research.google.com并点击“新笔记本”。
如果您想检查所有的代码,请访问:https://colab.research.google.com/drive/1Rotno5aIb0Mjditom1Vlw1e67cL7oQn7?usp=sharing
保留HTML结构,将以下英文文本翻译成简体中文: 或
Translation Example
Here is some English text that we would like to translate to simplified Chinese:
"Hello, my name is John. I am from the United States and I like to play basketball."
After translation, it should look like this:
你好,我叫约翰。我来自美国,喜欢打篮球。
2.1 我们需要先安装所需的库?。
我们需要numpy来计算向量相似度。
pip install numpy
pip install openai2.2 导入库并设置openAI API密钥 ?
唯一重要的事情是您应该首先设置您的 API 密钥,然后导入 OpenAPI 库。导入 OpenAPI 库时,OpenAPI 库会检查 API 密钥。
import os
os.environ["OPENAI_API_KEY"] = "sk-abc123abc123abc123abc123abc123abc123abc123abc123"
import openai
import numpy as np3. 获取向量?
什么是向量?基本上,你可以把向量看作是你提供的文本的数值表示。因此,如果你想比较两个文本是否相似,你可以使用它们的向量。
我们应该将文档分成几个部分。每个部分应不超过200个单词(约2000个标记)。为了简便起见,我将文档分成了2个部分。
总之,向量由数字列表组成:[0.0051739453338086605,0.001334857544861734,0.041553668677806854,-0.02944961003959179,0.012239149771630764,…
document1="""A personal cloud is an approach to cloud computing for individuals, a shift away from the dominant model of cloud computing today on “the public cloud”. To appreciate the difference, let’s look at how an application differs in each model. Public cloud application model The “public cloud” application model is visible in the relationships between users, an application, and infrastructure in a “public cloud” app: In this model, all end users interact share the same “app”, which consists of a large block of ‘computing’ resources in the cloud: servers, databases, and more. They interact with this block by logging in to the application via the internet, and the application gives them selective access to views and data they are authorized to interact with. These individual users don’t have direct access to the cloud provider and resources that power the application - even if it’s their specific data. These resources are controlled and managed by the companies that build the application, which serve as an intermediary (they are also the cloud provider’s customers). Personal cloud application model
The “personal cloud” application model is a return to the personal computer model, but in the cloud. In this model, the relationships between users, applications, and infrastructure change: In this model, apps aren’t made up of one giant shared pool of resources for all users. Instead, each user gets their own separate copy of each app, in their own cloud. The computing resources that power the application are managed and controlled by the end user, who logs in to their cloud directly.
One person, many applications
Now let’s jump out of our simple model. Individuals don’t use single applications on the internet — they use many. As we expand the above model to cover a person using multiple applications on the internet, we’ll see new possibilities emerge.
For each app a person uses on the internet, they log in separately to use them (on a personal computer, you log in once). And in doing so, the previous model applies (each app is shared across all users, users don’t have access to the underlying resources, etc). Each app is, for all intents and purposes, separate: they live with different companies, they have different interfaces, and they do not communicate.
In a personal cloud, this dynamic changes. Not only do people get a personal copies of each app, but they can get many personal copies of many apps. Because these apps live on the same “computer”, it becomes easier for the user to start directing interactions across these applications and their data.
This is akin to personal computer, where there is a user, a pool of data, and many applications that all work in concert to achieve the user’s objectives. """
document2="""Cloud computing, designed for people. The internet transformed personal computers into personal gateways for global communication and interaction with other humans and machines. However, while many applications on the internet are designed with the user in mind, the overall experience of using a computer on the internet is not. People have lost autonomy and control over their data and must navigate a multitude of incompatible apps that don’t work in concert for them.
We believe that designing computers around people provides a better experience. The personal cloud aims to achieve this goal for computers on the internet, by prioritizing the individual user as the ultimate design constraint, as opposed to an enterprise or individual application.
A personal cloud is distinct from traditional personal computers because it exists online. It provides a private and autonomous space to use your apps and manage your data, while also serving as a personal portal to and from the world. It can act as a launchpad for interactions between your inspirations & creations, and the vast universe of humans and machines on the internet.
Discover something wonderful, make it yours, and explore what’s next.
For users
In the traditional cloud model, the company who provides an application holds a lot of power. If the company decides it’s not worth it to keep the app running and shuts down the infrastructure, happy users lose access. They also can’t easily interact with, extend, or delete their own application data. Or add a custom domain, or more RAM to a sluggish service.
On the personal cloud, this all changes. Users can install and uninstall apps on a whim, with fine-grained control. They can inspect, modify, extend, and export all their data. Since everything is in one place, it can integrate directly. For users who are also developers, the control is extremely powerful: everything is raw material to build and explore with.
For developers
Using the cloud providers of today, web developers with an idea need to do a lot to bring it to the world. They have to code their idea, but they also have to create, pay for, and operate the infrastructure to run it. This is a lot of work. For apps to serve users around the globe, this barrier usually requires teams of operational experts fighting a crazy number of cloud tools.
Using the personal cloud, things are entirely different. Individuals can build something for themselves, assuming they’re the only user. They can stop there, if they want. Or they can publish it to the world, and see it run everywhere. Anyone else with an internet connection can install the app, in another personal cloud. Throughout the entire process, the developer doesn’t think about operating anything ✨ at all ✨.
"""
document1_vector=openai.Embedding.create(
input=document1,
model="text-embedding-ada-002"
)['data'][0]['embedding']
document2_vector=openai.Embedding.create(
input=document2 ,
model="text-embedding-ada-002"
)['data'][0]['embedding']4. 获取问题的向量,检查哪个文档相关性最高,然后发送提示 ?。
在上一部分中,我们得到了文档部分的向量。现在,当我们想回答一个问题时,我们也应该将问题向量化并比较问题的向量。通过获取问题的向量,我们可以轻松计算哪一部分与我们的问题相关。
def answer_question(question):
question_vector=openai.Embedding.create(
input=question ,
model="text-embedding-ada-002"
)['data'][0]['embedding']
document1_similarity_score = np.dot(question_vector, document1_vector)
document2_similarity_score = np.dot(question_vector, document2_vector)
# if similarity of the parts are very low, this means the question is not relevant with the document
if(document1_similarity_score<0.79 and document2_similarity_score<0.79):
print("we couldn't find a related part in the document")
return
if(document1_similarity_score>document2_similarity_score):
print("First part in the document found related")
related_document=document1
else:
print("Second part in the document found related")
related_document=document2
prompt=f"""I have a document below. I want you to answer my question using it.
Document: {related_document}
My Question is: {question}
"""
prompt_answer_response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=1,
max_tokens=2000,
)
if(prompt_answer_response['choices']==[]):
print("We couldn't find any answer for the question")
return
print("Answer to your Question:")
print()
print(prompt_answer_response['choices'][0]['text'])
print()5. 测试我们的函数 ?
现在我们可以提出一些问题并得到答案。
answer_question("What is the personal cloud model?")
"""
Output:
First part in the document found related
Answer to your Question:
Answer: The personal cloud model is an approach to cloud computing for individuals, where each user gets their own separate copy of each application, in their own cloud. Computing resources that power the application are managed and controlled by the end user, who logs in to their cloud directly. It is akin to a personal computer, where there is a user, a pool of data, and many applications that all work in concert to achieve the user’s objectives.
"""
answer_question("Why I should use Personal Cloud?")
"""
Second part in the document found related
Answer to your Question:
You should use Personal Cloud because it provides an autonomous and private space to use your apps and manage your data, while also serving as a personal portal to and from the world. You have control over your data and apps and it eliminates the need for operational experts with its ease of use. Furthermore, it allows both users and developers to build and explore with their own ideas in a simplified and user-friendly way.
"""
6. 结论?
如果您想要简单的文章,请在评论中写出下一个主题?。
协作链接:
点击此处以访问链接。
Github代码片段链接:
欢迎来到我的页面
我很高兴能与你分享我的内容。
我的爱好
- 阅读
- 旅游
- 摄影
我的家乡
我来自中国,一个美丽的国家,有着悠久的历史和多样的文化。
如果你有机会来我的家乡旅游,一定不要错过以下景点:
- 长城
- 故宫博物院
- 秦始皇兵马俑